Category: QoS
Can We Just Throw More Bandwidth at a Problem?
One of my readers sent me an interesting question:
I have been reading at many places about "throwing more bandwidth at the problem." How far is this statement valid? Should the applications(servers) work with the assumption that there is infinite bandwidth provided at the fabric level?
Moore’s law works in our favor. It’s already cheaper (in some environments) to add bandwidth than to deploy QoS.
FCoE and Nexus 1000v QoS
One of my readers wanted to deploy FCoE on UCS in combination with Nexus 1000v and wondered how the FCoE traffic impacts QoS on Nexus 1000v. He wrote:
Let's say I want 4Gb for FCoE. Should I add bandwidth shares up to 60% in the nexus 1000v CBWFQ config so that 40% are in the default-class as 1kv is not aware of FCoE traffic? Or add up to 100% with the assumption that the 1kv knows there is only 6Gb left for network? Also, will the Nexus 1000v be able to detect contention on the uplink even if it doesn't see the FCoE traffic?
As always, things aren’t as simple as they look.
Queuing Mechanisms in Modern Switches
A long while ago there was an interesting discussion started by Brad Hedlund (then at Dell Force10) comparing leaf-and-spine (Clos) fabrics built from fixed-configuration pizza box switches with high-end chassis switches. The comments made by other readers were all over the place (addressing pricing, wiring, power consumption) but surprisingly nobody addressed the queuing issues.
This blog post focuses on queuing mechanisms available within a switch; the next one will address end-to-end queuing issues in leaf-and-spine fabrics.
Overlay Networks and QoS FUD
One of the usual complaints I hear whenever I mention overlay virtual networks is “with overlay networks we lose all application visibility and QoS functionality” ... that worked so phenomenally in the physical networks, right?
RSVP over DMVPN
A while ago Tomasz Kacprzynski asked me whether I’d ever run RSVP over DMVPN. I hadn’t - after all, you’d only need that in VoIP environments and I try to stay as far away from voice as possible.
In the meantime, Tomasz solved the problem (short summary: you have to turn Phase 3 DMVPN into Phase 2 DMVPN) and wrote a lengthy blog post describing the problem (RSVP split horizon rule) and his solution (including numerous debugging printouts). Definitely worth reading if there’s a non-zero chance you’ll have to get the two working together.
… updated on Thursday, November 19, 2020 12:17 UTC
iSCSI with PFC?
Nicolas Vermandé sent me a really interesting question: “I've been looking for answers to a simple question that even different people at Cisco don't seem to agree on: Is it a good idea to class IP traffic (iSCSI or NFS over TCP) in pause no-drop class? What is the impact of having both pauses and TCP sliding windows at the same time?”
Quality of Service in ProgrammableFlow Networks
OpenFlow is not exactly known for its quality-of-service features (hint: there are none), but as I described in the ProgrammableFlow Technical Deep Dive webinar NEC implemented numerous OpenFlow extensions in their edge switches and the ProgrammableFlow controller to give you a robust set of QoS features.
Juniper MX Routers – all you ever wanted to know
During a recent ExpertExpress engagement I got an interesting question: “could we do per-customer policing and shaping on an MX-80 if we want to offer VPLS services and have Q-in-Q encapsulation on customer-facing links?” As I have preciously little Junos/MX knowledge, it was time for the classic “I’ll get back to you” reply and some heavy research.
You probably know how hard it is to find in-depth information on an unknown platform running unfamiliar software. Fortunately, Doug Hanks (@douglashanksjr) sent me a review copy of his new Juniper MX Series book a while ago. It was time for some serious reading.
The best of RIPE65
Last week I had the privilege of attending RIPE65, meeting a bunch of extremely bright SP engineers, and listening to a few fantastic presentations (full meeting report @ RIPE65 web site).
I knew Geoff Huston would have a great presentation, but his QoS presentation was even better than I expected. I don’t necessarily agree with everything he said, but every vendor peddling QoS should be forced to listen to his explanation of the underlying problems and kludgy solutions first.
Bandwidth-On-Demand: Is OpenFlow the Silver Bullet?
Whenever the networking industry invents a new (somewhat radical) technology, bandwidth-on-demand seems to be one of the much-touted use cases. OpenFlow/SDN is no different – Juniper used its OpenFlow implementation (Open vSwitch sitting on top of Junos SDK) to demonstrate Bandwidth Calendaring (see Dave Ward’s presentation @ OpenFlow Symposium for more details), and Dmitri Kalintsev recently blogged “How about an ability for things like Open vSwitch ... to actually signal the transport network its connectivity requirements ... say desired bandwidth” I have only one problem with these ideas: I’ve seen them before.
Some More QoS Basics
I got a really interesting question from one of my readers (slightly paraphrased):
Is this a correct statement: QoS on a WAN router will always be on if there are packets on the wire as the line is either 100% utilized or otherwise nothing is being transmitted. Comments like “QoS will kick in when there is congestion, but there is always congestion if the link is 100% utilized on a per moment basis” are confusing.
Well, QoS is more than just queuing. First you have to classify the packets; then you can perform any combination of marking, policing, shaping, queuing and dropping.
QoS in Large-Scale DMVPN Networks
Got this question a few days ago:
I have a large DMVPN network (~ 1000 sites) using variety of DSL, cable modem, and wireless connections. In all of these cases the bandwidth is extremely dissimilar and even varies with time. How can I handle this in a scalable way?
Hub-to-spoke QoS implementations in DMVPN networks usually use one of the following options:
Changing IP precedence values in router-generated pings
When I was testing QoS behavior in MPLS/VPN-over-DMVPN networks, I needed a traffic source that could generate packets with different DSCP/IP precedence values. If you have enough routers in your lab (and the MPLS/DMVPN lab that was used to generate the router configurations you get as part of the Enterprise MPLS/VPN Deployment and DMVPN: From Basics to Scalable Networks webinars has 8 routers), it’s usually easier to use a router as a traffic source than to connect an extra IP host to the lab network. Task-at-hand: generate traffic with different DSCP values from the router.
End-to-End QoS marking in MPLS/VPN-over-DMVPN networks
I got a great question in one of my Enterprise MPLS/VPN Deployment webinars when I was describing how you could run MPLS/VPN across DMVPN cloud:
That sounds great, but how does end-to-end QoS work when you run IP-over-MPLS-over-GRE-over-IPSec-over-IP?
My initial off-the-cuff answer was:
Well, when the IP packet arriving through a VRF interface gets its MPLS label, the IP precedence bits from the IP packet are copied into the MPLS EXP (now TC) bits. As for what happens when the MPLS packet gets encapsulated in a GRE packet and when the GRE packet is encrypted… I have no clue. I need to test it.
Data Center Bridging (DCB) Congestion Notification (802.1Qau)
The last (and the least popular) Data Center Bridging (DCB) standard tries to solve the problem of congestion in large bridged domains (PFC enables lossless transport and ETS standardizes DWRR queuing). To illustrate the need for congestion control, consider a simple example shown in the following diagram:
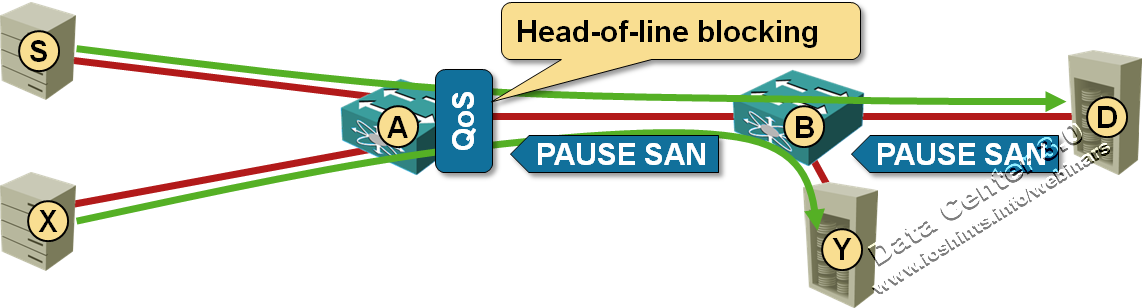
It came to my attention that a vendor might be using this blog post to justify the need for QCN in FCoE environments. Should that be the case, please make sure you also read about the difference between dense and sparse FCoE, the (lack of) need for QCN in FCoE and whether it makes sense to run FCoE over TRILL. Finally, consider how you’ll troubleshoot FCoE environments.