Category: Load Balancing
Worth Reading: Flow Distribution Across ECMP Paths
Dip Singh wrote another interesting article describing how ECMP load balancing implementations work behind the scenes. Absolutely worth reading.
OSPF ECMP with Unnumbered IPv4 Interfaces
or how netlab made labbing fun again
The OSPF and ARP on Unnumbered IPv4 Interfaces triggered an interesting consideration: does ECMP work across parallel unnumbered links?
TL&DR: Yes, it works flawlessly on Arista EOS and Cisco IOS/XE. Feel free to test it out on any other device on which netlab supports unnumbered interfaces with OSPF.
Worth Reading: Load Balancing on Network Devices
Christopher Hart wrote a great blog post explaining the fundamentals of how packet load balancing works on network devices. Enjoy.
For more details, watch the Multipath Forwarding part of Advanced Routing Protocol Topics section of How Networks Really Work webinar.
Local TCP Anycast Is Really Hard
Pete Lumbis and Network Ninja mentioned an interesting Unequal-Cost Multipathing (UCMP) data center use case in their comments to my UCMP-related blog posts: anycast servers.
Here’s a typical scenario they mentioned: a bunch of servers, randomly connected to multiple leaf switches, is offering a service on the same IP address (that’s where anycast comes from).
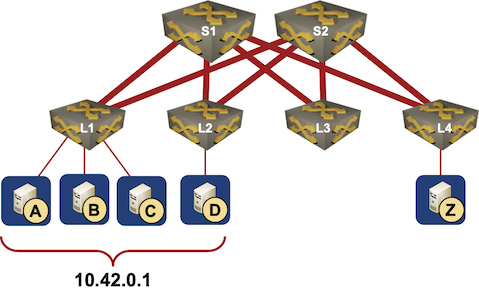
Typical Data Center Anycast Deployment
Topology- and Congestion-Driven Load Balancing
When preparing an answer to an interesting idea left as a comment to my unequal-cost load balancing blog post, I realized I never described the difference between topology-based and congestion-driven load balancing.
To keep things simple, let’s start with an easy leaf-and-spine fabric:
… updated on Friday, March 5, 2021 16:22 UTC
Chasing Anycast IP Addresses
One of my readers sent me this question:
My job required me to determine if one IP address is unicast or anycast. Is it possible to get this information from the bgp dump?
TL&DR: Not with anything close to 100% reliability. An academic research paper (HT: Andrea di Donato) documents a false-positive rate of around 10%.
If you’re not familiar with IP anycast: it’s a brilliant idea of advertising the same prefix from multiple independent locations, or the same IP address from multiple servers. Works like a charm for UDP (that’s how all root DNS servers are built) and supposedly pretty well across distant-enough locations for TCP (with a long list of caveats when used within a data center).
Can I Replace a Commercial Load Balancer with HAProxy?
A networking engineer attending the Building Next-Generation Data Centers online course sent me this question:
My client will migrate their data center, so they’re not interested in upgrading existing $vendor load balancers. Would HAProxy be a good alternative?
As you might be facing a similar challenge, here’s what I told him:
Moving Complexity to Application Layer?
One of my readers sent me this question:
One thing that I notice is you mentioned moving the complexity to the upper layer. I was wondering why browsers don't support multiple IP addresses for a single site – when a browser receives more than one IP address in a DNS response, it could try to perform TCP SYN to the first address, and if it fails it will move to the other address. This way we don't need an anycast solution for DR site.
Of course I pointed out an old blog post ;), and we all know that Happy Eyeballs work this way.
Follow-up: Load Balancers and Session Stickiness
My Why Do We Need Session Stickiness in Load Balancing blog post generated numerous interesting comments and questions, so I decided to repost them and provide slightly longer answers to some of the questions.
Warning: long wall of text ahead.
Why Do We Need Session Stickiness in Load Balancing?
One of the engineers watching my Data Center 3.0 webinar asked me why we need session stickiness in load balancing, what its impact is on load balancer performance, and whether we could get rid of it. Here’s the whole story from the networking perspective.