Category: BGP
Worth Reading: Taming the BGP Reconfiguration Transients
Almost exactly a decade ago I wrote about a paper describing how IBGP migrations can cause forwarding loops and how one could reorder BGP reconfiguration steps to avoid them.
One of the paper’s authors was Laurent Vanbever who moved to ETH Zurich in the meantime where his group keeps producing great work, including the Chameleon tool (code on GitHub) that can tame transient loops while reconfiguring BGP. Definitely something worth looking at if you’re running a large BGP network.
Worth Exploring: BGP from Theory to Practice
My good friend Tiziano Tofoni finally created an English version of his evergreen classic BGP from theory to practice with co-authors Antonio Prado and Flavio Luciani.
I had the Italian version of the book since the days I was running SDN workshops with Tiziano in Rome, and it’s really nice to see they finally decided to address a wider market.
Also, you know what would go well with that book? Free open-source BGP configuration labs of course 😉
BGP Labs: Multivendor External Routers
Here’s a quick update on the BGP Labs project status: now that netlab release 1.6.4 is out, I could remove the dependency on using Cumulus Linux as the external BGP router.
You can use any device that is supported by bgp.session and bgp.policy plugins as the external BGP router. You could use Arista EOS, Aruba AOS-CX, Cisco IOSv, Cisco IOS-XE, Cumulus Linux or FRR as external BGP routers with netlab release 1.6.4, and I’m positive Jeroen van Bemmel will add Nokia SR Linux to that list.
Video: History of BGP Route Leaks
I’ll be talking about Internet routing security at the Deep conference in a few days, and just in case you won’t be able to make it1 ;) here’s the first bit of my talk: a very brief history of BGP route leaks2.
Note: you’ll find more Network Security Fallacies videos in the How Networks Really Work webinar.
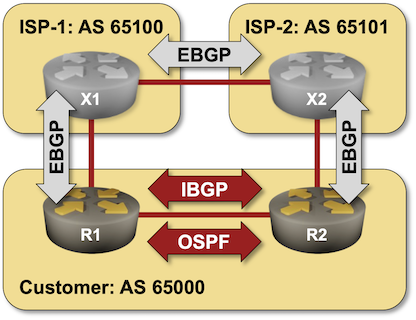
BGP Labs: Build Larger Networks with IBGP
After going through the BGP basics, it’s time to build a network that has more than one BGP router in it, starting with the simplest possible topology: a site with two WAN edge routers.
… updated on Thursday, November 2, 2023 10:36 UTC
Will Network Devices Reject BGP Sessions from Unknown Sources?
TL&DR: Violating the Betteridge’s Law of Headlines, the answer is “Yes, but the devil is in the details.”
It all started with the following observation by Minh Ha left as a comment to my previous BGP session security blog post:
I’d think it’d be obvious for BGP routers to only accept incoming sessions from configured BGP neighbors, right? Because BGP is the most critical infrastructure, the backbone of the Internet, why would you want your router to accept incoming session from anyone but KNOWN sources?
Following my “opinions are good, facts are better” mantra, I decided to run a few tests before opinionating1.
BGP Labs: TCP-AO Protection of BGP Sessions
A few days after I published the EBGP session protection lab, Jeroen van Bemmel submitted a pull request that added TCP-AO support to netlab. Now that the release 1.6.3 is out, I could use it to build the Protect BGP Sessions with TCP Authentication Option (TCP-AO) lab exercise.
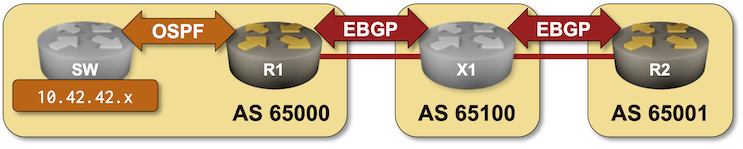
BGP Labs: Route Aggregation
In the BGP Route Aggregation lab you can practice:
- OSPF-to-BGP route redistribution
- BGP route aggregation
- Suppression of more-specific prefixes in the BGP table
- Prefix-based filtering of outbound BGP updates
BGP Session Security: Be Very Skeptical
A while ago I explained how Generalized TTL Security Mechanism could be used to prevent denial-of-service attacks on routers running EBGP. Considering the results published in Analyzing the Security of BGP Message Parsing presentation from DEFCON 31 I started wondering how well GTSM implementations work.
TL&DR summary:
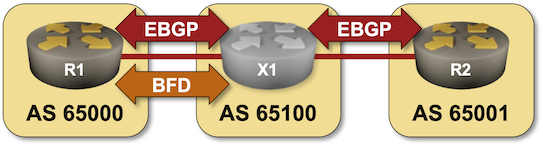
BGP Labs: Use BFD to Speed Up Convergence
In the next BGP labs exercise, you can practice tweaking BGP timers and using BFD to speed up BGP convergence.