Category: Data Center
Worth Reading: Azure Datacenter Switch Failures
Microsoft engineers published an analysis of switch failures in 130 Azure regions (review of the article, The Next Platform summary):
- A data center switch has a 2% chance of failing in 3 months (= less than 10% per year);
- ~60% of the failures are caused by hardware faults or power failures, another 17% are software bugs;
- 50% of failures lasted less than 6 minutes (obviously crashes or power glitches followed by a reboot).
- Switches running SONiC had lower failure rate than switches running vendor NOS on the same hardware. Looks like bloatware results in more bugs, and taking months to fix bugs results in more crashes. Who would have thought…
Worth Reading: Running BGP in Large-Scale Data Centers
Here’s one of the major differences between Facebook and Google: one of them publishes research papers with helpful and actionable information, the other uses publications as recruitment drive full of we’re so awesome but you have to trust us – we’re not sharing the crucial details.
Recent data point: Facebook published an interesting paper describing their data center BGP design. Absolutely worth reading.
Just in case you haven’t realized: Petr Lapukhov of the RFC 7938 fame moved from Microsoft to Facebook a few years ago. Coincidence? I think not.
Local TCP Anycast Is Really Hard
Pete Lumbis and Network Ninja mentioned an interesting Unequal-Cost Multipathing (UCMP) data center use case in their comments to my UCMP-related blog posts: anycast servers.
Here’s a typical scenario they mentioned: a bunch of servers, randomly connected to multiple leaf switches, is offering a service on the same IP address (that’s where anycast comes from).
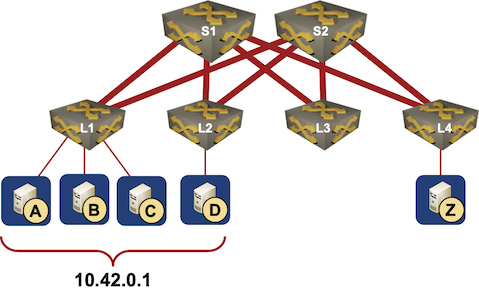
Typical Data Center Anycast Deployment
Mythbusting: NFV Data Center Fabric Buffering Requirements
Every now and then I stumble upon an article or a comment explaining how Network Function Virtualization (NFV) introduces new data center fabric buffering requirements. Here’s a recent example:
For Telco/carrier Cloud environments, where NFVs (which are much slower than hardware SGW) get used a lot, latency is higher with a lot of jitter due to the nature of software and the varying link speeds, so DC-level near-zero buffer is not applicable.
It seems to me we’re dealing with another myth. Starting with the basics:
Worth Watching: Rethinking BGP in the Data Center
Ever since draft-lapukhov was first published almost a decade ago, we all knew BGP was the only routing protocol suitable for data center networking… or at least Thought Leaders and vendor marketers seem to be of that persuasion.
… updated on Monday, May 24, 2021 12:05 UTC
Packet Bursts in Data Center Fabrics
When I wrote about the (non)impact of switching latency, I was (also) thinking about packet bursts jamming core data center fabric links when I mentioned the elephants in the room… but when I started writing about them, I realized they might be yet another red herring (together with the supposed need for large buffers in data center switches).
Here’s how it looks like from my ignorant perspective when considering a simple leaf-and-spine network like the one in the following diagram. Please feel free to set me straight, I honestly can’t figure out where I went astray.
Does Small Packet Forwarding Performance Matter in Data Center Switches?
TL&DR: No.
Here’s another never-ending vi-versus-emacs-type discussion: merchant silicon like Broadcom Trident cannot forward small (64-byte) packets at line rate. Does that matter, or is it yet another stimulating academic talking point and/or red herring used by vendor marketing teams to justify their high prices?
Here’s what I wrote about that topic a few weeks ago:
Rant: Cisco ACI Complexity
A while ago Antti Leimio wrote a long twitter thread describing his frustrations with Cisco ACI object model. I asked him for permission to repost the whole thread as those things tend to get lost, and he graciously allowed me to do it, so here we go.
I took a 5 days Cisco DCACI course. This is all new to me. I’m confused. Who is ACI for? Capabilities and completeness of features is fantastic but how to manage this complex system?
Chasing CRC Errors in a Data Center Fabric
One of my readers encountered an interesting problem when upgrading a data center fabric to 100 Gbps leaf-to-spine links:
- They installed new fiber cables and SFPs;
- Everything looked great… until someone started complaining about application performance problems.
- Nothing else has changed, so the culprit must have been the network upgrade.
- A closer look at monitoring data revealed CRC errors on every leaf switch. Obviously something was badly wrong with the whole batch of SFPs.
Fortunately, my reader took a closer look at the data before they requested a wholesale replacement… and spotted an interesting pattern:
Video: NetQ and Cumulus Linux Data Models
In the last part of his Cumulus Linux 4.0 Update Pete Lumbis talked about using NetQ to capture streaming telemetry and increase network observability, and the new model-driven configuration approach (including all the usual buzzwords like NETCONF, RPC, YAML, JSON, and OpenConfig) coming in 2020.