Blog Posts in May 2021
netsim-tools release 0.7: Cumulus VX, EIGRP, and BGP IPv6 AF
netsim-tools release 0.7 is published, bringing you the following goodies (including stuff published a week ago as release 0.6.3):
- Cumulus VX support on libvirt and virtualbox.
- EIGRP configuration module
- BGP IPv6 address family
- Controlled BGP community propagation
Other changes include:
Worth Reading: Azure Datacenter Switch Failures
Microsoft engineers published an analysis of switch failures in 130 Azure regions (review of the article, The Next Platform summary):
- A data center switch has a 2% chance of failing in 3 months (= less than 10% per year);
- ~60% of the failures are caused by hardware faults or power failures, another 17% are software bugs;
- 50% of failures lasted less than 6 minutes (obviously crashes or power glitches followed by a reboot).
- Switches running SONiC had lower failure rate than switches running vendor NOS on the same hardware. Looks like bloatware results in more bugs, and taking months to fix bugs results in more crashes. Who would have thought…
Worth Reading: Running BGP in Large-Scale Data Centers
Here’s one of the major differences between Facebook and Google: one of them publishes research papers with helpful and actionable information, the other uses publications as recruitment drive full of we’re so awesome but you have to trust us – we’re not sharing the crucial details.
Recent data point: Facebook published an interesting paper describing their data center BGP design. Absolutely worth reading.
Just in case you haven’t realized: Petr Lapukhov of the RFC 7938 fame moved from Microsoft to Facebook a few years ago. Coincidence? I think not.
Video: Kubernetes Principles
After answering the “why should I care about Kubernetes?” question, Stuart Charlton explained the Kubernetes principles you should keep in mind if you want to have a chance of understanding what’s going on.
Local TCP Anycast Is Really Hard
Pete Lumbis and Network Ninja mentioned an interesting Unequal-Cost Multipathing (UCMP) data center use case in their comments to my UCMP-related blog posts: anycast servers.
Here’s a typical scenario they mentioned: a bunch of servers, randomly connected to multiple leaf switches, is offering a service on the same IP address (that’s where anycast comes from).
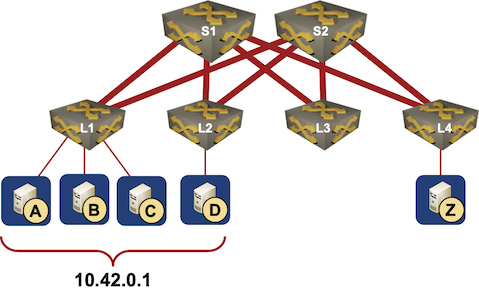
Typical Data Center Anycast Deployment
Packet Forwarding and Routing over Unnumbered Interfaces
In the previous blog posts in this series, we explored whether we need addresses on point-to-point links (TL&DR: no), whether it’s better to have interface or node addresses (TL&DR: it depends), and why we got unnumbered IPv4 interfaces. Now let’s see how IP routing works over unnumbered interfaces.
The Challenge
A cursory look at an IP routing table (or at CCNA-level materials) tells you that the IP routing table contains prefixes and next hops, and that the next hops are IP addresses. How should that work over unnumbered interfaces, and what should we use for the next-hop IP address in that case?
Mythbusting: NFV Data Center Fabric Buffering Requirements
Every now and then I stumble upon an article or a comment explaining how Network Function Virtualization (NFV) introduces new data center fabric buffering requirements. Here’s a recent example:
For Telco/carrier Cloud environments, where NFVs (which are much slower than hardware SGW) get used a lot, latency is higher with a lot of jitter due to the nature of software and the varying link speeds, so DC-level near-zero buffer is not applicable.
It seems to me we’re dealing with another myth. Starting with the basics:
Feedback: Kubernetes Networking Deep Dive
Here’s what one of the engineers watching Stuart Charlton’s Kubernetes webinar wrote about it:
“Kubernetes Networking Deep Dive” is a must see webinar. Once done take a break and then watch it again, let it sink in and then sign-up for a free account with Azure or GCP and practice all that was learned during the webinar.
At the end of this exercise … one will begin to understand why the networking domain seems to be lagging behind … This webinar will help one pick up the pace!
Worth Watching: Rethinking BGP in the Data Center
Ever since draft-lapukhov was first published almost a decade ago, we all knew BGP was the only routing protocol suitable for data center networking… or at least Thought Leaders and vendor marketers seem to be of that persuasion.
Worth Exploring: Working with Linux VRFs
I remember having an interesting discussion about Linux VRFs (as opposed to namespaces) with Dinesh Dutt years ago, but it looks like I never turned it into a blog post.
Now I won’t have to 😉 – Jon Langemak published an excellent Working with Linux VRFs deep dive.
Video: We Still Need Networking in Public Clouds
Whenever someone starts mansplaining that we need no networking when we move the workloads into a public cloud, please walk away – he has just proved how clueless he is.
He might be a tiny bit correct when talking about software-as-a-service (after all, it’s just someone else’s web site), but when it comes to complex infrastructure virtual networks, there’s plenty of networking involved, from packet filters and subnets to NAT, load balancers, firewalls, BGP and IPsec.
For more details, watch the We Still Need Networking in Public Clouds video (part of Introduction to Cloud Computing webinar).
Automation: Dealing with Vendor-Specific Configuration Keywords
One of the students in our Building Network Automation Solutions online course asked an interesting question:
I’m building an IPsec multi-vendor automation solution and am now facing the challenge of vendor-specific parameter names. For example, to select the AES-128 algorithm, Juniper uses aes-128-cbc, Arista aes128, and Checkpoint AES-128.
I guess I need a kind of Rosetta stone to convert the IKE/IPSEC parameters from a standard parameter to a vendor-specific one. Should I do that directly in the Jinja2 template, or in the Ansible playbook calling the template?
Both options are awkward. It would be best to have a lookup table mapping parameter values from the data model into vendor-specific keywords, for example:
… updated on Tuesday, August 13, 2024 07:46 +0200
Back to Basics: Unnumbered IPv4 Interfaces
In the previous blog post in this series, we explored some of the reasons IP uses per-interface (and not per-node) IP addresses. That model worked well when routers had few interfaces and mostly routed between a few LAN segments (often large subnets of a Class A network assigned to an academic institution) and a few WAN uplinks. In those days, the WAN networks were frequently implemented with non-IP technologies like Frame Relay or ATM (with an occasional pinch of X.25).
The first sign of troubles in paradise probably occurred when someone wanted to use a dial-up modem to connect to a LAN segment. What subnet (and IP address) do you assign to the dial-up connection, and how do you tell the other end what to use? Also, what do you do when you want to have a bank of modems and dozens of people dialing in?
… updated on Monday, May 24, 2021 12:05 UTC
Packet Bursts in Data Center Fabrics
When I wrote about the (non)impact of switching latency, I was (also) thinking about packet bursts jamming core data center fabric links when I mentioned the elephants in the room… but when I started writing about them, I realized they might be yet another red herring (together with the supposed need for large buffers in data center switches).
Here’s how it looks like from my ignorant perspective when considering a simple leaf-and-spine network like the one in the following diagram. Please feel free to set me straight, I honestly can’t figure out where I went astray.
netsim-tools release 0.6.2
Last week we pushed out netsim-tools release 0.6.2. It’s a maintenance release, so mostly full of bug fixes apart from awesome contributions by Leo Kirchner who
- Made vSRX 3.0 work on AMD CPU (warning: totally unsupported).
- Figured out how to use vagrant mutate to use virtualbox version of Cisco Nexus 9300v Vagrant box with libvirt
Other bug fixes include:
- Numerous fixes in Ansible installation playbook
- LLDP on all vSRX interfaces as part of initial configuration
- Changes in FRR configuration process to use bash or vtysh as needed
- connect.sh executing inline commands with docker exec
Worth Reading: Rethinking Internet Backbone Architectures
Johan Gustawsson wrote a lengthy blog post describing Telia’s approach to next-generation Internet backbone architecture… and it’s so refreshing seeing someone bringing to life what some of us have been preaching for ages:
- Simplify the network;
- Stop cramming ever-more-complex services into the network;
- Bloated major vendor NPUs implementing every magic ever envisioned are overpriced – platforms like Broadcom Jericho2 are good enough for most use cases.
- Return from large chassis-based stupidities to network-centric high availability.
I don’t know enough about optics to have an opinion on what they did there, but it looks as good as the routing part. It would be great to hear your opinion on the topic – write a comment.
Video: Cisco SD-WAN Site Design
In the Site Design part of Cisco SD-WAN webinar, David Penaloza described capabilities you can use when designing complex sites, like extending SD-WAN transport between SD-WAN edge nodes, or implementing high availability between them. He also explained how to track an Internet-facing interface and a service beyond its next hop.
Does Small Packet Forwarding Performance Matter in Data Center Switches?
TL&DR: No.
Here’s another never-ending vi-versus-emacs-type discussion: merchant silicon like Broadcom Trident cannot forward small (64-byte) packets at line rate. Does that matter, or is it yet another stimulating academic talking point and/or red herring used by vendor marketing teams to justify their high prices?
Here’s what I wrote about that topic a few weeks ago:
… updated on Tuesday, August 13, 2024 07:26 +0200
Back to Basics: The History of IP Interface Addresses
In the previous blog post in this series, we figured out that you might not need link-layer addresses on point-to-point links. We also started exploring whether you need network-layer addresses on individual interfaces but didn’t get very far. We’ll fix that today and discover the secrets behind IP address-per-interface design.
In the early days of computer networking, there were three common addressing paradigms:
BGP-Free MPLS Core with Segment Routing
After I created the Segment Routing lab to test the relationship between Node Segment ID (SID) and MPLS labels, I was just a minor step away from testing BGP-free core with SR-MPLS.
I added two nodes to my lab setup, this time using IOSv as those nodes need nothing more than EBGP support (and IOSv is tiny compared to IOS XE on CSR):
Response: There's No Recipe for Success
Minh Ha left a lengthy comment to my There’s No Recipe for Success blog post, adding an interesting perspective of someone who had to work really hard to overcome coming from a third-world country.
Ivan, I happened to read “Deep Work: Rules for Focused Success in a Distracted World” recently so I can attest that it does provide some valuable advices on how to do things well. Some of the overarching themes are stay focused and cut off unnecessary noise/drain the shallow. The author also suggests removing your social media account if you can’t see how it add values to your work/business, as social media can create attention disorder, seen in many young kids these days.
Worth Reading: When Stretching Layer Two, Separate Your Fate
Ethan Banks wrote the best one-line description of the crazy stuff we have to deal with in his When Stretching Layer Two, Separate Your Fate blog post:
No application should be tightly coupled to an IP address. This common issue should really be solved by application architects rebuilding the app properly instead of continuing like it’s 1999 while screaming YOLO.
Not that his (or my) take on indisputable facts would change anything… At least we can still enjoy a good rant ;)
Worth Reading: My Secret Startup Past
If you ever get a feeling the grass is greener on the other (startup) side, read My Secret Startup Past by Amy Hoy, and if you think about starting your business, read all the other stuff she wrote. I wish I knew of her when I was starting ipSpace.net a decade ago.
Video: IP Routing Fundamentals
A few weeks ago we covered transparent bridging fundamentals, now it’s time to recap IP routing fundamentals… and then we’ll be ready to compare the two.
Real-Life: How to Start Your Automation Journey
I love hearing real-life “how did I start my automation journey” stories. Here’s what one of ipSpace.net subscribers sent me:
- Make peace with your network engineering soul and mind and open up to the possibility that the world has moved on to something else when it comes to consuming apps and software. Back in 2017, this was very hard on me :)
Back to Basics: Do We Need Interface Addresses?
In the world of ubiquitous Ethernet and IP, it’s common to think that one needs addresses in packet headers in every layer of the protocol stack. We have MAC addresses, IP addresses, and TCP/UDP port numbers… and low-level addresses are assigned to individual interfaces, not nodes.
Turns out that’s just one option… and not exactly the best one in many scenarios. You could have interfaces with no addresses, and you could have addresses associated with nodes, not interfaces.
Segment Routing Segment IDs and MPLS Labels
In one of my introductory Segment Routing videos, I made claims along the lines of “Segment Routing totally simplifies the MPLS control plane, replacing LDP and local labels allocated to various prefixes with globally managed labels advertised in IGP”
It took two years for someone to realize the stupidity over-simplification of what I described. Matjaž Strauss sent me this kind summary of my errors:
You’re effectively claiming that SRGB has to be the same across all devices in the network. That’s not true; routers advertise SIDs and must configure label swap operations in case SRGBs don’t match.
Wait, what? What is SRGB and why could it be different across devices in the same network? Also, trust IETF to take a simple idea and complicate it to support vendor whims.
Feedback: Microsoft Azure Networking
Azure and AWS have decent documentation (I always found it relatively easy to figure out what they’re doing), but what they implemented is sometimes so far away from what we’re used to that it’s hard to bridge the gap. Here’s how Olle Wilhelmsson solved that challenge:
I would just like to send a huge thank you, I’ve been a fan of your appearances on tech field day as a voice of reason, and different podcasts all around. Happy to finally be able to contribute and purchase an IPspace subscription, and was not disappointed.
This series on Azure networking was fantastic, it’s been frustrating to find any kind of good material on this topic. Even if Microsofts documentation is generally good, they really don’t have any resources to compare it to “regular” networking in physical equipment. So just a huge thank you, this has definitely saved me countless hours of reading and googling questions!
RFC 7868: The Definitive EIGRP Guide
Seventeen years after I started working on my EIGRP book, the reverse engineering days were over: RFC 7868 is the definitive guide to modern EIGRP (I’m not familiar with at least half of the concepts mentioned in it).
Just in case you’re interested in a bit of historical trivia:
- My EIGRP deciphering history started a few years before the book was published. In mid-1990s I was asked (as an external trainer) to create an EIGRP course for Cisco EMEA Training.
- I’ve never seen any internal EIGRP documentation or code – everything I knew about EIGRP I’ve learned from trying out crazy stuff and deciphering debugging messages.
- Two of the RFC authors (Russ White and Don Slice) were the technical reviewers for my EIGRP book. Russ copiously rewrote my pidgin English into something understandable – if you like reading my blog posts today, you should (also) thank Russ.