Blog Posts in February 2011
Traffic Trombone (what it is and how you get them)
Every so often I get a question “what exactly is a traffic trombone/tromboning”. Here’s my attempt at a semi-formal definition.
Traffic trombone is a term (probably invented by Greg Ferro) that colorfully describes inter-VLAN traffic flows in a network with stretched (usually overlapping) L2 domains.
In a traditional L2/L3 data center architecture with small L2 domains in the access layer and L3 forwarding across the core network, the inter-subnet traffic flows were close to optimal: a host would send a packet toward the first-hop (ingress) router (across a bridged L2 subnet), the ingress router would forward the packet across an optimal path toward the egress router, and the egress router would deliver the packet (yet again, across a bridged L2 subnet) to the destination host.
What exactly makes something “mission critical”?
Pete Welcher wrote an excellent Data Center L2 Interconnect and Failover article with a great analogy: he compares layer-2 data center interconnect to beer (one might be a good thing, but it rarely stops there). He also raised an extremely good point: while it makes sense to promote load balancers and scale-out architectures, many existing applications will never run on more than a single server (sometimes using embedded database like SQL Express).
L2 DCI with MLAG over VPLS transport?
One of the answers I got to my “How would you use VPLS transport in L2 DCI” question was also “Can’t you just order two VPLS services, use them as P2P links and bundle the two links into a multi-chassis link aggregation group (MLAG)?” like this:
Looking for vCDNI packet traces
One of the things I wanted to test in my UCS lab was the vCloud Director; I was interested in the details of the MAC-in-MAC implementation used by vCDNI. Unfortunately vCD requires an Oracle database and I simply didn’t have enough time to set that up. If you have vCD up and running and use vCDNI to create isolated networks, I would appreciate if you could take a few packet traces of traffic exchanged between VMs running on different ESX servers and send them to me. What I would need most are examples of:
Yearly subscription now available without a webinar registration
Some of my readers wanted to buy the yearly subscription but couldn’t decide which webinar to register for first (the yearly subscription was sold as webinar tickets). Fortunately the database structure I used for recordings turned out to be easily extendable; you can now buy the yearly subscription directly from my website with Google Checkout.
The amount of the material you get with the yearly subscription is also growing: you get access to recordings of sixteen webinars (and growing), all corresponding PDFs and well over 150 router configurations ... plus unlimited access to all live webinar sessions for the duration of your subscription.
DHCPv6+SLAAC+RA = DHCPv4
We all know that IPv6 handles host network parameter initialization a bit different than IPv4 (where we usually use DHCP), but the details could still confuse you if you’re just entering the IPv6 world.
A typical LAN-attached hosts needs its own address as well as the addresses of the default router and DNS server. DHCPv4 provides all three; in the IPv6 world you need two or three protocols as summarized in the following table
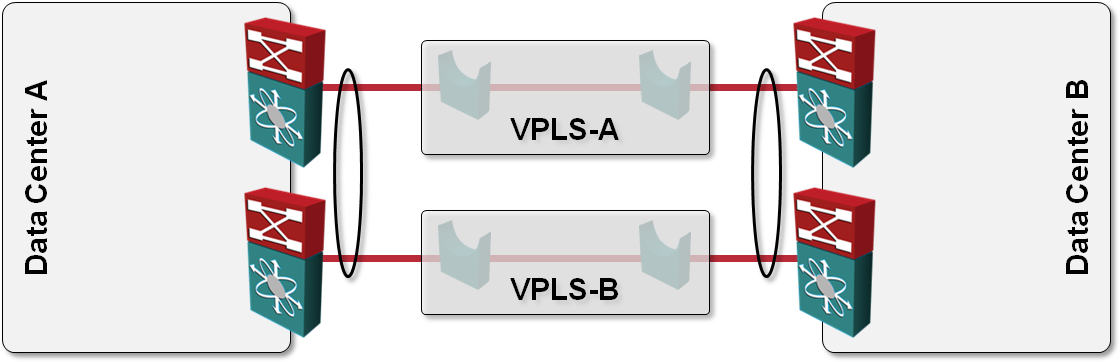
How would you use VPLS transport in L2 DCI?
One of the questions answered in my Data Center Interconnect webinar is: “what options do I have to build a layer-2 interconnect with transport technology X”, with X ∈ {dark-fiber, DWDM, SONET, pseudowire, VPLS, MPLS/VPN, IP}. VPLS is one of the tougher nuts to crack; it provides a switched LAN emulation, usually with no end-to-end spanning tree (which you wouldn’t want to have anyway).
Imagine the following simple scenario where we want to establish redundant connectivity between two data centers and the only transport technology we can get is VPLS (or some other Carrier Ethernet LAN service):
VEPA or vCloud Network Isolation?
If I could design my dream data center with total disregard to today’s limitations (and technologies from an alternate universe), it would have optimal connectivity between any two endpoints (real or virtual), no limits on VM mobility and on-demand L4-7 services insertion (be it firewalling, load balancing or something else) ... all of that implemented on truly scalable trombone-free networking infrastructure (in a dream world I don’t care whether it’s called routing or bridging).
FCoMPLS – attack of the zombies
A while ago someone asked me whether I think FC-over-MPLS would be a good PhD thesis. My response: while it’s always a good move to combine two totally unrelated fields in your PhD thesis (that almost guarantees you will be able to generate several unique and thus publishable articles), FCoMPLS might be tough because you’d have to make MPLS lossless. However, where there’s a will, there’s a way ... straight from the haze of the “Just because you can doesn’t mean you should” cloud comes FC-BB_PW defined in FC-BB-5 and several IETF drafts.
My first brief encounter with FCoMPLS was a twitxchange with Miroslaw Burnejko who responded to my “must be another lame joke” tweet with a link to a NANOG presentation briefly mentioning it and an RFC draft describing the FCoMPLS flow control details. If you know me, you have probably realized by now that I simply had to dig deeper.
Why would FC/FCoE scale better than iSCSI?
During one of the iSCSI/FC/FCoE tweetstorms @stu made an interesting claim: FC scales to thousands of nodes; iSCSI can’t do that.
You know I’m no storage expert, but I fail to see how FC would be inherently (architecturally) better than iSCSI. I would understand someone claiming that existing host or storage iSCSI adapters behave worse than FC/FCoE adapters, but I can’t grasp why properly implemented iSCSI network could not scale.
Am I missing something? Please help me figure this one out. Thank you!
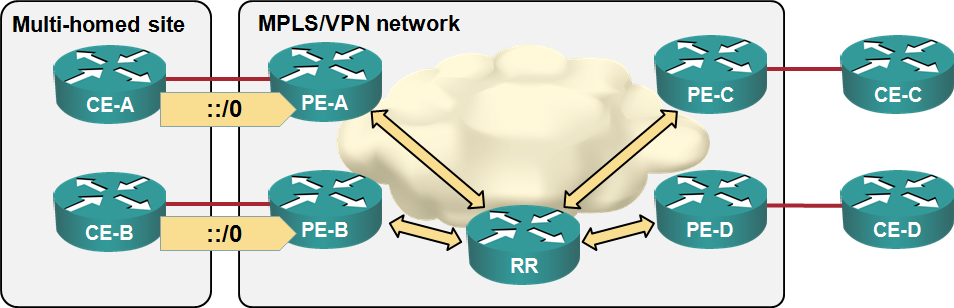
Load sharing in MPLS/VPN networks with route reflectors
Some of the e-mails and comments I received after writing the “Changing VPNv4 route attributes” post illustrated common MPLS/VPN misconceptions, so it’s worth addressing them in a series of posts. Let’s start with the simplest scenario: load balancingsharing toward a multi-homed customer site. We’ll use a very simple MPLS/VPN network with three customer sites, four CE-routers, four PE-routers a route reflector:
Doing more with less
One of my favorite vendors has been talking about Doing More With Less for years. Thanks to Scott Adams, we finally know what it means ;)

Local Area Mobility (LAM) – the true story
Every time I mention that Cisco IOS had Local Area Mobility (LAM) (the feature that would come quite handy in today’s virtualized data centers) more than a decade ago, someone inevitably asks “why don’t we use it?” LAM looks like a forgotten step-child, abandoned almost as soon as it was created (supposedly it never got VRF support). The reason is simple (and has nothing to do with the size of L3 forwarding tables): LAM was always meant to be a short-term kludge and L3 gurus never appreciated its potentials.
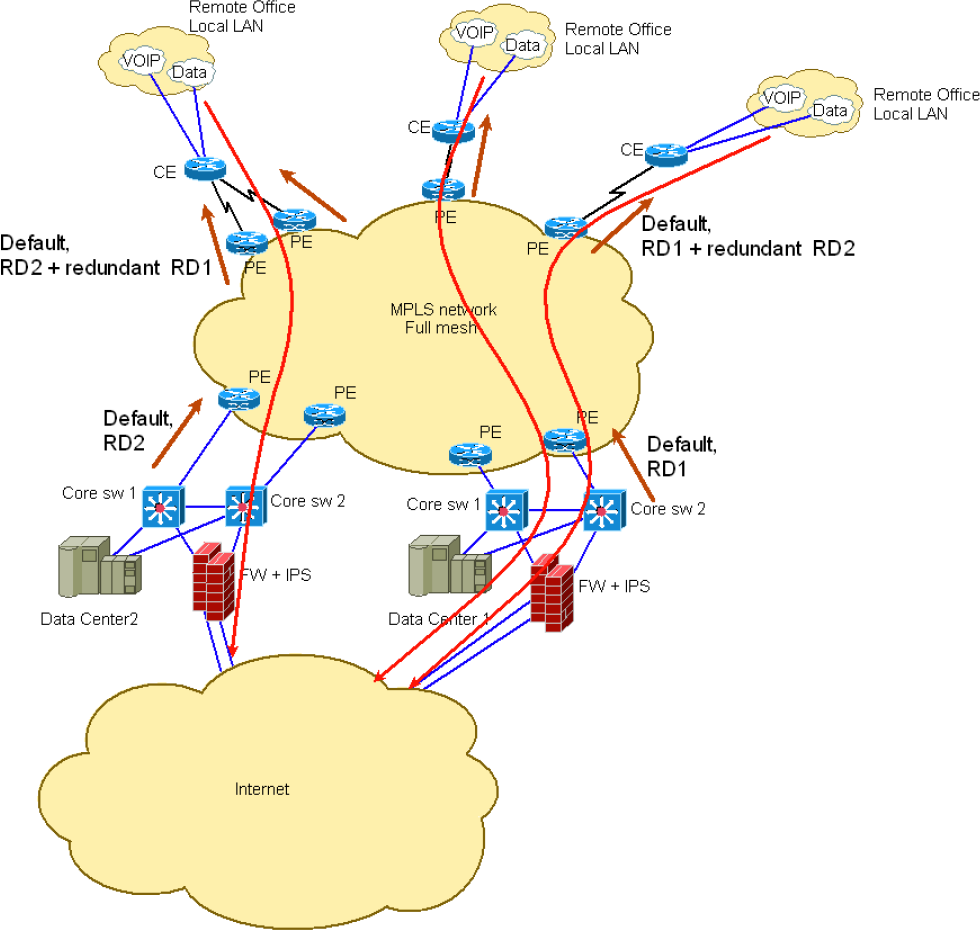
Changing VPNv4 route attributes within the MPLS/VPN network
John (not a real name for obvious reasons) sent me an interesting challenge after attending my Enterprise MPLS/VPN Deployment webinar. He’s designed an MPLS/VPN network approximated by the following diagram:
Layer-3 gurus: asleep at the wheel
I just read a great article by Kurt (the Network Janitor) Bales eloquently describing how a series of stupid decisions led to the current situation where everyone (but the people who actually work with the networking infrastructure) think stretched layer-2 domains are the mandatory stepping stone toward the cloudy nirvana.
It’s easy to shift the blame to everyone else, including storage vendors (for their love of FC and FCoE) and VMware (for the broken vSwitch design), but let’s face the reality: the rigid mindset of layer-3 gurus probably has as much to do with the whole mess as anything else.
How Did We Ever Get Into This Switching Mess?
If you’re confused about the numerous meanings of a switch, you’re not the only one. If you wonder how the whole mess started, here’s the full story (from the biased perspective of a grumpy GONER):
In the early 1980s, there were no bridges or routers. Hosts communicated directly with each other or used intermediate nodes (usually hosts, sometimes dedicated devices called gateways) to pass traffic. Networking engineers’ lives would have remained simple were it not for a few overly bright engineers at DEC who decided their application (LAT) would run directly on layer 2 to make it faster.
Changing IP precedence values in router-generated pings
When I was testing QoS behavior in MPLS/VPN-over-DMVPN networks, I needed a traffic source that could generate packets with different DSCP/IP precedence values. If you have enough routers in your lab (and the MPLS/DMVPN lab that was used to generate the router configurations you get as part of the Enterprise MPLS/VPN Deployment and DMVPN: From Basics to Scalable Networks webinars has 8 routers), it’s usually easier to use a router as a traffic source than to connect an extra IP host to the lab network. Task-at-hand: generate traffic with different DSCP values from the router.
The week of blunders
This week we finally got some great warm(er) dry weather after months of eternal late autumn interspersed with snowstorms and cold spells, making me way too focused on rock climbing while blogging and testing IOS behavior. The incredible results: two blunders in a single week.
First I “discovered” anomalies in ToS propagation between IP precedence values and MPLS EXP bits. It was like one of those unrepeatable cold fusion experiments: for whatever stupid reason it all made sense while I was doing the tests, but I was never able to recreate the behavior. The “End-to-end QoS marking in MPLS/VPN-over-DMVPN networks” post is fixed (and I’ve noticed a few additional QoS features while digging around).
EEM QA: what were they (not) doing?
When I was writing the applet that should stop accidental scheduled router reloads, I wanted to use the action string match command to perform pattern matching on the output of the show reload command. Somehow the applet didn’t want to work as expected, so I checked the documentation on Cisco’s web site.
Reading the command description, I should have realized the whole thing must be broken. It looks like the documentation writer was fast asleep; even someone with a major in classical philosophy and zero exposure to networking should be able to spot the glaring logical inconsistencies.
End-to-End QoS marking in MPLS/VPN-over-DMVPN networks
I got a great question in one of my Enterprise MPLS/VPN Deployment webinars when I was describing how you could run MPLS/VPN across DMVPN cloud:
That sounds great, but how does end-to-end QoS work when you run IP-over-MPLS-over-GRE-over-IPSec-over-IP?
My initial off-the-cuff answer was:
Well, when the IP packet arriving through a VRF interface gets its MPLS label, the IP precedence bits from the IP packet are copied into the MPLS EXP (now TC) bits. As for what happens when the MPLS packet gets encapsulated in a GRE packet and when the GRE packet is encrypted… I have no clue. I need to test it.
IPv6 Provider Independent Addresses
If you want your network to remain multihomed when the Internet migrates to IPv6, you need your own Provider Independent (PI) IPv6 prefix. That’s old news (I was writing about the multihoming elephant almost two years ago), but most of the IT industry managed to look the other way pretending the problem does not exist. It was always very clear that the lack of other multihoming mechanisms will result in explosion of global IPv6 routing tables (attendees of my Upcoming Internet Challenges webinar probably remember the topic very well, as it was one of my focal points) and yet nothing was done about it (apart from the LISP development efforts, which will still take a while before being globally deployed).
To make matters worse, some Service Providers behave like the model citizens in the IPv6 world and filter prefixes longer than /32 when they belong to the Provider Assigned (PA) address space, which means that you cannot implement reliable multihoming at all if you don’t get a chunk of PI address space.