Blog Posts in August 2024
Worth Exploring: Open-Source Network Automation Labs
Urs Baumann loves hands-on teaching and created tons of lab exercises to support his Infrastructure-as-Code automation course.
During the summer, he published some of them in a collection of GitHub repositories and made them work in GitHub Codespaces. An amazing idea well worth exploring!
Common Services VRF with EVPN Control Plane
After discovering that some EVPN implementations support multiple transit VNI values in a single VRF, I had to check whether I could implement a common services L3VPN with EVPN.
TL&DR: It works (on Arista cEOS)1.
Here are the relevant parts of a netlab lab topology I used in my test (you can find the complete lab topology in netlab-examples GitHub repository):
Multivendor EVPN Just Works
Shipping netlab release 1.9.0 included running 36 hours of integration tests, including fifteen VXLAN/EVPN tests covering:
- Bridging multiple VLANs
- Asymmetric IRB, symmetric IRB, central routing, and running OSPF within an IRB VRF.
- Layer-3 only VPN, including routing protocols (OSPF and BGP) between PE-router and CE-routers
- All designs evangelized by the vendors: IBGP+OSPF, EBGP-only (including reusing BGP AS number on leaves), EBGP over the interface (unnumbered) BGP sessions, IBGP-over-EBGP, and EBGP-over-EBGP.
All tests included one or two devices under test and one or more FRR containers1 running EVPN/VXLAN with the devices under test. The results were phenomenal; apart from a few exceptions, everything Just Worked™️.
Repost: The Benefits of SRv6
I love bashing SRv6, so it’s only fair to post a (technical) counterview, this time coming as a comment from Henk Smit.
There are several benefits of SRv6 that I’ve heard of.
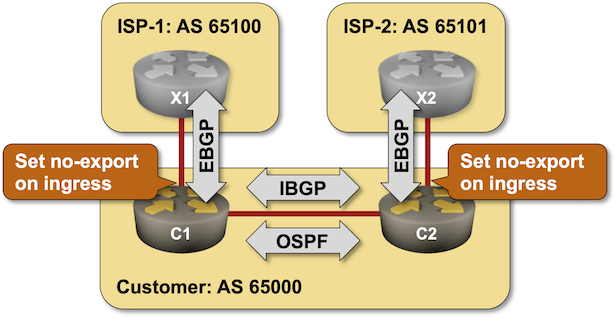
Using No-Export Community to Filter Transit Routes
The very first BGP Communities RFC included an interesting idea: let’s tag paths we don’t want to propagate to other autonomous systems. For example, the prefixes received from one upstream ISP should not be propagated to another upstream ISP (sadly, things don’t work that way in reality).
Want to try out that concept? Start the Using No-Export Community to Filter Transit Routes lab in GitHub Codespaces.
Using Multiple Transit VNIs per EVPN VRF
After reading the Layer-3-Only EVPN: Behind the Scenes blog post, one might come to an obvious conclusion: the per-VRF EVPN transit VNI must match across all PE devices forwarding traffic for that VRF.
Interestingly, at least some EVPN implementations handle multiple VNIs per VRF without a hitch; I ran my tests in a lab where three switches used unique per-switch VNI for a common VRF.
Testing bgpipe with netlab
Ever since Pawel Foremski talked about BGP Pipe @ RIPE88 meeting, I wanted to kick its tires in netlab. BGP Pipe is a Go executable that runs under Linux (but also FreeBSD or MacOS), so I could add a Linux VM (or container) to a netlab topology and install the software after the lab has been started. However, I wanted to have the BGP neighbor configured on the other side of the link (on the device talking with the BGP Pipe daemon).
I could solve the problem in a few ways:
netlab 1.9.0: Routing Policies, Default Routes, Route Redistribution
netlab release 1.9.0 brings tons of new routing features:
- Generic Routing Configuration Module implements routing policies (route maps), prefix filters, AS-path filters, and BGP community filters.
- Default route origination in OSPFv2 and OSPFv3
- Route import (redistribution) into OSPFv2, OSPFv3, and BGP.
- Named prefixes
Other new goodies include:
BGP Session and Address Family Parameters
As I was doing the final integration tests for netlab release 1.9.0, I stumbled upon a fascinating BGP configuration quirk: where do you configure the allowas-in parameter and why?
A Bit of Theory
BGP runs over TCP, and all parameters related to the TCP session are configured for a BGP neighbor (IPv4 or IPv6 address). That includes the source interface, local AS number (it’s advertised in the per-session OPEN message that negotiates the address families), MD5 password (it uses MD5 checksum of TCP packets), GTSM (it uses the IP TTL field), or EBGP multihop (it increases the IP TTL field).
Arista cEOS Got Working MPLS Data Plane
Urs Baumann brought me a nice surprise last weekend. He opened a GitHub issue saying, “MPLS works on Arista cEOS containers in release 4.31.2F” and asking whether we could enable netlab to configure MPLS on cEOS containers.
After a few configuration tweaks and a batch of integration tests later, I had the results: everything worked. You can use MPLS on Arista cEOS with netlab release 1.9.0 (right now @ 1.9.0-dev2), and I’ll be able to create MPLS labs running in GitHub Codespaces in the not-too-distant future.
Layer-3-Only EVPN: Behind the Scenes
In the previous blog post, I described how to build a lab to explore the layer-3-only EVPN design and asked you to do that and figure out what’s going on behind the scenes. If you didn’t find time for that, let’s do it together in this blog post. To keep it reasonably short, we’ll focus on the EVPN control plane and leave the exploration of the data-plane data structures for another blog post.
The most important thing to understand when analyzing a layer-3-only EVPN/VXLAN network is that the data plane looks like a VRF-lite design: each VRF uses a hidden VLAN (implemented with VXLAN) as the transport VLAN between the PE devices.
Response: The Usability of VXLAN
Wes made an interesting comment to the Migrating a Data Center Fabric to VXLAN blog post:
The benefit of VXLAN is mostly scalability, so if your enterprise network is not scaling… just don’t. The migration path from VLANs is to just keep using VLANs. The (vendor-driven) networking industry has a huge blind spot about this.
Paraphrasing the famous Dinesh Dutt’s Autocon1 remark: I couldn’t disagree with you more.
Building Layer-3-Only EVPN Lab
A few weeks ago, Roman Dodin mentioned layer-3-only EVPNs: a layer-3 VPN design with no stretched VLANs in which EVPN is used to transport VRF IP prefixes.
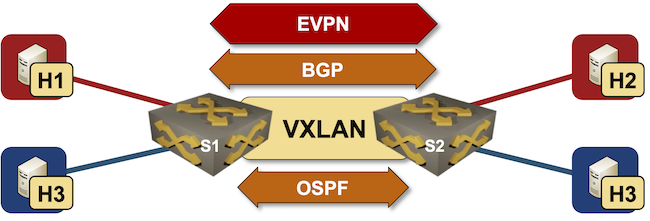
The reality is a bit muddier (in the VXLAN world) as we still need transit VLANs and router MAC addresses; the best way to explore what’s going on behind the scenes is to build a simple lab.
Migrating a Data Center Fabric to VXLAN
Darko Petrovic made an excellent remark on one of my LinkedIn posts:
The majority of the networks running now in the Enterprise are on traditional VLANs, and the migration paths are limited. Really limited. How will a business transition from traditional to whatever is next?
The only sane choice I found so far in the data center environment (and I know it has been embraced by many organizations facing that conundrum) is to build a parallel fabric (preferably when the organization is doing a server refresh) and connect the new fabric with the old one with a layer-3 link (in the ideal world) or an MLAG link bundle.