Category: BGP
Use BGP Outbound Route Filters (ORF) for IP Prefixes
When a BGP router cannot fit the whole BGP table into its forwarding table (FIB), we often use inbound filters to limit the amount of information the device keeps in its BGP table. That’s usually a waste of resources:
- The BGP neighbor has to send information about all prefixes in its BGP table
- The device with an inbound filter wastes additional CPU cycles to drop many incoming updates.
Wouldn’t it be better for the device with an inbound filter to push that filter to its BGP neighbors?
IBGP Is the Better EBGP
Whenever I was explaining how one could build EBGP-only data center fabrics, someone would inevitably ask, “But could you do that with IBGP?”
TL&DR: Of course, but that does not mean you should.
Anyway, leaving behind the land of sane designs, let’s trot down the rabbit trail of IBGP-only networks.
Use Disaggregated BGP Prefixes to Influence Inbound Internet Traffic
As much as I love explaining how to use BGP in an optimal way, sometimes we have to do what we know is bad to get the job done. For example, if you have to deal with clueless ISPs who cannot figure out how to use BGP communities, you might be forced to use the Big Hammer of disaggregated prefixes. You can practice how that works in the next BGP lab exercise.
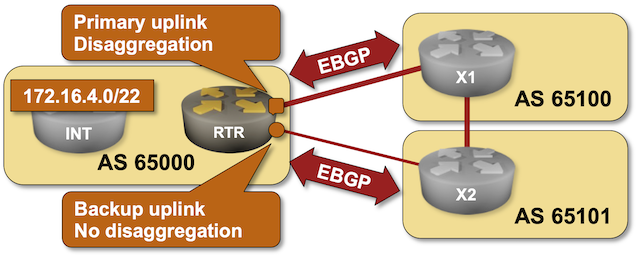
Click here to start the lab in your browser using GitHub Codespaces (or set up your own lab infrastructure). After starting the lab environment, change the directory to policy/b-disaggregate and execute netlab up.
Video: Internet Routing Security (DEEP 2023)
My Internet Routing Security talk from last year’s DEEP conference (a shorter version of the Internet Routing Security webinar) is now available on YouTube.
Hope you’ll find it useful ;)
IBGP Source Interface Selection Still Requires Configuration
A fellow networking engineer recently remarked, “FRRouting automatically selects the correct [IBGP] source interface even when not configured explicitly.”
TL&DR: No, it does not. You were just lucky.
Basics first1. BGP runs over TCP sessions. One of the first things a router does when establishing a BGP session with a configured neighbor is to open a TCP session with the configured neighbor’s IP address.
Dynamic BGP Peers
You might have an environment where a route reflector (or a route server) has dozens or hundreds of BGP peers. Configuring them by hand is a nightmare; you should either build a decent automation platform or use dynamic BGP neighbors – a feature you can practice in the next lab exercise.
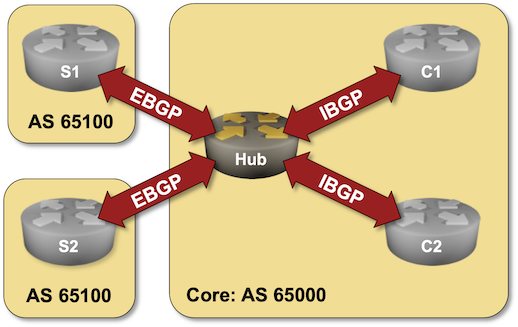
Click here to start the lab in your browser using GitHub Codespaces (or set up your own lab infrastructure). After starting the lab environment, change the directory to session/9-dynamic and execute netlab up.
Using a BGP Route Server in an Internet Exchange Point
A BGP route server is like a BGP route reflector but for EBGP sessions. In its simplest implementation, it receives BGP updates over EBGP sessions and propagates them over other EBGP sessions without inserting its own AS number in the AS path (more details).
BGP route servers are commonly used on Internet Exchange Points (IXPs), and that’s what you can practice in the BGP Route Server in an Internet Exchange Point lab exercise.
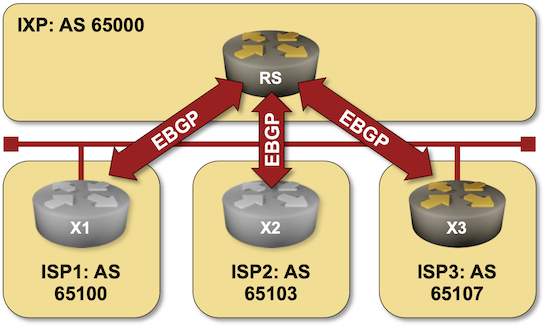
Click here to start the lab in your browser using GitHub Codespaces (or set up your own lab infrastructure). After starting the lab environment, change the directory to session/5-routeserver and execute netlab up.
Using BGP NO_EXPORT Community to Filter Transit Routes
In previous BGP policy lab exercises, we covered several mechanisms you can use to ensure your autonomous system is not leaking transit routes (because bad things happen when you do, particularly when your upstream ISP is clueless).
As you probably know by now, there’s always more than one way to get something done with BGP. Today, we’ll explore how you can use the NO_EXPORT community to filter transit routes.
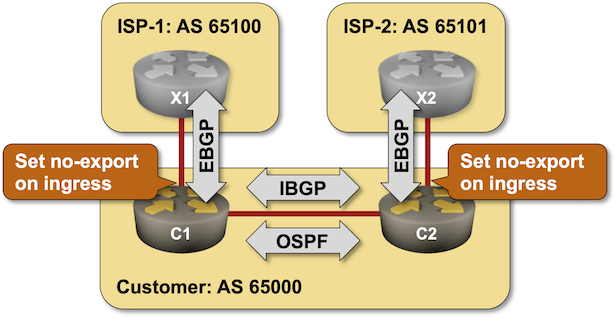
Click here to start the lab in your browser using GitHub Codespaces (or set up your own lab infrastructure). After starting the lab environment, change the directory to policy/d-no-export and execute netlab up.
BGP Labs: Improvements (September 2024)
I spent a few days in a beautiful place with suboptimal Internet connectivity. The only thing I could do whenever I got bored (without waiting for the Internet gnomes to hand-carry the packets across the mountain passes) was to fix the BGP labs on a Ubuntu VM running on my MacBook Air (hint: it all works).
Big things first. I added validation to these labs:
IBGP Load Balancing with BGP Link Bandwidth
In the previous BGP load balancing lab exercise, I described the BGP Link Bandwidth attribute and how you can use it on EBGP sessions. This lab moves the unequal-cost load balancing into your network; we’ll use the BGP Link Bandwidth attribute on IBGP sessions.
Routing Table and BGP RIB on SR Linux
Ages ago, I described how “traditional” network operating systems used the BGP Routing Information Base (BGP RIB), the system routing table (RIB), and the forwarding table (FIB). Here’s the TL&DR:
- Routes received from BGP neighbors are stored in BGP RIB.
- Routes redistributed into BGP from other protocols are (re)created in the BGP RIB.
- BGP selects the best routes in BGP RIB using its convoluted set of rules.
- Best routes from the BGP RIB are advertised to BGP neighbors
- Best routes from the BGP RIB compete (based on their administrative distance) against routes from other routing protocols to enter the IP routing table (system RIB)
- Routes from the system RIB are copied into FIB after their next hops are fully evaluated (a process that might involve multiple recursive lookups).
Using No-Export Community to Filter Transit Routes
The very first BGP Communities RFC included an interesting idea: let’s tag paths we don’t want to propagate to other autonomous systems. For example, the prefixes received from one upstream ISP should not be propagated to another upstream ISP (sadly, things don’t work that way in reality).
Want to try out that concept? Start the Using No-Export Community to Filter Transit Routes lab in GitHub Codespaces.
Testing bgpipe with netlab
Ever since Pawel Foremski talked about BGP Pipe @ RIPE88 meeting, I wanted to kick its tires in netlab. BGP Pipe is a Go executable that runs under Linux (but also FreeBSD or MacOS), so I could add a Linux VM (or container) to a netlab topology and install the software after the lab has been started. However, I wanted to have the BGP neighbor configured on the other side of the link (on the device talking with the BGP Pipe daemon).
I could solve the problem in a few ways:
BGP Session and Address Family Parameters
As I was doing the final integration tests for netlab release 1.9.0, I stumbled upon a fascinating BGP configuration quirk: where do you configure the allowas-in parameter and why?
A Bit of Theory
BGP runs over TCP, and all parameters related to the TCP session are configured for a BGP neighbor (IPv4 or IPv6 address). That includes the source interface, local AS number (it’s advertised in the per-session OPEN message that negotiates the address families), MD5 password (it uses MD5 checksum of TCP packets), GTSM (it uses the IP TTL field), or EBGP multihop (it increases the IP TTL field).
BGP, EVPN, VXLAN, or SRv6?
Daniel Dib asked an interesting question on LinkedIn when considering an RT5-only EVPN design:
I’m curious what EVPN provides if all you need is L3. For example, you could run pure L3 BGP fabric if you don’t need VRFs or a limited amount of them. If many VRFs are needed, there is MPLS/VPN, SR-MPLS, and SRv6.
I received a similar question numerous times in my previous life as a consultant. It’s usually caused by vendor marketing polluting PowerPoint slide decks with acronyms without explaining the fundamentals1. Let’s fix that.