Blog Posts in November 2021
Dynamic Negotiation of BGP Capabilities
I wanted to write a blog post explaining the intricacies of Advertisement of Multiple Paths in BGP, got into a yak-shaving exercise when discussing the need to exchange BGP capabilities to enable this feature, and decided to turn it into a separate prerequisite blog post. The optimal path selection with BGP AddPath post is coming in a few days.
The Problem
Whenever you want to use BGP for something else than simple IPv4 unicast routing the BGP neighbors must agree on what they are willing to do – be it multiprotocol extensions and individual additional address families, graceful restart, route refresh… (IANA has the complete BGP Capability Codes registry).
Mikrotik RouterOS and VyOS Added to netsim-tools
Stefano Sasso took my “Don’t complain, submit a PR” advice seriously and did a wonderful job adding support for Mikrotik RouterOS and VyOS to netsim-tools, increasing the number of supported platforms to twelve. His additions are available in release 1.0.2 which also includes:
- Automatic creation of groups based on BGP AS numbers
- Group-wide node attributes
- Experimental support for Python plugins
Interested? Start with tutorials and installation guide which includes lab building instructions.
Git as a Source of Truth for Network Automation
In Git as a source of truth for network automation, Vincent Bernat explained why they decided to use Git-managed YAML files as the source of truth in their network automation project instead of relying on a database-backed GUI/API product like NetBox.
Their decision process was pretty close to what I explained in Data Stores and Source of Truth parts of Network Automation Concepts webinar: you need change logging, auditing, reviews, and all-or-nothing transactions, and most IPAM/CMDB products have none of those.
On a more positive side, NetBox (and its fork, Nautobot) has change logging (HT: Leo Kirchner) and things are getting much better with Nautobot Version Control plugin. Stay tuned ;)
Worth Reading: Load Balancing on Network Devices
Christopher Hart wrote a great blog post explaining the fundamentals of how packet load balancing works on network devices. Enjoy.
For more details, watch the Multipath Forwarding part of Advanced Routing Protocol Topics section of How Networks Really Work webinar.
Lesson Learned: Some Services Are Not Worth Delivering
Here’s one of the secrets to AWS’s unprecedented scale and financial success: they quickly figured out that some services are not worth delivering. Most everyone else believes in building snowflake single-customer solutions to solve imaginary problems, effectively losing money while doing so.
Circular Dependencies, VMware NSX-T Edition
A friend of mine sent me a link to a lengthy convoluted document describing the 17-step procedure (with the last step having 10 micro-steps) to follow if you want to run NSX manager on top of N-VDS, or as they call it: Deploy a Fully Collapsed vSphere Cluster NSX-T on Hosts Running N-VDS Switches1.
You might not be familiar with vSphere networking and the way NSX-T uses that (in which case I can highly recommend vSphere and NSX webinars), so here’s a CliffsNotes version of it: you want to put the management component of NSX-T on top of the virtual switch it’s managing, and make it accessible only through that virtual switch. What could possibly go wrong?
Anycast Fundamentals
I got into an interesting debate after I published the Anycast Works Just Fine with MPLS/LDP blog post, and after a while it turned out we have a slightly different understanding what anycast means. Time to fall back to a Wikipedia definition:
Anycast is a network addressing and routing methodology in which a single destination IP address is shared by devices (generally servers) in multiple locations. Routers direct packets addressed to this destination to the location nearest the sender, using their normal decision-making algorithms, typically the lowest number of BGP network hops.
Based on that definition, any transport technology that allows the same IP address or prefix to be announced from several locations supports anycast. To make it a bit more challenging, I would add “and if there are multiple paths to the anycast destination that could be used for multipath forwarding1, they should all be used”.
… updated on Friday, November 26, 2021 15:35 UTC
Multi-Threaded Routing Daemons
When I wrote the Why Does Internet Keep Breaking? blog post a few weeks ago, I claimed that FRR still uses single-threaded routing daemons (after a too-cursory read of their documentation).
Donald Sharp and Quentin Young politely told me I was an idiot I should get my facts straight, I removed the offending part of the blog post, promised to write another one going into the details, and Quentin improved the documentation in the meantime, so here we are…
netlab Custom Groups and Deployment Templates
Using custom templates to test IP anycast with MPLS was fun, but as I got into interesting discussions focusing on convoluted details, I found myself going through the same set of steps too many times.
It started with the need to specify individual devices in netlab config command to create new loopback interfaces on anycast servers but not on any other device in the lab. Wouldn’t it be nice to have a group of devices (similar to Ansible groups) that one could use in the limit parameter of netlab config?
RFC 9098: Operational Implications of IPv6 Extension Headers
It took more than seven years to publish an obvious fact as an RFC: IPv6 extension headers are a bad idea (RFC 9098 has a much more polite title or it would never get published).
Worth Reading: How to Get Useful Answers to Your Questions
Another must-read masterpiece by Julia Evans: how to get useful answers to your questions.
Video: Early Data-Link-Layer Addressing
After a brief coverage of the theoretical aspects of network addressing, it’s time to pay a brief visit to the early data-link-layer addressing solutions, from one address per datagram/frame (SDLC, HDLC) and ignore this address (PPP) to no address on P2P links (SLIP).
Hardware Differences between Routers and Switches
One of my readers sent me this age-old question:
Is there a real difference in the underlying hardware of switches and routers in terms of the traffic processing chips and their capabilities in terms of routing and switching (or should I say only switching)?
Let’s get the terminology straight. Router is a technical term for a device that forwards packets based on network layer information. Switch is a marketing term for a device that does something with packets.
Rephrasing the question: is there a hardware difference between a box marketed as a router and another box marketed as a layer-3 switch?
TL&DR: Yes.
… updated on Wednesday, February 16, 2022 16:15 UTC
Anycast Works Just Fine with MPLS/LDP
I stumbled upon an article praising the beauties of SR-MPLS that claimed:
Yet MPLS, until recently, was deprived of anycast routing. This is because MPLS is not a pure packet switching technology, but has a control plane based on virtual circuit switching.
My first reaction was “that’s not how MPLS works,”1 followed by “that would be fun to test” a few seconds later.
Optimizing the Time-to-First-Byte
I don’t think I’ve ever met someone saying “I wish my web application would run slower.” Everyone wants their stuff to run faster, but most environments are not willing to pay the cost (rearchitecting the application). Welcome to the wonderful world of PowerPoint “solutions”.
The obvious answer: The Cloud. Let’s move our web servers closer to the clients – deploy them in various cloud regions around the world. Mission accomplished.
Not really; the laws of physics (latency in particular) will kill your wonderful idea. I wrote about the underlying problems years ago, wrote another blog post focused on the misconceptions of cloudbursting, but I’m still getting the questions along the same lines. Time for another blog post, this time with even more diagrams.
Overlay Virtual Networking Examples
One of ipSpace.net subscribers wanted to see a real-life examples in the Overlay Virtual Networking webinar:
I would be nice to have real world examples. The webinar lacks of contents about how to obtain a fully working L3 fabric overlay network, including gateways, vrfs, security zones, etc… I know there is not only one “design for all” but a few complete architectures from L2 to L7 will be appreciated over deep-dives about specific protocols or technologies.
Most ipSpace.net webinars are bits of a larger puzzle. In this particular case:
Jerikan+Ansible: a Configuration Management System
Vincent Bernat and his team open-sourced Jerikan, a production-grade network configuration management system.
It might not be immediately applicable to your network, but I’m positive you could find tons of good ideas in it.
Interesting: What's Wrong with Bitcoin
I read tons of articles debunking the blockchain hype, and the stupidity of waisting CPU cycles and electricity on calculating meaningless hashes; here’s a totally different take on the subject by Avery Pennarun (an update written ten years later).
TL&DR: Bitcoin is a return to gold standard, and people who know more about economy than GPUs and hash functions have figured out that’s a bad idea long time ago.
Non-Stop Routing (NSR) 101
After Non-Stop Forwarding, Stateful Switchover and Graceful Restart, it’s time for the pinnacle of high-availability switching: Non-Stop Routing (NSR)1.
The PowerPoint-level description of this idea sounds fantastic:
- A device runs two active copies of its control plane.
- There is no cold/warm start of the backup control plane. The failover is almost instantaneous.
- The state of all control plane protocols is continuously synchronized between the two control plane instances. If one of them fails, the other one continues running.
- A failure of a control plane instance is thus invisible from the outside.
If this sounds an awful lot like VMware Fault Tolerance, you’re not too far off the mark.
Building a Separate Infrastructure for Guest Access
One of my readers sent me an age-old question:
I have my current guest network built on top of my production network. The separation between guest- and corporate network is done using a VLAN – once you connect to the wireless guest network, you’re in guest VLAN that forwards your packets to a guest router and off toward the Internet.
Our security team claims that this design is not secure enough. They claim a user would be able to attach somehow to the switch and jump between VLANs, suggesting that it would be better to run guest access over a separate physical network.
Decades ago, VLAN implementations were buggy, and it was possible (using a carefully crafted stack of VLAN tags) to insert packets from one VLAN to another (see also: VLAN hopping).
… updated on Tuesday, February 15, 2022 15:42 UTC
Creating BGP Multipath Lab with netlab
I was editing the BGP Multipathing video in the Advanced Routing Protocols section of How Networks Really Work webinar, got to the diagram I used to explain the intricacies of IBGP multipathing and said to myself “that should be easy (and fun) to set up with netlab”.
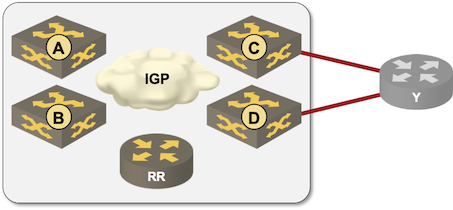
Fifteen minutes later1 I had the lab up and running and could verify that BGP works exactly the way I explained it in the webinar.
Feedback: Business Aspects of Networking
Every other blue moon someone asks me to do a not-so-technical presentation at an event, and being a firm believer in frugality I turn most of them into live webinar sessions collected under the Business Aspects of Networking umbrella.
At least some networking engineers find that perspective useful. Here’s what Adrian Giacometti had to say about that webinar:
Managing Hierarchical Device Configurations
Parsing and modifying IOS-like hierarchical device configurations is an interesting challenge, more so if you have no idea what the configuration commands mean or whether their order is relevant (I’m looking at you, Ansible ;).
Network to Code team decided to solve that problem for good, open-sourced Hierarchical Configuration Python library, and published a getting started article on their blog.
Soap Opera: SRv6 Is Insecure
I heard about SRv6 when it was still on the drawing board, and my initial reaction was “Another attempt to implement source routing. We know how that ends.” The then-counter-argument by one of the proponents went along the lines of “but we’ll use signed headers to prevent abuse” and I thought “yeah, that will work really well in silicon implementations”.
Years later, Andrew Alston decided to document the state of the emperor’s wardrobe (TL&DR: of course SRv6 is insecure and can be easily abused) and the counter-argument this time was “but that applies to any tunnel technology”. Thank you, we knew that all along, and that’s not what was promised.
You might want to browse the rest of that email thread; it’s fun reading unless you built your next-generation network design on SRv6 running across third-party networks… which was another PowerPoint case study used by SRv6 proponents.
Video: How Can You Master Public Cloud Networking?
If you’re a regular reader of this blog, you’ve probably realized there’s still need for networking in public clouds, and mastering it requires slightly different set of skills. What could you as a networking engineer to get fluent in this different world? I collected a few hints in the last video in Introduction to Cloud Computing webinar.
… updated on Saturday, November 6, 2021 13:31 UTC
Why Does Internet Keep Breaking?
James Miles sent me a long list of really good questions along the lines of “why do we see so many Internet-related outages lately and is it due to BGP and DNS creaking of old age”. He started with:
Over the last few years there are more “high profile” incidents relating to Internet connectivity. I raise the question, why?
The most obvious reason: Internet became mission-critical infrastructure and well-publicized incidents attract eyeballs.
Ignoring the click baits, the underlying root cause is in many cases the race to the bottom. Large service providers brought that onto themselves when they thought they could undersell the early ISPs and compensate their losses with voice calls (only to discover that voice-over-Internet works too well).
Even Simple Data Models Are a Huge Win
Dan Augustine sent me a wonderful example illustrating how even a very simple data model together with some automation templates can simplify a large-scale deployment.
We have a 100 router installation coming up for our schools and both of our installation vendors do not use open source templating tools and they are not willing to share.
Having taken the Data Models in Network Automation part of your Network Automation Concepts webinar, I decided to install GitLab, make an Ansible project and invite our installation partners to the project.
Where Would You Need DNS Anycast?
One of the publicly observable artifacts of the October 2021 Facebook outage was an intricate interaction between BGP routing and their DNS servers needed to support optimal anycast configuration. Not surprisingly, it was all networking engineers’ fault according to some opinions1
There’s no need for anycast2/BGP advertisement for DNS servers. DNS is already highly available by design. Only network people never understand that, which leads to overengineering.
It’s not that hard to find a counter-argument3: while it looks like there are only 13 root name servers4, each one of them is a large set of instances advertising the same IP prefix5 to the Internet.
netsim-tools Release 1.0
It looks like netsim-tools reached a somewhat stable state, so it was time to do a cleanup and publish release 1.0 (also available on PyPi, use pip3 install –upgrade netsim-tools to fetch it).
During the cleanup, I removed all references to the obsolete scripts, leaving only the netlab command. I also found an old bash script that enabled LLDP passthrough on Linux bridges and made it part of netlab up process; your libvirt-based labs will have LLDP enabled by default.
Interested? Install the tools and follow the tutorials to get started.