Blog Posts in April 2013
Open vSwitch Under the Hood
Hatem Naguib claimed that “the NSX controller cluster is completely out-of-band, and never handles a data packet” when describing VMware NSX Network Virtualization architecture, preemptively avoiding the “flow-based forwarding doesn’t scale” arguments usually triggered by stupidities like this one.
Does that mean there’s no packet punting in the NSX/Open vSwitch world? Not so fast.
They want networking to be utility? Let’s do it!
I was talking about virtual firewalls for almost an hour at the Troopers13 conference, and the first question I got after the presentation was “who is going to manage the virtual firewalls? The networking team, the security team or the virtualization team?”
There’s the obvious “silos don’t work” answer and “DevOps/NetOps” buzzword bingo, but the real solution requires everyone involved to shift their perspective.
Virtual Firewall presentation from Troopers 13
The 45 minute virtual firewalls presentation I had at Troopers 13 is now available online. The virtual firewalls webinar is an in-depth 2,5 hour version that includes numerous product architectures.
You can get all my recent public presentations and a list of upcoming events on my web site.
Why are 3G networks so slow?
More than four years ago one of my friends wrote about uselessness of UMTS connections (the page has decayed into digital wasteland in the meantime) for inter-router backup links and although I got numerous comments trying to explain the issues I never found a good explanation that a simplistic networking engineer like me could understand.
Ilya Grigorik fixed that. His Breaking the 1000 msec Time-to-Glass Mobile Barrier talk has some real-world statistics, and a fantastic description of how 3G/4G networks work and what causes the enormous latencies. His High Performance Browser Networking book has even more details. Enjoy!
Resiliency of VM NIC firewalls
Dmitry Kalintsev left a great comment on my security paradigm changing post:
I have not yet seen redundant VNIC-level firewall implementations, which stopped me from using [...] them. One could argue that vSwitches are also non-redundant, but a vSwitch usually has to do stuff much less complex than what a firewall would, meaning chances or things going south are lower.
As always, things are not purely black-and-white and depend a lot on the product architecture and implementation.
Virtual Appliance Performance Is Becoming a Non-Issue
Almost exactly two years ago I wrote an article describing the benefits and drawbacks of virtual appliances, where I listed virtualization overhead as one of the major sore spots (still partially true). I also wrote: “Implementing routers, switches or firewalls in a virtual appliance would just burn the CPU cycles that could be better used elsewhere.” It’s time to revisit this claim.
NETCONF+YANG+NETMOD versus SMI-S
With all the Puppet buzz I’m hearing and claims that “compute and storage orchestration problems have been solved” I wanted to check the reality of those claims – is it (for example) possible to create a LUN on a storage array using a standard well-defined API.
Stephen Foskett, Simon Gordon and Scott Lowe quickly pointed me in the right direction: SMI-S. Thank you!
Get my RSS feed into your Inbox
One of my readers wanted to receive my RSS feed as daily email messages. There’s no obvious way to do it, but (as always) there’s a kludge:
- Select Subscribe to ... Posts on any page of my blog;
- Selecting Atom as the subscription format brings you to my Feedburner feed (unless you’ve installed RSS/Atom browser extensions);
- Select Get ipSpace.net delivered by email in the Subscribe Now! Box
TCP and HTTP deep(er) dive Q&A
The deep dive into TCP and HTTP mechanisms that impact web application performance triggered numerous questions during the live webinar session – it took me almost 10 minutes to answer them all.
TCP and HTTP deep(er) dive
In the first part of the TCP, HTTP and SPDY webinar I explained why TCP and HTTP impact the end-to-end web application performance. In the second section of the webinar, we did a deep dive into the actual TCP and HTTP mechanisms that increase end-to-end latency (3-way handshake, initial congestion window, request/response nature of HTTP).
VXLAN scalability challenges
VXLAN, one of the first MAC-over-IP (overlay) virtual networking solutions is definitely a major improvement over traditional VLAN-based virtual networking technologies … but not without its own scalability limitations.
VM BPDU spoofing attack works quite nicely in HA clusters
When I wrote the Virtual switches need BPDU guard blog post, I speculated that you could shut down a whole HA cluster with a single BPDU-generating VM ... and got a nice confirmation during the Troopers 13 conference – ERNW specialists successfully demonstrated the attack while testing the security aspects of a public cloud implementation for a major service provider.
For more information, read their blog post (they also have a nice presentation explaining how a VM can read ESXi hard drive with properly constructed VMDK file).
This Is What Makes Networking So Complex
The responses to my What did you do to get rid of manual VLAN provisioning post were easy to predict: a few people sharing their best practices (thank you!), few musings on the future of SDN/networking, and the ubiquitous anonymous rant against stubbornness and stupidity of networking engineers and their OPEX.
I know one should never feed anonymous trolls, but this morsel is simply too juicy to pass, so here it is – let’s see what makes networking so complex.
Compromised Security Zone = Game Over (Or Not?)
Kevin left a pretty valid comment to my Are you ready to change your security paradigm blog post:
I disagree that a compromised security zone is game over. Security is built in layers. Those host in a compromised security zone should be hardened, have complex authentication requirements to get in them, etc. Just because a compromised host in a security zone can get at additional ports on the other hosts doesn't mean an attacker will be more successful.
He’s right from the host-centric perspective (assuming you actually believe those other hosts are hardened), but once you own a server in a security zone you can start having fun with intra-subnet attacks.
Kickstart free CCNA and CCNP videos!
Andrew Crouthamel had a great idea – he decided to produce free CCNA-level videos and started a Kickstart campaign to get the funding. The initial response was overwhelming, so he included stretch goals: Wireshark training (WCNA – already reached) and CCNP.
He probably underestimated the costs of the project, but that doesn’t really matter. I’m positive he’ll deliver, so let’s help him get started – if only 10% of my readers donate a single morning Frapuccino to his project, he’ll have more than enough funding to get the whole CCNP curriculum done.
464XLAT Explained
IETF recently published RFC 6877 (464XLAT) describing a dual-translation mechanism that allows an IPv6 host (or CPE) in an IPv6-only access network to pretend it still has IPv4 connectivity. Why would one need a kludge ingenious solution like this? In a word: Skype.
For more details, watch the video explaining the need for 464XLAT and two typical use cases: Android handset and a CPE device (example: SOHO router with 3G uplink).
Load Balancing Across Multiple MPLS/VPN Providers
Arnold sent me an interesting challenge: he’s using two MPLS/VPN providers, with most sites being connected to both providers. He’d like to load balance the inter-site traffic across all PE-CE links – an easy task if you’re using RIP, OSPF or EIGRP as the PE-CE routing protocol, but he happens to be using BGP.
Are you ready to change your security paradigm?
Most application stacks built today rely on decades-old security paradigm: individual components of the stack (web servers, app servers, database servers, authentication servers ...) are placed in different security zones implemented with separate physical devices, VLANs or some other virtual networking mechanism of your choice.
The security zones are then connected with one or more firewalls (when I was young we used routers with packet filters), resulting in a crunchy edge with squishy core architecture.
The First Glimpse of Open Daylight
Operating systems are boring (for most people); it’s the applications that make everyone excited. SDN is no different. Controllers are boring – someone has to reinvent all the wheels that the networking vendors have been inventing for the last 30 years before you can develop the sexy stuff ... but not many people outside of ivory towers would start developing the (supposedly) sexy SDN apps until being sure the underlying platform will not disappear into thin air.
Blame the firewall!

Another great documentary from Scott Adams. Source: dilbert.com
Why TCP and HTTP affect web application performance
In the ideal world, you’d get a new web page within 100 milliseconds of clicking an active web page component (link, button ...). Reality is way harsher – sometimes it takes seconds till you can enjoy a web page served from a well-behaved web server (let’s pretend there are no server performance issues).
In the first part of my TCP, HTTP and SPDY webinar I explained how the transport mechanisms (TCP and HTTP) impact the end-to-end web application performance and what you could do to reduce the web page loading time.
The Many Paths to SDN
I did a major overhaul of my RIPE 65 SDN presentation prior to MENOG 12 meeting, including a more comprehensive overview of SDN-related technologies sorted by the networking device plane they operate on.
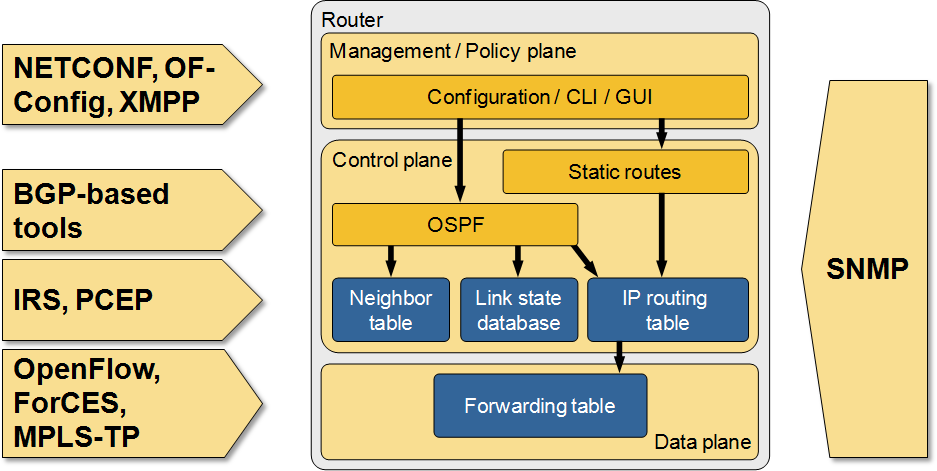
Many paths to SDN
The Impact of Changed NHRP Behavior in DMVPN Networks
Two years ago I wrote the another Fermatish post: I described how NHRP behavior changed in DMVPN networks using NAT and claimed that it might be a huge problem, without ever explaining what the problem is.
Fabrice quickly identified the problem, but it seems the description was not explicit enough as I’m still getting queries about that post, so here’s a step-by-step description of what’s going on.
VLANs are the wrong abstraction for virtual networking
Are you old enough to remember the days when operating systems had no file system? Fortunately I never had to deal with storing files on one of those (I was using punch cards), but miraculously you can still find the JCL DLBL/EXTENT documentation online.
On the other hand, you probably remember the days when a SCSI LUN actually referred to a physical disk connected to a computer, not an extensible virtual entity created through point-and-click exercise on a storage array.
You might wonder what the ancient history has to do with virtual networking. Don’t worry we’re getting there in a second ;)