Category: BGP
BGP Graceful Restart Considered Harmful
A networking engineer with a picture-perfect implementation of a dual-homed enterprise site using BGP communities according to RFC 1998 to select primary- and backup uplinks contacted me because they experienced unacceptably long failover times.
They measured the failover times caused by the primary uplink loss and figured out it takes more than five minutes to reestablish Internet connectivity to their site.
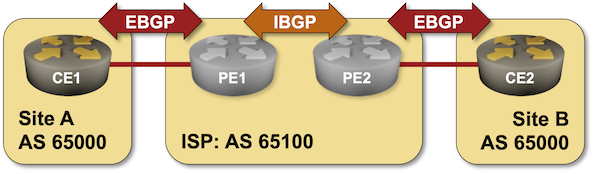
BGP Labs: Reuse BGP AS Number Across Sites
When I published the Bidirectional Route Redistribution lab exercise, some readers were quick to point out that you’ll probably have to reuse the same AS number across multiple sites in a real-life MPLS/VPN deployment. That’s what you can practice in today’s lab exercise – an MPLS/VPN service provider allocated the same BGP AS number to all your sites and expects you to deal with the aftermath.
Upcoming BGP Labs, 2024 Edition
It’s that time of the year when we create unreachable goals and make empty promises to ourselves (or others) that we subconsciously know we’ll fail.
I tried to make that process a bit more structured and create external storage for my lab ideas – I started publishing more details on future BGP lab scenarios. The lab descriptions contain a high-level overview of the challenge and the lab topology; the details will be filled in later.
BGP Challenge: Merge Autonomous Systems
Here’s a challenge in case you get bored during the Christmas break: merge two networks running BGP (two autonomous systems) without changing anything but the configurations of the routers connecting them (the red BGP session in the diagram). I won’t give you any hints; you can discuss it in the comments or a GitHub discussion.
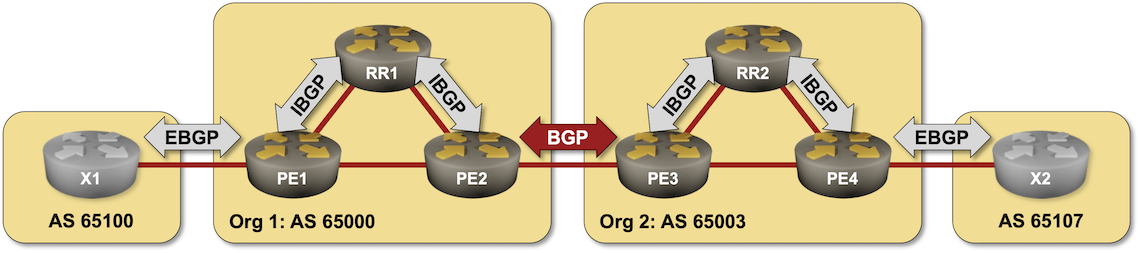
Hopefully, you won’t have to deal with something similar in real life, but then we know that crazy requirements trump good designs any day of the week.
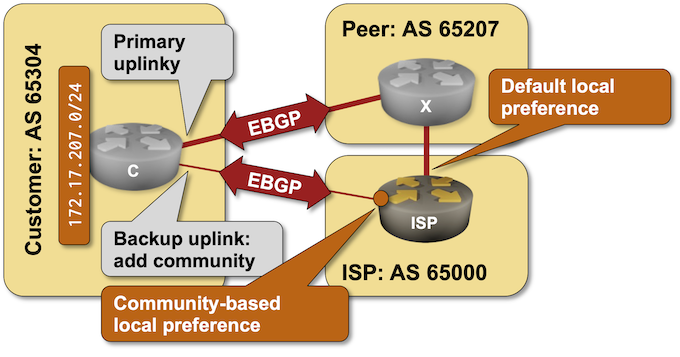
BGP Labs: Use BGP Communities in a Routing Policy
A previous BGP lab focused on the customer side of BGP communities: adding them to BGP updates to influence upstream ISP behavior. Today’s lab focuses on the ISP side of the equation: using BGP communities in a routing policy to implement RFC 1998-style behavior.
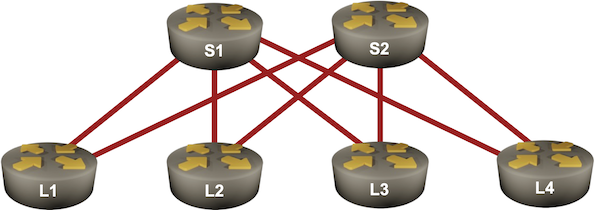
BGP Labs: Use BGP Route Reflectors
In the previous BGP labs, we built a network with two adjacent BGP routers and a larger transit network using IBGP. Now let’s make our transit network scalable with BGP route reflectors, this time using a slightly larger network:
The BGP Origin Attribute
Kristijan Taskovski asked an interesting question related to my BGP AS-prepending lab:
I’ve never personally done this on the net but….wouldn’t the BGP origin code also work with moving one’s ingress traffic similarly to AS PATH?
TL&DR: Sort of, but not exactly. Also, just because you can climb up ropes using shoelaces instead of jumars doesn’t mean you should.
Let’s deal with the moving traffic bit first.
The BGP Multi-Exit Discriminator (MED) Saga
Martijn Van Overbeek left this comment on my LinkedIn post announcing the BGP MED lab:
It might be fixed, but I can recall in the past that there was a lot of quirkiness in multi-vendor environments, especially in how different vendors use it and deal with the setting when the attribute does exist or does not have to exist.
TL&DR: He’s right. It has been fixed (mostly), but the nerd knobs never went away.
In case you’re wondering about the root cause, it was the vagueness of RFC 1771. Now for the full story ;)
BGP Labs: Set BGP Communities on Outgoing Updates
It’s hard to influence the behavior of someone with strong opinions (just ask any parent with a screaming toddler), and trying to persuade an upstream ISP not to send the traffic over a backup link is no exception – sometimes even AS path prepending is not a strong enough argument.
An easy solution to this problem was proposed in 1990s – what if we could attach some extra attributes (called communities just to confuse everyone) to BGP updates and use them to tell adjacent autonomous systems to lower their BGP local preference? You can practice doing that in the Attach BGP Communities to Outgoing BGP Updates lab exercise.
Can a Router Use the Default Route to Reach BGP Next Hops?
TL&DR: Yes.
Starting with RFC 4271, Route Resolvability Condition:
- A route without an outgoing interface is resolvable if its next hop is resolvable without recursively using the same route.
- A route with an outgoing interface is always considered resolvable.
- BGP routes can be resolved through routes with just a next hop or an outgoing interface.