Hmmm: Rail-Optimized Networking for AI Workloads
Phil Gervasi wrote an interesting article describing Rail-Optimized Networking for AI Training Workloads. Go read it first; I’ll wait.
Does it sound interesting? Were you able to see behind the curtain and figure out what it’s really about?
The way I read it, he described a regular leaf-and-spine fabric in which the workload is placed in such a way that most traffic stays within leaf switches. That has nothing to do with networking; it’s just smart workload placement. Straight from Phil’s article:
A rail isn’t a separate topology or a bypass of the leaf-spine fabric. Instead, it’s a consistent mapping of endpoints to a specific network plane within a shared Clos-based fabric.
I don’t know enough about intra-server forwarding to figure out whether the “stay within the leaf switch and use the server bus to send traffic to the other GPU” idea has anything to do with networking, or is it just using RDMA to write into another part of memory (= application-level solution).
In any case, the idea is not new. This is a slide I had in my Designing a Private Cloud presentation from 2014, and the idea was already pretty old and well known by then.
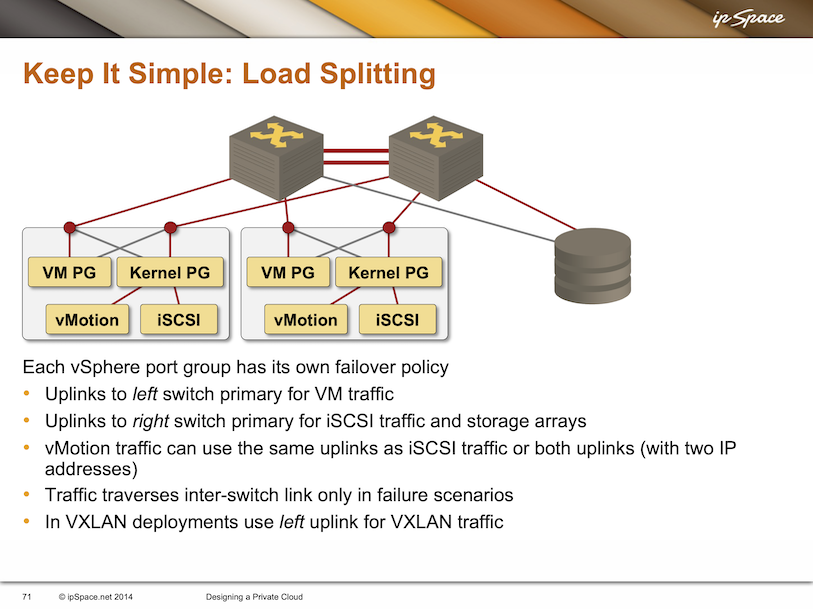
What about the other idea Phil described: use disconnected leaf switches (rail-only networks)? Back to his article:
Each rail acts as an independent failure domain, which also provides a bounded congestion domain.
Remember the SAN-A/SAN-B networks from the 1990s, using either Fibre Channel or iSCSI?
Long story short: When in doubt, read RFC 1925 ;))
I've read it couple days ago and did not get what's the fuzz about. It's content that could but should not be at all.
From ChatGPT (GPT-5.3) with the prompt: "Write a TL;DR with a maximum of 5 sentences for the following webpage"
> Rail-optimized networking for AI training focuses on aligning job placement with the physical network so that most high-bandwidth GPU traffic stays within the same “rail” (a group of closely connected nodes). > This reduces reliance on oversubscribed fabric links, improving throughput, latency, and training consistency without changing the underlying leaf-spine architecture. > The approach treats each rail as a semi-independent domain, which helps contain congestion and limit the blast radius of failures. > It requires tight coordination between schedulers, networking, and observability systems to place and monitor workloads effectively. > Overall, it’s a practical optimization strategy that boosts AI training efficiency by using existing infrastructure more intelligently rather than introducing new network designs.
Apstra
1,171 views Streamed live on Dec 5, 2024
The next in the AI/ML series with Petr Lapukov.
https: //youtu.be/gygHHinMPII?list=PLMYH1xDLIabuZCr1Yeoo39enogPA2yJB7