Category: load balancing
Microsoft Network Load Balancing Behind the Scenes
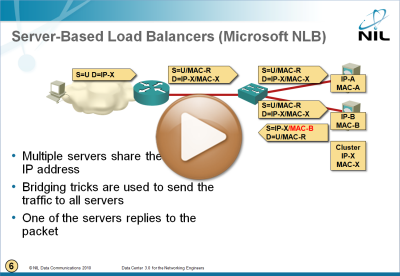
I figured out I wrote a lot about Microsoft Network Load Balancing (NLB) without ever explaining how that marvel of engineering works. To fix that omission, here’s a short video taken from the Data Center 3.0 webinar.
… updated on Tuesday, November 17, 2020 16:49 UTC
IP Renumbering in Disaster Avoidance Data Center Designs
It’s hard for me to admit, but there just might be a corner use case for split subnets and inter-DC bridging: even if you move a cold VM between data centers in a controlled disaster avoidance process (moving live VMs rarely makes sense), you might not be able to change its IP address due to hard-coded IP addresses, be it in application code or configuration files.
Disaster recovery is a different beast: if you’ve lost the primary DC, it doesn’t hurt if you instantiate the same subnet in the backup DC.
OpenFlow and the State Explosion
While everyone deeply involved with OpenFlow agrees it’s just a low-level tool that can’t solve problems we couldn’t solve in the past (just like replacing Tcl with C++ won’t help you prove P = NP), occasionally you stumble across mindboggling ideas that are so simple you have to ask yourself: “were we really that stupid?” One of them that obviously impressed James Hamilton is the solution to load balancing that requires no load balancers.
Before clicking Read more, watch this video and try to figure out what the solution is and why we’re not using it in large-scale networks.
Do I need IPv6 in my Enterprise (again)
Ethan Banks, one of the masterminds behind the Packet Pushers podcast, wrote a spot-on blog describing why enterprises don’t deploy IPv6. Unfortunately, most of the enterprise networking engineers follow the same line of reasoning, and a few of them might feel like the proverbial deer caught in the headlights once something totally unexpected happen ... like their CEO vacationing in China, getting only IPv6 address on the iPhone, and thus not being able to access a mission-critical craplication. For a longer-term perspective, read an excellent reply written by Tom Hollingsworth.
Multisite Clusters Done Right... by None Other than Microsoft
I had to check the Microsoft clustering terminology a few days ago, so I used Google to find the most relevant pages for “Windows cluster” and landed on the Failover clustering home page where the Multisite Clustering link immediately caught my attention. Dreading the humongous amount of layer-2 DCI stupidities that could lurk hidden behind such a concept, I barely dared to click on the link… which unveiled one of the most pleasant surprises I’ve got from an IT vendor in a very long time.
6-to-4 load balancing is not NAT64
Every time I write about lack of commercial NAT64 products (yeah, I know Juniper had one for a long time and Brocade just rolled out ADX code), someone tells me that company X has field-proven NAT64 product ... only most of them are really 6-to-4 load balancers. Let’s see what the difference is.
Distributed Firewalls: a Ticking Bomb
Are you ever asked to use a layer-2 Data Center Interconnect to implement distributed active-active firewalls, supposedly solving all the L3 issues and asymmetrical-traffic-flow-over-stateful-firewalls problems? Don’t be surprised; I was stupid enough (or maybe just blinded by the L2 glitter) in 2010 to draw the following diagram illustrating a sample use of VPLS services:
Brocade VCS fabric has almost-perfect load balancing
Short summary for differently-attentive: proprietary load balancing Brocade uses over ISL trunks in VCS fabric is almost perfect (and way better for high-throughput sessions than what you get with other link aggregation methods).
During the Data Center Fabrics Packet Pushers Podcast we’ve been discussing load balancing across aggregated inter-switch links and Brocade’s claims that its “chip-based balancing” performs better than standard link aggregation group (LAG) load balancing. Ever skeptical, I said all LAG load balancing is chip-based (every vendor does high-speed switching in hardware). I also added that I would be mightily impressed if they’d actually solved intra-flow packet scheduling.
IPv6-Enabling Your Legacy Applications with F5 BIG-IP LTM
In every enterprise-focused IPv6 presentation, including my Enterprise IPv6 – the first steps webinar, I’m telling the attendees that they can easily make their legacy applications reachable over IPv6 with a little help from F5 load balancers. After all, Facebook is doing exactly that, so it should work (in theory)… but as we all know, in practice, the theory and practice are wildly different.
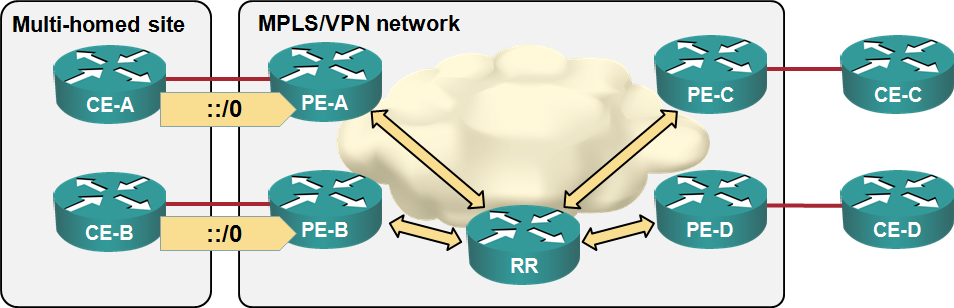
Load sharing in MPLS/VPN networks with route reflectors
Some of the e-mails and comments I received after writing the “Changing VPNv4 route attributes” post illustrated common MPLS/VPN misconceptions, so it’s worth addressing them in a series of posts. Let’s start with the simplest scenario: load balancingsharing toward a multi-homed customer site. We’ll use a very simple MPLS/VPN network with three customer sites, four CE-routers, four PE-routers a route reflector:
MLAG and Load Balancing
FullMesh added an excellent comment to my Multi-Chassis Link Aggregation (MLAG) and hot potato switching post. He wrote:
If there are two core routing switches and two access switches which are MLAGged together in both directions, and hosts that are dual-active LAGged to the pair of access switches, then the traffic would stay on whichever side the host places it.
He also opened another can of worms: load balancing in MLAG environment is dictated by the end hosts. It doesn’t pay to have fancy switches that support L3 or L4 load balancing; a stupid host implementing destination-MAC-address-based load balancing can easily ruin your day.
Load Sharing 101 (with References)
It looks like my load sharing posts did not paint the whole picture; I’m always assuming the readers have a basic level of IP routing knowledge (somewhere around BSCI/CCNP) and jump into juicy details. Let’s try to fix this error and start from the beginning. For more details, watch the How Networks Really Work webinar.
A router receives its routing information (reachability of IP prefixes) from various sources: connected IP prefixes, static routes and dynamic routing protocols. For every IP prefix, the best source (= one with the lowest administrative distance) is selected and only the route(s) from that source are included in the IP routing table.
EBGP Load Balancing with a Multihop EBGP Session
Multihop EBGP sessions are the traditional way to implement EBGP load balancing on parallel links. EBGP session is established between loopback interfaces of adjacent routers (see the next diagram; initial router configurations are included at the bottom of the article) and static routes (or an extra instance of a dynamic routing protocol) are used to achieve connectivity between loopback interfaces (BGP next-hops). The load balancing is an automatic result of the recursive route lookup of BGP next hops.
EBGP Multipath Load Sharing and CEF
When I was discussing the details of the BGP troubleshooting video with one of my readers, he pointed out that I should mention the need for CEF switching in EBGP multipath scenario. My initial response was “Why would you need CEF? EBGP multipath is older than CEF” and his answer told me I should turn on my gray cells before responding to emails: “Your video as well as Cisco’s web site recommends CEF for EBGP multipath design… but interestingly, it does work without CEF”.
The real reason we need CEF in EBGP load sharing designs is the efficacy of load distribution. Without CEF, the router will send all traffic toward a single BGP prefix over one of the links (fast switching performs per-destination-prefix load sharing). With CEF, the load is distributed based on the source-destination IP address pair combinations. Even if multiple clients send the traffic toward the same server, the load is spread across available links.
Load balancing quirks

This article is part of You've asked for it series.