Blog Posts in August 2010
BGP: time to grow up
If you’re in the Service Provider business, this is (hopefully) old news: on Friday, RIPE decided to experiment with the Internet causing routers running IOS-XR to hiccup. They stopped the experiment in less than half an hour and only 2% of the Internet was affected according to Renesys analysis (a nice side effect: Tassos had great fun decoding the offending BGP attribute from hex dumps).
My first gut reaction was “something’s doesn’t feel right”. A BGP bug in IOS-XR affects only 2% of the Internet? Here are some possible conclusions:
Multihop FCoE 101
The FCoE confusion spread by networking vendors has reached new heights with contradictory claims that you need TRILL to run multihop FCoE (or maybe you don’t) and that you don’t need congestion control specified in 802.1Qau standard (or maybe you do). Allow me to add to your confusion: they are all correct ... depending on how you implement FCoE.
Interesting links (2010-08-29)
In his HSRP, vPC and the vPC peer-gateway command post Jeremy Filliben documents how the storage vendors ignore RFCs and implement what they think is proper ARP handling, causing havoc in a redundant network.
Andrew Vonnagy writes about another extreme stupidity customer convenience Microsoft managed to implement: you can turn any Windows 7 into a rogue Access Point. Like we didn’t have enough problems already.
And then there’s Charles Stross, taking the “where we went wrong” rants observations to a completely new level. While I’m complaining about lack of session layer in TCP/IP and broken socket API, he’s taking on Von Neumann architecture.
Storage networking is different
The storage industry has a very specific view of the networking protocols – they expect the network to be extremely reliable, either by making it lossless or by using a transport protocol (TCP + embedded iSCSI checksums) that was only recently made decently fast.
Some of their behavior can be easily attributed to network-blindness and attempts to support legacy protocols that were designed for a completely different environment 25 years ago, but we also have to admit that the server-to-storage sessions are way more critical than the user-to-server application sessions.
FCoE and DCB standards
The debate whether the DCB standards are complete or not and thus whether FCoE is a standard-based technology are entering the metaphysical space (just a few more blog posts and they will join the eternal angels-on-a-hairpin problem), but somehow the vendors are not yet talking about the real issues: when will we see the standards implemented in shipping products and will there be a need to upgrade the hardware.
Read more ... (yet again @ etherealmind.com)
Tweak the Search Engine rankings to push IPv6
We all know that IPv6 deployment is a chicken-and-egg problem: Service Providers are slow to adopt IPv6 because they can’t charge for it and the content providers don’t care because there are no IPv6 customers.
My good friend Jan Žorž got a great idea during the Google IPv6 Implementers Conference and finally managed to write it down: all we need is a slight search engine preference for sites reachable over IPv4 and IPv6. A small well-publicized tweak in Google’s scoring algorithm would push the content providers toward IPv6 and force web hosting companies to roll out IPv6 support immediately.
Interesting links (2010-08-21)
Two interesting QoS-focused posts from last week: Brad Hedlund was explaining the difference between UCS and HP Virtual Connect QoS (short summary: one does queuing, the other one rate-limiting) and Russell Heilling nicely described the QoS problems encountered in a Service Provider network (he’s coming to the same conclusion as I did: we need per-user queuing, but describes it way more eloquently).
After I’d stumbled upon Russell’s blog, I started reading his older posts and found a nice in-depth explanation of one potential road to Net Neutrality hell paved with good intentions.
And, in a blitz of late news, ATAoE has resurrected like Phoenix from its ashes.
More IPv6 FUD being thrown @ CFOs
The CFO magazine has recently published a FUDful article “Trouble Looms for Company Websites” (read it to see what CFOs have to deal with). Obviously, some people think it’s a good idea to throw FUD at CFOs to get the budget to implement IPv6. Long term, it’s a losing strategy; your CFO will become immune to anything coming from the IT department and ignore the real warnings.
Yes, it's time to make your content reachable over IPv4 and IPv6, more so if you’re in the eyeballs business. Google knows that. So does Facebook. Twitter doesn’t seem to care. Maybe because they’re not selling ads?
I Don’t Need no Stinking Firewall ... or Do I?
Brian Johnson started a lively “I don’t need no stinking firewall” discussion on NANOG mailing list in January 2010. I wanted to write about the topic then, but somehow the post slipped through the cracks… and I’m glad it did, as I’ve learned a few things in the meantime, including the (now obvious) fact that no two data centers are equal (the original debate had to do with protecting servers in large-scale data center).
First let’s rephrase the provocative headline from the discussion. The real question is: do I need a stateful firewall or is a stateless one enough?
Port or Fabric Extenders?
Among other topics discussed during the Big Hot and Heavy Switches (Part 1) podcast (if you haven’t listened to it yet, it’s high time you do), we’ve mentioned port extenders. As our virtual whiteboard is not always clearly visible during the podcast (although we scribble heavily on it), here’s the big-picture architecture:
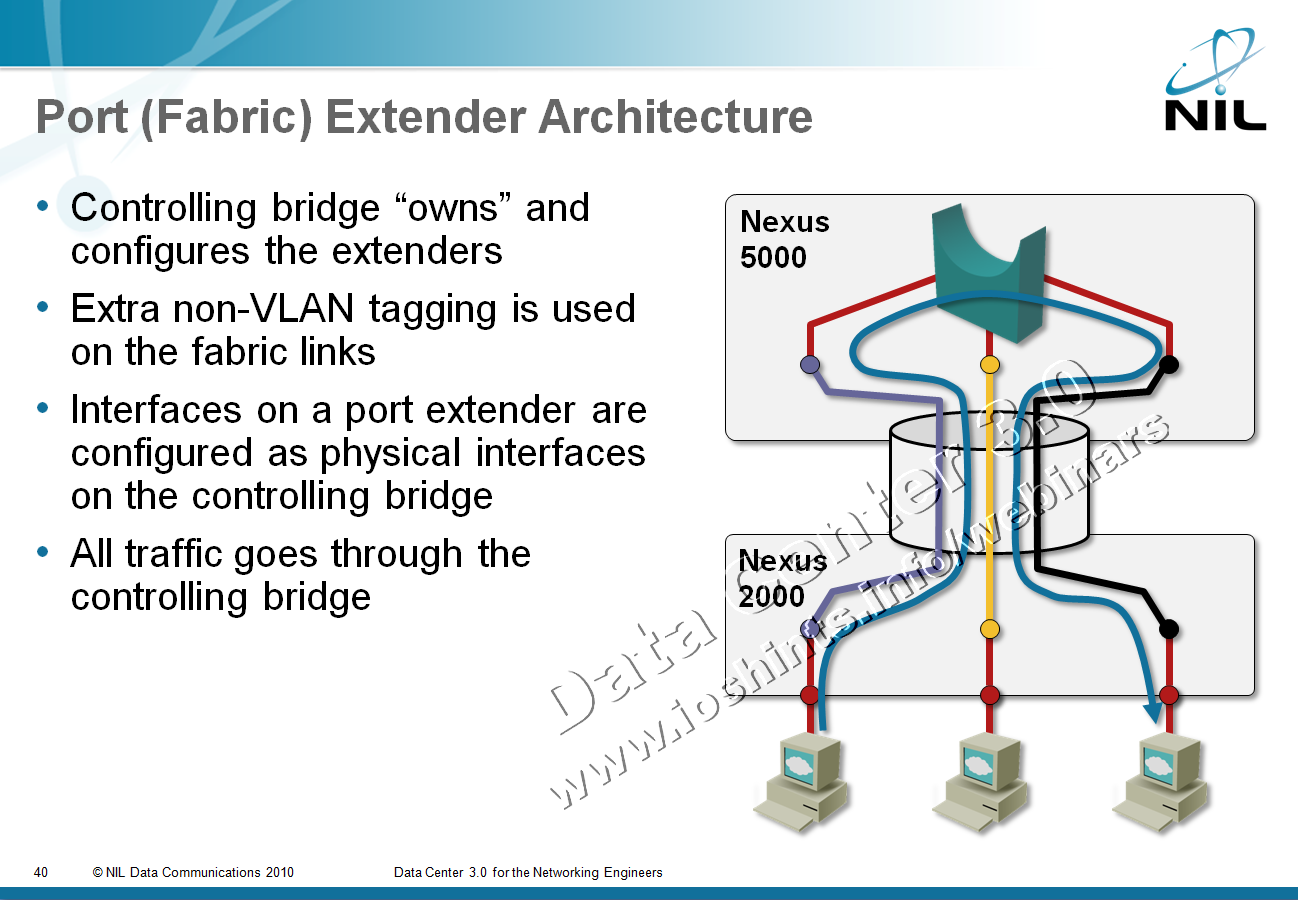
After the podcast I wanted to dig into a few minor technical details and stumbled into a veritable confusopoly.
Packet Filters on a Nexus 7000
We’re always quick to criticize ... and usually quiet when we should praise. I’d like to fix one of my omissions: a few days ago I was trying to figure out whether Nexus 7000 supports IPv6 access lists (one of the presentations I was looking at while researching the details for my upcoming Data Center webinar implied there might be a problem) and was pleasantly surprised by the breadth of packet filters offered on this platform. Let’s start with a diagram.
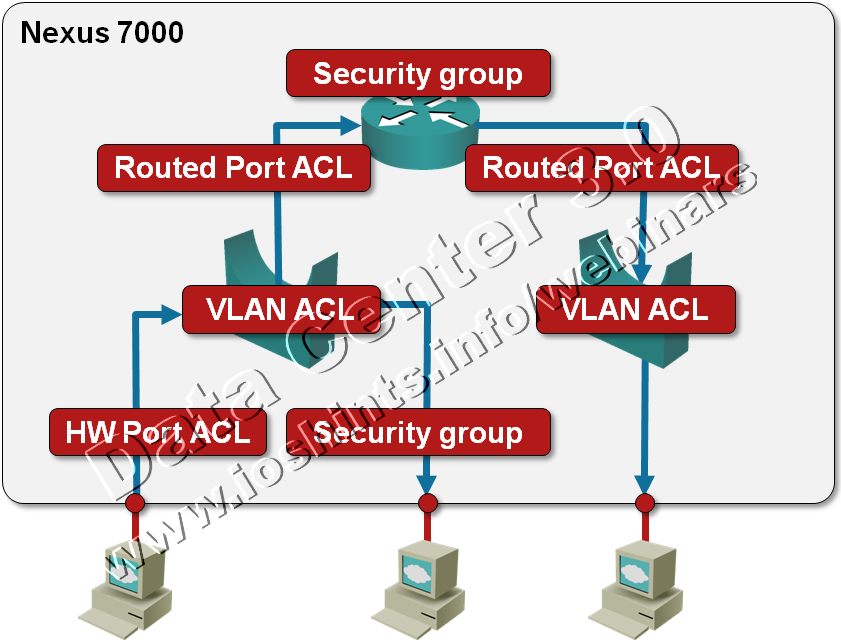
WAF musings ... not again?
Following my obituary for Cisco’s WAF, Packet Pushers did a really great WAF-focused podcast with Raven Alder, appropriately named Saving the Web with Dinky Putt Putt Firewalls. If you have more than a fleeting interest in protecting business web applications, you should definitely listen to it. Just as an aside: when they were recording the podcast, I was writing my To WAF or not to WAF post ... and it’s nice to see we’re closely aligned on most points.
There’s just a bit I’d like to add to their ponderings. What Raven describes is the “proper” (arduous, time-consuming and labor-intensive) use of WAF that we’re used to from the layer-3/4 firewalls: learning what your web application does (learning because the design specs were never updated to reflect reality) and then applying the knowledge to filter everything else (what I sometimes call the fascist mode – whatever is not explicitly permitted is dropped).
Interesting links (2010-08-14)
A few days ago I wrote that you should always strive to understand the technologies beyond the reach of your current job. Stephen Foskett is an amazing example to follow: although he’s a storage guru, he knows way more about HTTP than most web developers and details of the web server architecture that most server administrators are not aware of. Read his High-Performance, Low-Memory Apache/PHP Virtual Private Server; you’ll definitely enjoy the details.
And then there’s the ultimate weekend fun: reading Greg’s perspectives on storage and FCoE. It starts with his Magic of FCoTR post (forget the FCoTR joke and focus on the futility of lossless layer-2 networks) and continues with Rivka’s hilarious report on the FCoTR progress. Oh, and just in case you never knew what TR was all about – it was “somewhat” different, but never lossless, so it would be as bad a choice for FC as Ethernet is.
Last but not least, there’s Kevin Bovis, the veritable fountain of common sense, this time delving with the ancient and noble art of troubleshooting. A refreshing must-read.
Deploying IPv6 article @ SearchTelecom
Following my “Transition to IPv6” articles, Jessica Scarpati from SearchTelecom.com wrote a series of articles covering the telecom transition plans and the problems they’re experiencing with the vendors and content providers.
In the second article of the series, “Deploying IPv6? Demand responsiveness from vendors, content providers”, she’s quoting John Jason Brzozowski from Comcast, John Curran from ARIN, Matt Sewell from Global Crossing and myself. My key message: vote with your money and take your business elsewhere if the vendors don’t get their act together.
Vendor performance tests

Any comment would be superfluous.
To WAF or not to WAF?
Extremely valid comment made by Pavel Skovajsa in response to my “Rest in peace, my WAF friend” post beautifully illustrates the compartmentalized state some IT organizations face; before going there, let’s start with the basic questions.
Do we need WAF ... as a function, not as a box or a specific product? It’s the same question as “do we need virus scanners” or “do we need firewalls” in a different disguise. In an ideal world where all the developers would be security-conscious and there would be no bugs, the answer is “NO”. As we all know, we’re in a different dimension and getting further away from the heavens every time someone utters “just good enough” phrase or any other such bingo-winning slogan.
It’s popular to bash IT vendors’ lack of security awareness (Microsoft comes to mind immediately), but they’re still far ahead of a typical web application developer. At least they get huge exposure, which forces them to implement security frameworks.
Interesting links (2010-08-08)
Several interesting blog posts I’ve stumbled upon in the last few days:
Should developers have access to production? A really good analysis of pros and cons (including a pinch of “this is how it’s always been done”).
Migrating from Catalyst to Nexus. As usual, there are hidden gotchas and varying default settings that make the migration more interesting than expected.
Justifying VDI. VMware has decided to deploy virtual desktops; they describe what they’ve learnt and how you should approach VDI projects.
How many large-scale bridging standards do we need?
Someone had a “borderless data center mobility” dream a few years ago and managed to infect a few other people, resulting in a networking industry pandemic that is usually exhibited by the following “facts”:
- Unhindered Virtual Machine mobility across the globe is the absolute prerequisite for any business agility. Wrong. There are other field-proven solutions and although inter-site VM mobility has been demonstrated, it’s still a half-baked idea and has many caveats.
- You can only reach that Holy Grail by extending your layer-2 domains across vast distances. Totally wrong. It would be easier to fix L3 routing and signaling protocols than to invent completely new technologies trying to fix L2 problems. Users of Microsoft NLB are might disagree ... in which case I wish them luck in scaling their architecture.
- Large-scale bridging is absolutely mandatory if you want to build cloud solutions with tens of thousands of servers. Not sure about that. Google is there, Facebook, Twitter and Amazon are (at least) close, large web hosting providers have been around for years ... and yet they somehow managed to survive with existing technologies and good network designs.
Just today XKCD published a very relevant comic, so I can skip my usually sarcastic comments and focus on the plethora of emerging large-scale bridging standards and implementations. Let’s walk through them:
Look beyond your cubicle
The Packet Pushers Episode 11 (If You Can’t Be Replaced, You Can’t Be Promoted) contains numerous highly valuable career advices. I won’t spoil the fun by telling you what they are (listen to the podcast if you haven’t done so already); I’ll just add one to their long list: always look beyond what you’re doing at the moment. For example, a networking engineer working anywhere near a Data Center environment should be very familiar with the server and storage technologies.
Read more ... (this time @ etherealmind.com)
Rest in peace, my WAF friend
A few years ago, Cisco bought a company that made application-level firewalls, first an XML-focused product (XML Gateway) that was also able to verify your XML data, later a Web Application Firewall (WAF), which was effectively the XML product with half of the brains ripped out.
I was really looking forward to these products. Layer-3 firewalls cannot protect web sites against application-layer problems like SQL injections or cross-site scripting, so we definitely need something on the application layer and the WAF (and XML Gateway) ran as virtual appliance in VMware, making them ideal for my lab environment. I quickly lost interest after the first cursory contact with the XML Gateway as you could only manage both products with a web-based GUI (and I definitely don’t want to publish blog posts full of screenshots).
EIGRP Myths Debunked
Matthew Norwood performed a really thorough EIGRP research and unearthed a lot of myths around it, some of them coming from official documentation, Cisco Press books (hopefully not mine) and other sources. It’s time to debunk a few of them.
EIGRP is a hybrid routing protocol. If I remember correctly, this one comes straight from the first EIGRP presentations Dino had @ Networkers years ago and is usually interpreted as “EIGRP has the best features of Distance Vector and Link State routing protocols”. Completely wrong, EIGRP has zero LS features. Correct classification would be “EIGRP is an advanced Distance Vector routing protocol” and the Wikipedia entry on EIGRP is almost spot-on.
TRILL and 802.1aq are like apples and oranges
A comment by Brad Hedlund has sent me studying the differences between TRILL and 802.1aq and one of the first articles I’ve stumbled upon was a nice overview which claimed that the protocols are very similar (as they both use IS-IS to select shortest path across the network). After studying whatever sparse information there is on 802.1aq and the obligatory headache, I’ve figured out that the two proposals have completely different forwarding paradigms. To claim they’re similar is the same as saying DECnet phase V and MPLS Traffic Engineering are similar because they both use IS-IS.
Interesting links (2010-08-01)
Some of the interesting things I’ve stumbled across lately (mostly thanks to my Twitter friends):
Sorcerer's Apprentice Syndrome: this is what happens to sloppily designed protocols. Interestingly, my Msc thesis was a purely academic approach to testing protocol correctness. I decided to use X.25 as the example (and of course it worked); this one would be really fun.
Do Not Social Engineer Yourself out of Clients or your Job! If you’re Twitter happy and think it’s a good idea to pollute everyone’s feed with your locations (are you listening @icemarkom?) think twice – you could actually leak sensitive client information.
KPN to stop offering 'free' mobiles. This one is a year old and it took me a while to dig it out. A no-nonsense approach to loss-making residential customers that I will not comment; I can live without yet another shill label for a few days.