Blog Posts in March 2012
Cisco & VMware: Merging the Virtual and Physical NICs
Virtual (soft) switches present in almost every hypervisor significantly reduce the performance of high-bandwidth virtual machines (measurements done by Cisco a while ago indicate you could get up to 38% more throughput if you tie VMs directly to hardware NICs), but as I argued in my “Soft Switching Might Not Scale, But We Need It” post, we need hypervisor switches to isolate the virtual machines from the vagaries of the physical NICs.
Engineering gurus from Cisco and VMware have yet again proven me wrong – you can combine VMDirectPath and vMotion if you use VM-FEX.
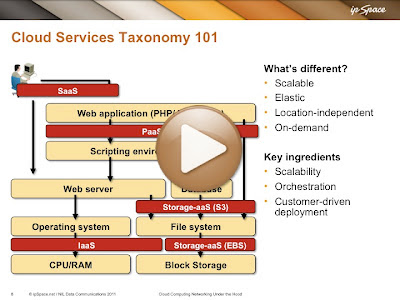
Cloud Services Taxonomy
One of the challenges of designing data center networks that support cloud service is agreeing on what exactly each one of those services should be doing. This video (part of the Cloud Computing Networking webinar) explains what various categories of cloud services actually do and where they could be used in a typical web application stack.
Migrating from Phase 1 DMVPN to Phase 2/3 Network
Chris sent me an interesting question that I haven’t covered in any of my DMVPN webinars: “How would you migrate a part of a Phase-1 DMVPN network to a Phase-2 or Phase-3 network if you can only migrate one spoke site at a time? Can I just upgrade the spokes that need spoke-to-spoke connectivity?”
While it might be theoretically possible to have a mixed Phase-1/Phase-2 DMVPN tunnel (and I just might be able to get it to work in a lab), such a solution definitely violates the KISS principle.
Stretched Layer-2 Subnets – The Server Engineer Perspective
A long while ago I got a very interesting e-mail from Dmitriy Samovskiy, the author of VPN-Cubed, in which he politely asked me why the networking engineers find the stretched layer-2 subnets so important. As we might get lucky and spot a few unicorns merrily dancing over stretched layer-2 rainbows while attending the Networking Tech Field Day, I decided share the e-mail contents with you (obviously after getting an OK from Dmitriy).
Looking into Data Center Storage Protocols mysteries
Should you use FC, FCoE or iSCSI when deploying new gear in your existing data center? What about Greenfield deployments? What are the decision criteria? Should you just skip iSCSI and use NFS if you’re focusing on server virtualization with VMware? Does it still make sense to build separate iSCSI network? Are jumbo frames useful? We’ll try to answer all these questions and a few more in the first Data Center Virtual Symposium sponsored by Cisco Systems.
Video: Networking requirements for VM mobility
You’re probably sick and tired of me writing and talking about networking requirements for VM mobility (large VLAN segments that some people want to extend across the globe), but just in case you have to show someone a brief summary, here’s a video taken from the Data Center Fabric Architectures webinar.
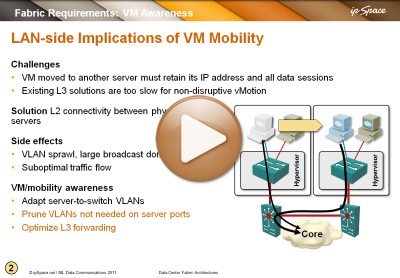
You’ll also find VM mobility challenges described to various degrees in Introduction to Virtual Networking, VMware Networking Deep Dive and Data Center Interconnects webinars
… updated on Friday, December 25, 2020 18:17 UTC
Scalable, Virtualized, Automated Data Center
Matt Stone sent me a great set of questions about the emerging Data Center technologies (the headline is also his, not mine) together with an interesting observation “it seems as though there is a lot of reinventing the wheel going on”. Sure is – read Doug Gourlay’s OpenFlow article for a skeptical insider view. Here's a lovely tidbit:
So every few years the networking industry invents some new term whose primary purpose is to galvanize the thinking of IT purchasers, give them a new rallying cry to generate budget, hopefully drive some refresh of the installed base so us vendor folks can make our quarter bookings targets.
But I’m digressing, let’s focus on Matt’s questions. Here are the first few.
MPLS/VPN in the Data Center? Maybe not in the hypervisors
A while ago I wrote that the hypervisor vendors should consider turning the virtual switches into PE-routers. We all know that’s never going to happen due to religious objections from everyone who thinks VLANs are the greatest thing ever invented and MP-BGP is pure evil, but there are at least two good technical reasons why putting MPLS/VPN (as we know it today) in the hypervisors might not be the best idea in very large data centers.
Do we really need Stateless Transport Tunneling (STT)
The first question everyone asked after Nicira had published yet another MAC-over-IP tunneling draft was probably “do we really need yet another encapsulation scheme? Aren’t VXLAN or NVGRE enough?” Bruce Davie tried to answer that question in his blog post (and provided more details in another one), and I’ll try to make the answer a bit more graphical.
VXLAN and EVB questions
Wim (@fracske) De Smet sent me a whole set of very good VXLAN- and EVB-related questions that might be relevant to a wider audience.
If I understand you correctly, you think that VXLAN will win over EVB?
I wouldn’t say they are competing directly from the technology perspective. There are two ways you can design your virtual networks: (a) smart core with simple edge (see also: voice and Frame Relay switches) or (b) smart edge with simple core (see also: Internet). EVB makes option (a) more viable, VXLAN is an early attempt at implementing option (b).
Knowledge and Complexity
In almost every field of IT lots of people try to do their job relying on uncle Google and his friends (bloggers, forum wizards and other content producers) and cut-and-paste solutions found on the web into their programs, server- or device configurations. Here’s my theory why that might be the case; please feel free to shoot it down in flames.
Designing Scalable Web Applications: Introduction
My regular readers probably know that I’m running a 4-month course in scalable web application design at University of Ljubljana (everyone else will find more details here). I was extremely surprised when we started – I’d expected to see about a dozen students, and suddenly realized I was standing in front of a totally crowded classroom. The next amazing surprise was the students’ level of motivation, commitment, knowledge, and the quality of their questions. It’s definitely fun to have an audience like that.
Grumpy Monday: HP and OpenFlow
HP has recently released OpenFlow support on a few more switches and some people think it’s a big deal. It just might be if you’re a researcher with limited grant budget (which seems to be one of the major OpenFlow use cases today); for everyone else, it’s a meh. Lacking a commercial-grade OpenFlow controller supported by HP (or at least tested with HP switches), OpenFlow on HP switches remains a shiny new toy.
OpenFlow: A perfect tool to build SMB data center
When I was writing about the NEC+IBM OpenFlow trials, I figured out a perfect use case for OpenFlow-controlled network forwarding: SMB data centers that need less than a few hundred physical servers – be it bare-metal servers or hypervisor hosts (hat tip to Brad Hedlund for nudging me in the right direction a while ago)
Do we need DHCPv6 Relay Redundancy?
Instead of drinking beer and lab-testing vodka during the PLNOG party I enjoyed DHCPv6 discussions with Tomasz Mrugalski, the “master-of-last-resort” for the ISC’s DHCPv6 server. I mentioned my favorite DHCPv6 relay problem (relay redundancy) and while we immediately agreed I’m right (from the academic perspective), he brought up an interesting question – is this really an operational problem?
Don’t forget to secure the IPv6 management plane
One of the few presentations I could understand @ PLNOG meeting yesterday (most of them were in Polish) was the fantastic “Guide To Building Secure Network Infrastructures” by Merike Kaeo, during which she revealed an obvious but oft forgotten fact: by deploying IPv6 in your router, you’ve actually created a parallel entry into the management plane that has to be secured using the same (or similar) mechanisms as its IPv4 counterpart.
All EuroNOG presentations are available online
As you know, I’m back in Poland, this time attending PLNOG. Meeting the wonderful team of the PLNOG organizers brought back old memories and I figured out I haven’t blogged about the Euronog videos they started publishing late last year. The last time I checked their web site only a few videos were available. Imagine my surprise when I figured out almost all the presentations they recorded are now available for download.
My first Internet Draft has just been published
While I was discussing the intricacies of Cisco’s IPv6 implementation with Gunter Van de Velde a while ago, he suddenly changed hats and asked me whether I would be willing to contribute to a BGP filtering best practices draft. I’m still too young to realize it’s not a good idea to say YES every time you see something interesting and immediately accepted the challenge.
Published on , commented on March 10, 2023
Anyone Can Get IPv6 PI Space – Buy More RAM and TCAM?
Till a few weeks ago, you could get provider-independent (PI) IPv6 address space in RIPE region only if you “demonstrated that you’ll be multihomed”, which usually required having nothing more than an AS number. With the recent policy change, anyone can get PI address space (and this is why you should get it) as long as they have a sponsoring LIR, and the yearly fee for an independent resource (RIPE-to-LIR) is €50.