Category: data center
HP Virtual Connect: every vendor has its own dinosaurs
I was listening to the HP Virtual Connect (VC) PPP podcast recently and got the impression that HP VC is a weirdly convoluted product. I started wondering what exactly they were thinking when they were designing it ... and had the epiphany when Ken Henault took a step back and explained the history leading to the current complexity (listen to the Packet Pushers podcast to get the whole story)
Multi-Chassis Link Aggregation (MLAG) and Hot Potato Switching
There are two reasons one would bundle parallel Ethernet links into a port channel (official term is Link Aggregation Group):
- Transforming parallel links into a single logical link bypasses Spanning Tree Protocol loop avoidance logic; all links belonging to the port channel can be active at the same time (see also: Multi-Chassis Link Aggregation basics).
- Load sharing across parallel links in a port channel increases the total bandwidth available between adjacent L2 switches or between routers/hosts and switches.
Ethan Banks wrote an excellent explanation of traditional port channel caveats (proving that 1+1 sometimes does not equal 2); things get way worse when you start using Multi-Chassis Link Aggregation due to hot potato switching (the switch tries to forward packets toward destination MAC address as soon as possible) used by all MLAG implementations I’m familiar with.
FCoE between data centers? Forget it!
Was anyone trying to sell you the “wonderful” idea of running FCoE between Data Centers instead of FC-over-DWDM or FCIP? Sounds great ... until you figure out it won’t work. Ever ... or at least until switch vendors drastically increase interface buffers on the 10GE ports.
FCoE requires lossless Ethernet between its “routers” (Fiber Channel Forwarders – see Multihop FCoE 101 for more details), which can only be provided with Data Center Bridging (DCB) standards, specifically Priority Flow Control (PFC). However, if you want to have lossless Ethernet between two points, every layer-2 (or higher) device in the path has to support DCB, which probably rules out any existing layer-2+ solution (including Carrier Ethernet, pseudowires, VPLS or OTV). The only option is thus bridging over dark fiber or a DWDM wavelength.
VMware Virtual Switch: no need for STP
During the Data Center 3.0 webinar I always mention that you can connect a VMware ESX server (with embedded virtual switch) to the network through multiple active uplinks without link aggregation. The response is very predictable: I get a few “how does that work” questions in the next seconds.
VMware did a great job with the virtual switch embedded in the VMware hypervisor (vNetwork Standard Switch – vSS – or vNetwork Distributed Switch – vDS): it uses special forwarding rules (I call them split horizon switching, Cisco UCS documentation uses the term End Host Mode) that prevent forwarding loops without resorting to STP or port blocking.
IPv6 in Data Center: after a year, Cisco is still not ready
Today I’m delivering another IPv6 presentation, this time at the 4th Slovenian IPv6 Summit organized by tireless Jan Žorž from the go6 Slovenian IPv6 initiative. It’s thus just the right time to review the post I wrote a bit more than a year ago about lack of IPv6 readiness in Cisco’s Data Center products. Let’s see what has changed in a year:
FCoE, QCN and Frame Relay analogies
Just when I hoped we were finally getting somewhere with the FCoE/QCN discussion, Brocade managed to muddy the waters with its we-still-don’t-know-what-it-is announcement. Not surprisingly, networking consultants like my friend Greg Ferro of the Etherealmind fame responded to the shenanigan with statements like “FCoE ... is a technology so mindboggingly complicated that marketing people can argue over competing claims and all be correct.” Not true, the whole thing is exceedingly simple once you understand the architecture (and the marketing people always had competing claims).
Pretend for a minute that FC ≈ IP and LAN bridging ≈ Frame Relay, teleport into this parallel universe and allow me to tell you the whole story once again in more familiar terms.
Nexus 1000V: another IPv6 #FAIL
Just stumbled across this unbelievable fact in the Nexus 1000V release notes:
IPV6 ACL rules are not supported.
My first reaction: “You must be kidding, right? Are we still in 20th century?” ... and then it dawned on me: Nexus 1000V is using the NX-OS control plane and it’s still stuck in 4.0 release which did not support IPv6 ACLs (IPv6 support was added to NX-OS in release 4.1(2)).
Does FCoE need QCN (802.1Qau)?
One of the recurring religious FCoE-related debates of the last months is undoubtedly “do you need QCN to run FCoE” with Cisco adamantly claiming you don’t (hint: Nexus doesn’t support it) and HP claiming you do (hint: their switch software lacks FC stack) ... and then there’s this recent announcement from Brocade (more about it in a future post). As is usually the case, Cisco and HP are both right ... depending on how you design your multi-hop FCoE network.
Data Center Bridging (DCB) Congestion Notification (802.1Qau)
The last (and the least popular) Data Center Bridging (DCB) standard tries to solve the problem of congestion in large bridged domains (PFC enables lossless transport and ETS standardizes DWRR queuing). To illustrate the need for congestion control, consider a simple example shown in the following diagram:
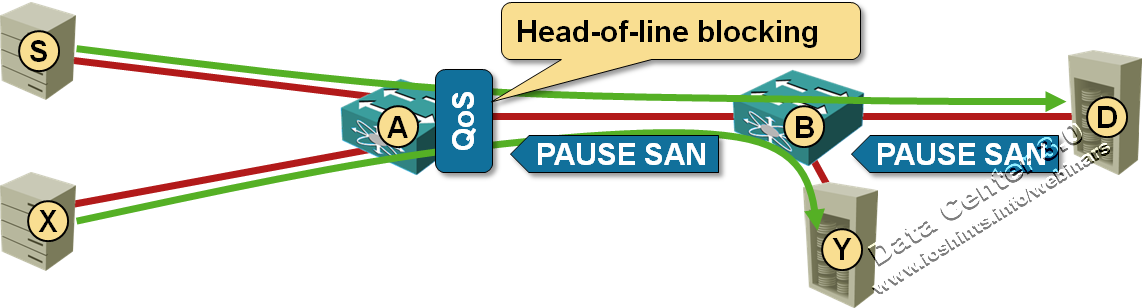
It came to my attention that a vendor might be using this blog post to justify the need for QCN in FCoE environments. Should that be the case, please make sure you also read about the difference between dense and sparse FCoE, the (lack of) need for QCN in FCoE and whether it makes sense to run FCoE over TRILL. Finally, consider how you’ll troubleshoot FCoE environments.
… updated on Sunday, December 27, 2020 17:54 UTC
vCloud Disruptiveness: Nothing New
The vCloud Director: hand the network over to server admins post received several fantastic well-reasoned comments that you should read in their entirety. Jónatan Natti correctly pointed out (among other things) that we’ve often heard “And now a networking vendor is trying to persuade people with limited exposure to […] issues to rebuild […]" where […] could stand for Voice/PBX, SNA or storage.
Update 2020-12-27: The original blog post was written in 2010 when vCloud Director and the weird MAC-in-MAC encapsulation it used was all the craze in some circles (and in particular in vendor slide decks).
The hype I was making fun of didn’t last long. The encapsulation quickly got replaced by VXLAN, the whole product died a few years later, and now VMware NSX-T and VMware on AWS are the new miracle technologies.
vCloud Director: hand the network over to server admins
A few months ago VMware decided to kick away one of the more stubborn obstacles in their way to Data Center domination: the networking team. Their vCloud architecture implements VLANs, NAT, firewalls and a bit of IP routing within the VMware hypervisor and add-on modules ... and just to make sure the networking team has no chance of interfering, they implemented MAC-in-MAC encapsulation, making their cloudy dreamworld totally invisible to the lowly net admins.
VPLS is a technology, not just a service provider offering
The Internet Exchange and Peering Points Packet Pushers Podcast is as good as the rest of them (listen to it first and then continue reading), but also strangely relevant to the data center engineers. When you look beyond the peering policies, route servers and BGP tidbits, an internet exchange is a high-performance large-scale layer-2 network that some data center switching vendors are dreaming about ... the only difference being that the internet exchanges have to perform extremely well using existing products and technologies, not the shortest-path-bridging futures promised by the vendors.
External Brains Driving an MLAG Cluster
Juniper has introduced an interesting twist to the Stacking on Steroids architecture: the brains of the box (control plane) are outsourced. When you want to build a virtual chassis (Juniper’s marketing term for stack of core switches) out of EX8200 switches, you offload all the control-plane functionality (Spanning Tree Protocol, Link Aggregation Control Protocol, first-hop redundancy protocol, routing protocols) to an external box (XRE200).
Coping with long-distance vMotion requests
During the last Data Center webinar I got an interesting question when describing the inherent problems of long-distance vMotion: “OK, I understand all the implications, but how do I persuade my server admins?”
The best answer I’ve heard so far came from an old battle-hardened networking guru: “Well, let them try”.
Data Center Interconnect (DCI) encryption
Brad sent me an interesting DCI encryption question a while ago. Our discussion started with:
We have a pair of 10GbE links between our data centers. We talked to a hardware encryption vendor who told us our L3 EIGRP DCI could not be used and we would have to convert it to a pure Layer 2 link. This doesn't make sense to me as our hand-off into the carrier network is 10GbE; couldn't we just insert the Ethernet encryptor as a "transparent" device connected to our routed port ?
The whole thing obviously started as a layering confusion. Brad is routing traffic between his data centers (the long-distance vMotion demon hasn’t visited his server admins yet), so he’s talking about L3 DCI.
The encryptor vendor has a different perspective and sent him the following requirements: