Blog Posts in October 2021
Worth Reading: Operators and the IETF
Long long time ago (seven years to be precise), ISOC naively tried to bridge the gap between network operators and Internet Vendor Engineering Task Force1. They started with a widespread survey asking operators why they’re hesitant to participate in IETF mailing lists and meetings.
The result: Operators and the IETF draft that never moved beyond -00 version. A quick glimpse into the Potential Challenges will tell you why IETF preferred to kill the messenger (and why I published this blog post on Halloween).
Worth Reading: Programming Sucks
Just FYI: if you’re wondering about the wisdom of every networking engineer should become a programmer religion, you might benefit from the Programming Sucks reality check. I had just enough exposure to programming to realize how spot-on it is (and couldn’t decide whether to laugh or cry).
Nonlinear Effects of Optimization-Induced Complexity
We have school holidays this week, so I’m reposting wonderful comments that would otherwise be lost somewhere in the page margins. Today: Minh Ha on recent Facebook failure and overly complex systems (slightly edited).
I incidentally commented on your NSF post some 3 weeks before […the Facebook outage…] happened, on the unpredictable nature of nonlinear effects resulting from optimization-induced complexity. Their outage just drives home the point that optimization is a dumb process and leads to combinations of circular dependency that no one can account for and test.
Big Picture: BFD, Non-Stop Forwarding, and Graceful Restart
We have school holidays this week, so I’m reposting wonderful comments that would otherwise be lost somewhere in the page margins. Today: Erik Auerswald’s excellent summary of BFD, NSF, and GR.
I’d suggest to step back a bit and consider the bigger picture: What is BFD good for? What is GR/NSF/NSR/SSO good for?
BFD and GR/NSF/NSR/SSO have different goals: one enables quick fail over, the other prevents fail over. Combining both promises to be interesting.
EVPN/VXLAN Complexity
We have school holidays this week, so I’m reposting wonderful comments that would otherwise be lost somewhere in the page margins. Today: Minh Ha on complexity of emulating layer-2 networks with VXLAN and EVPN.
Dmytro Shypovalov is a master networker who has a sophisticated grasp of some of the most advanced topics in networking. He doesn’t write often, but when he does, he writes exceptional content, both deep and broad. Have to say I agree with him 300% on “If an L2 network doesn’t scale, design a proper L3 network. But if people want to step on rakes, why discourage them.”
Interactions Between BFD and Graceful Restart
We have school holidays this week, so I’m reposting wonderful comments that would otherwise be lost somewhere in the page margins. Today: Dmitry Perets on the interactions between BFD and GR.
Well, assuming that the C-bit is set honestly (will be funny if not) and assuming that the Helper is using this bit correctly (and I think it’s pretty well defined what “correctly” means - see section 4.3 in RFC 5882), the answer is pretty clear.
Feedback: How Networks Really Work
A few weeks ago, I asked my subscribers which webinar they’d like to see in November (thanks a million to everyone who replied!). Not surprisingly, network automation got the top spot, but I was a bit sad to see my long-term pet project at the bottom of the list:

Worth Reading: Making a Case for Automation Architecture
In case you’re ever asked to justify an investment in network automation, read How to Make the Case for Automation Architecture first. Not surprisingly, it includes the evergreen what problem are you trying to solve?
Worth Reading: Network Validation Evolution at Hostinger
Network validation is becoming another overhyped buzzword with many opinionated pundits talking about it and few environments using it in practice (why am I not surprised?)
As always, there are exceptions. They don’t have to be members of the FAANG club, and some of them get the job done with open-source tools regardless of what vendor marketers would like you to believe. For example, Donatas Abraitis described how the Hostinger networking team gradually implemented network validation using Cumulus VX, Vagrant, SuzieQ, PyTest and Test Kitchen. Enjoy!
Video: Introduction to AI/ML Hype
In May 2021, Javier Antich ran a great webinar explaining the principles of Artificial Intelligence and Machine learning and how they apply (or not) to networking.
He started with a brief overview of AI/ML hype that should help you understand why there’s a bit of a difference between self-driving cars (not that we got there) and self-driving networks.
Circular Dependencies Considered Harmful
A while ago, my friend Nicola Modena sent me another intriguing curveball:
Imagine a CTO who has invested millions in a super-secure data center and wants to consolidate all compute workloads. If you were asked to run a BGP Route Reflector as a VM in that environment, and would like to bring OSPF or ISIS to that box to enable BGP ORR, would you use a GRE tunnel to avoid a dedicated VLAN or boring other hosts with routing protocol hello messages?
While there might be good reasons for doing that, my first knee-jerk reaction was:
Do We Need Multiple Global IPv6 Addresses Per Interface (RFC 7934)
I was happily munching popcorn while watching the latest season of Lack of DHCPv6 on Android soap opera on v6ops mailing list when one of the lead actors trying to justify the current state of affairs with a technical argument quoted an RFC to prove his rightful indignation with DHCPv6 and the decision not to implement it in Android:
[…not having multiple IPv6 addresses per interface…] is also harmful for a variety of reasons, and for general purpose devices, it’s not recommended by the IETF. That’s exactly what RFC 7934 is about - explaining why it’s harmful.
Graceful Restart and BFD
The whole High Availability Switching series started with a question along the lines of “does it make sense to run BFD together with Graceful Restart”. After Non-Stop Forwarding 101, Graceful Restart 101, and Graceful Restart and Convergence Speed we finally have enough information to answer that question.
TL&DR: Most probably not.
A more nuanced answer depends (as always) on a gazillion implementation details.
Start a Virtual Lab with a Single Command
In mid-October I finally found time to add the icing to the netlab cake: netlab up command takes a lab topology and does everything needed to have a running virtual lab:
- Create Vagrantfile or containerlab topology file
- Create Ansible inventory
- Start the lab with vagrant up or containerlab deploy
- Deploy device configurations, from LLDP and interface addressing to routing protocols and Segment Routing
Worth Reading: The Software Industry IS STILL the Problem
Every other blue moon someone writes (yet another) article along the lines of professional liability would solve so many broken things in the IT industry. This time it’s Poul-Henning Kamp of the FreeBSD and Varnish fame with The Software Industry IS STILL the Problem. Unfortunately it’s just another stab at the windmills considering how much money that industry pours into lobbying.
MUST READ: ARP Problems in EVPN
Decades ago there was a trick question on the CCIE exam exploring the intricate relationships between MAC and ARP table. I always understood the explanation for about 10 minutes and then I was back to I knew why that’s true, but now I lost it.
Fast forward 20 years, and we’re still seeing the same challenges, this time in EVPN networks using in-subnet proxy ARP. For more details, read the excellent ARP problems in EVPN article by Dmytro Shypovalov (I understood the problem after reading the article, and now it’s all a blur 🤷♂️).
Lessons Learned: Complexity Will Kill Your System
You wouldn’t believe the intricate network designs I created decades ago until I learned that having uninterrupted sleep is worth more than proving I can get the impossible to work (see also: using EBGP instead of IGP in a 4-node data center fabric).
Once I started valuing my free time, I tried to design things to be as simple as possible. However, as my friend Nicola Modena once said, “Consultants must propose new technologies because they must be seen as bringing innovation,” and we all know complexity sells. Go figure.
BGP Optimal Route Reflection 101
Almost a decade ago I described a scenario in which a perfectly valid IBGP topology could result in a permanent routing loop. While one wouldn’t expect to see such a scenario in a well designed network, it’s been known for ages1 that using BGP route reflectors could result in suboptimal forwarding.
Here’s a simple description of how that could happen:
Why Does DHCPv6 Matter?
In case you missed it, there’s a new season of Lack of DHCPv6 on Android soap opera on v6ops mailing list. Before going into the juicy details, I wanted to look at the big picture: why would anyone care about lack of DHCPv6 on Android?
The requirements for DHCPv6-based address allocation come primarily from enterprise environments facing legal/compliance/other layer 8-10 reasons to implement policy (are you allowed to use the network), control (we want to decide who uses the network) and attribution (if something bad happens, we want to know who did it).
Graceful Restart and Routing Protocol Convergence
I’m always amazed when I encounter networking engineers who want to have a fast-converging network using Non-Stop Forwarding (which implies Graceful Restart). It’s even worse than asking for smooth-running heptagonal wheels.
As we discussed in the Fast Failover series, any decent router uses a variety of mechanisms to detect adjacent device failure:
- Physical link failure;
- Routing protocol timeouts;
- Next-hop liveliness checks (BFD, CFM…)
New Content in AWS Networking Webinar
Last week’s update session of the AWS Networking webinar covered two hours worth of new (or not-yet-covered) features, including:
- Transit Gateway Connect functionality (GRE tunnel+BGP between Transit Gateway and in-cloud SD-WAN appliances)
- AWS Private Link
- Intra-VPC static routes that you can use to send inter-subnet traffic to a BYOD security appliance
- IGMPv2 support
- Custom global accelerators
- Assigning whole IP prefixes to VM interfaces
The recordings have already been published, either as independent videos or integrated with the existing materials. Enjoy ;)
OMG: Democratizing Network Automation
I totally understand that entities relying on sponsors have to become creative while promoting whatever theirs sponsors want to sell, but in my opinion this is a bridge too far:
[…] explore how Gluware aims to democratize automation; that is, get you quick wins around common tasks such as configuration changes and OS updates.
Democratizing automation? Because it’s authoritarian now? By providing the abilities like configuration changes and OS updates that have been available in network management tools like CiscoWorks or SolarWinds for ages?
You know what’s really hard when automating existing networks? Figuring out how to simplify them to the point where it makes sense to automate them. Will any shrink-wrapped GUI product solve that? Of course not.
Must Read: BGP Private AS Range
We all know that you have to use an AS number between 64512 and 65535 for private BGP autonomous systems, right? Well, we’re all wrong – the high end of the range is 65534, and Chris Parker wrote a nice blog post explaining the reasons behind that change.
Video: Theoretical View of Network Addressing
After explaining the basics of (network) names, addresses and routes, I wasted a few minutes of everyone’s time discussing the theoretical aspects of layered addressing, and then got back to practical issues like address scopes, namespaces, and address provisioning.
The video ends with a simple (and unappreciated) truth: if you have a point-to-point link between two nodes you don’t need data-link-layer addresses. The consequences of that fact are left as an exercise for the viewer (or you can wait till the next video ;)
Should You Build or Buy a Router?
Patrik Schindler sent me an interesting comment to my Open-Source DMVPN Alternatives blog post:
I’ve done searches myself some time ago about the readymade Linux distros supporting DMVPN and got exactly what I asked for.
Glancing over that page appalled me: Different stuff with different configuration languages, probably the need to restart things, thus generating service outages for configuration changes…
Your blog is heavily biased towards big deployments with good opportunities for automation, and the diversity of different components can be easily hidden behind automation scripts of choice. Smaller deployments are almost never being able to compensate the initial overhead of creating all the automation fuzz, and from that perspective, I must admit that configuring a Cisco router feels way more smooth to me.
Welcome to the build-or-buy dilemma, router edition.
Worth Reading: Do We Need Segment Routing?
Etienne-Victor Depasquale sent me a pointer to an interesting NANOG discussion: why would we need Segment Routing. It’s well worth reading the whole thread (until it devolves into “that is not how MPLS works” arguments), which happens to be somewhat aligned with my thinking:
- SR-MPLS makes perfect sense (excluding the migration-from-LDP fun)
- SRv6 (in whatever incantation) is mostly a vendor ploy to sell new chipsets.
Enjoy!
Graceful Restart and Other Control Plane Protocols
In the Graceful Restart 101 blog post, I promised to discuss the ugly parts of this concept in a follow-up post. It turns out we’ll need more than one; today, we’ll focus on other control plane protocols in an access network scenario.
Imagine an access router with multiple uplinks serving a bunch of non-redundantly-connected customers:
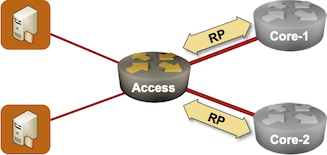
Non-redundant access network
Feedback: Mastering Cloud Networking
Most of the public cloud training seems focused on developers. No surprise there, they are the usual beachhead public cloud services need to get into large organizations. Unfortunately, once the production applications start getting deployed into public cloud infrastructure, someone has to take over operations, and that’s where the fun starts.
For whatever reason, there aren’t that many resources helping the infrastructure operations teams understand how to deal with this weird new world, at least according to the feedback Jawed left on Azure Networking webinar:
Video: Public Cloud Networking Is Different
Even though you need plenty of traditional networking constructs to deploy a complex application stack in a public cloud (packet filters, firewalls, load balancers, VPN, BGP…), once you start digging deep into the bowels of public cloud virtual networking, you’ll find out it’s significantly different from the traditional Ethernet+IP implementations common in enterprise data centers.
For an overview of the differences watch the Public Cloud Networking Is Different video (part of Introduction to Cloud Computing webinar), for more details start with AWS Networking 101 and Azure Networking 101 blog posts, and continue with corresponding cloud networking webinars.