Category: BGP
BGP Labeled Unicast on Arista EOS
A week ago I described how Cisco IOS implemented BGP Labeled Unicast. In this blog post we’ll focus on Arista EOS using the same lab as before:
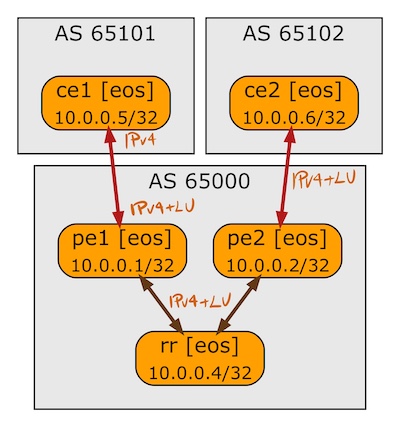
BGP sessions in the BGP-LU lab
BGP Labeled Unicast on Cisco IOS
While researching the BGP RFCs for the Three Dimensions of BGP Address Family Nerd Knobs, I figured out that the BGP Labeled Unicast (BGP-LU, advertising MPLS labels together with BGP prefixes) uses a different address family. So far so good.
Now for the intricate bit: a BGP router might negotiate IPv4 and IPv4-LU address families with a neighbor. Does that mean that it’s advertising every IPv4 prefix twice, once without a label, and once with a label? Should that be the case, how are those prefixes originated and how are they stored in the BGP table?
As always, the correct answer is “it depends”, this time on the network operating system implementation. This blog post describes Cisco IOS behavior, a follow-up one will focus on Arista EOS.
Should We Use LISP?
LISP started as yet-another ocean-boiling project focused initially on solving the “we use locators as identifiers” mess (not quite), and providing scalable IPv6 connectivity over IPv4-only transport networks by adding another layer of indirection and thus yet again proving RFC 1925 rule 6a. At least those are the diagrams I remember from the early “look at this wonderful tool” presentations explaining for example how Facebook is using LISP to deploy IPv6 (more details in this presentation).
Somehow that use case failed to gain traction and so the pivots1 started explaining how one can use LISP to solve IP mobility or IP multihoming or live VM migration, or to implement IP version of conversational learning in Cisco SD-Access. After a few years of those pivots, I started dismissing LISP with a short “cache-based forwarding never worked well” counterargument.
Worth Reading: Performance Testing of Commercial BGP Stacks
For whatever reason, most IT vendors attach “you cannot use this for performance testing and/or publish any results” caveat to their licensing agreements, so it’s really hard to get any independent test results that are not vendor-sponsored and thus suitably biased.
Justin Pietsch managed to get a permission to publish test results of Junos container implementation (cRPD) – no surprise there, Junos outperformed all open-source implementations Justin tested in the past.
Running BGP between Virtual Machines and Data Center Fabric
Got this question from one of my readers:
When adopting the BGP on the VM model (say, a Kubernetes worker node on top of vSphere or KVM or Openstack), how do you deal with VM migration to another host (same data center, of course) for maintenance purposes? Do you keep peering with the old ToR even after the migration, or do you use some BGP trickery to allow the VM to peer with whatever ToR it’s closest to?
Short answer: you don’t.
Kubernetes was designed in a way that made worker nodes expendable. The Kubernetes cluster (and all properly designed applications) should recover automatically after a worker node restart. From the purely academic perspective, there’s no reason to migrate VMs running Kubernetes.
Mixed Feelings about BGP Route Reflector Cluster ID
Here’s another BGP Route Reflector myth:
In a redundant design, you should use Route Reflector Cluster ID to avoid loops.
TL&DR: No.
While BGP route reflectors can cause permanent forwarding loops in sufficiently broken topologies, the Cluster ID was never needed to stop a routing update propagation loop:
BGP Route Reflector Myths
New networking myths are continuously popping up. Here’s a BGP one I encountered a few days ago:
You don’t need IBGP sessions between BGP route reflectors
In general, that’s clearly wrong, as illustrated by this setup:
Three Dimensions of BGP Address Family Nerd Knobs
Got into an interesting BGP discussion a few days ago, resulting in a wild chase through recent SRv6 and BGP drafts and RFCs. You might find the results mildly interesting ;)
BGP has three dimensions of address family configurability:
- Transport sessions. Most vendors implement BGP over TCP over IPv4 and IPv6. I’m sure there’s someone out there running BGP over CLNS1, and there are already drafts proposing running BGP over QUIC2.
- Address families enabled on individual transport sessions, more precisely a combination of Address Family Identifier (AFI) and Subsequent Address Family Identifier.
- Next hops address family for enabled address families.
Feedback: Recursive BGP Next Hop Resolution
The Recursive BGP Next Hops: an RFC 4271 Quirk blog post generated tons of feedback (thanks a million to everyone writing a comment on my blog or LinkedIn).
Starting with Robert Razsuk who managed to track down the original email that triggered the (maybe dubious) text in RFC 4271:
The text in section 5.1.3 was not really targeting to prohibit load balancing. Keep in mind that it is FIB layer which constructs actual forwarding paths.
The text has been suggested by Tom Petch in discussion about BGP advertising valid paths or even paths it actually installs in the RIB/FIB. The entire section 5.1.3 is about rules when advertising paths by BGP.
Recursive BGP Next Hops: an RFC 4271 Quirk
All BGP implementations I’ve seen so far use recursive next hop lookup:
- The next hop in the IP routing table is the BGP next hop advertised in the incoming update
- That next hop is resolved into the actual next hop using one or more recursive lookups into the IP routing table.
Furthermore, all BGP implementations I’ve seen used multiple recursive next hops (if available) to implement load balancing toward the BGP next hop – that’s how we made EBGP load balancing work in Stone Age of networking.