More IPv6 FUD being thrown @ CFOs
The CFO magazine has recently published a FUDful article “Trouble Looms for Company Websites” (read it to see what CFOs have to deal with). Obviously, some people think it’s a good idea to throw FUD at CFOs to get the budget to implement IPv6. Long term, it’s a losing strategy; your CFO will become immune to anything coming from the IT department and ignore the real warnings.
Yes, it's time to make your content reachable over IPv4 and IPv6, more so if you’re in the eyeballs business. Google knows that. So does Facebook. Twitter doesn’t seem to care. Maybe because they’re not selling ads?
I Don’t Need no Stinking Firewall ... or Do I?
Brian Johnson started a lively “I don’t need no stinking firewall” discussion on NANOG mailing list in January 2010. I wanted to write about the topic then, but somehow the post slipped through the cracks… and I’m glad it did, as I’ve learned a few things in the meantime, including the (now obvious) fact that no two data centers are equal (the original debate had to do with protecting servers in large-scale data center).
First let’s rephrase the provocative headline from the discussion. The real question is: do I need a stateful firewall or is a stateless one enough?
Port or Fabric Extenders?
Among other topics discussed during the Big Hot and Heavy Switches (Part 1) podcast (if you haven’t listened to it yet, it’s high time you do), we’ve mentioned port extenders. As our virtual whiteboard is not always clearly visible during the podcast (although we scribble heavily on it), here’s the big-picture architecture:
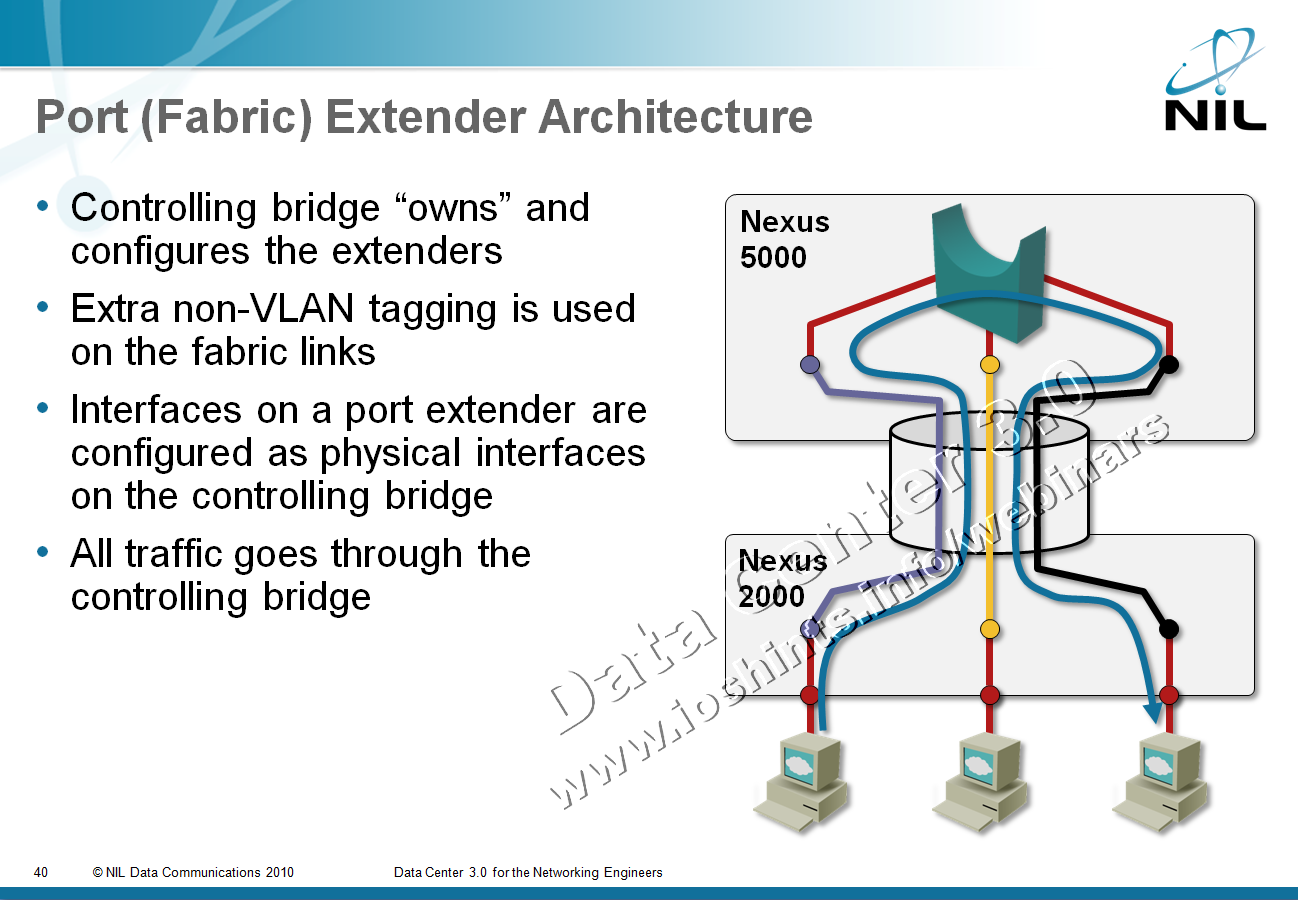
After the podcast I wanted to dig into a few minor technical details and stumbled into a veritable confusopoly.
Packet Filters on a Nexus 7000
We’re always quick to criticize ... and usually quiet when we should praise. I’d like to fix one of my omissions: a few days ago I was trying to figure out whether Nexus 7000 supports IPv6 access lists (one of the presentations I was looking at while researching the details for my upcoming Data Center webinar implied there might be a problem) and was pleasantly surprised by the breadth of packet filters offered on this platform. Let’s start with a diagram.
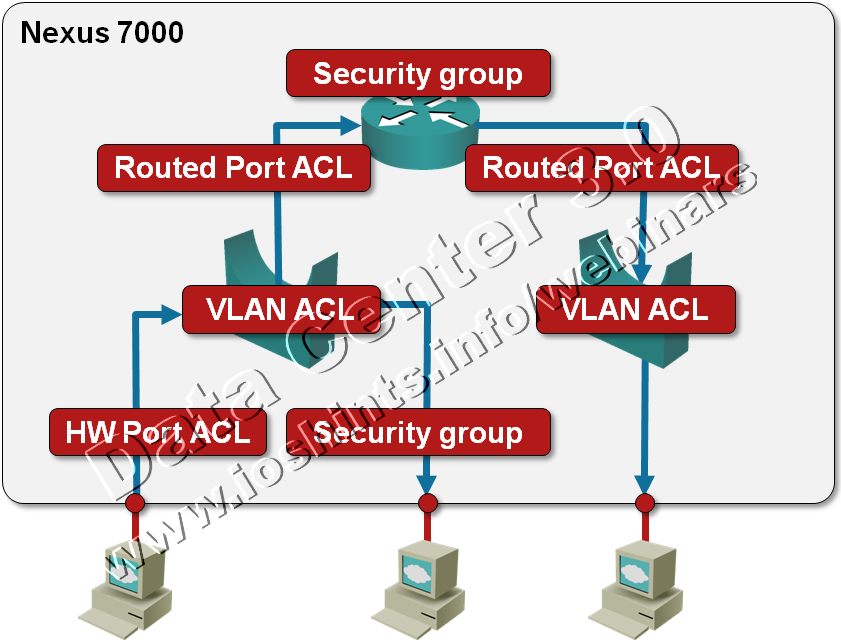
WAF musings ... not again?
Following my obituary for Cisco’s WAF, Packet Pushers did a really great WAF-focused podcast with Raven Alder, appropriately named Saving the Web with Dinky Putt Putt Firewalls. If you have more than a fleeting interest in protecting business web applications, you should definitely listen to it. Just as an aside: when they were recording the podcast, I was writing my To WAF or not to WAF post ... and it’s nice to see we’re closely aligned on most points.
There’s just a bit I’d like to add to their ponderings. What Raven describes is the “proper” (arduous, time-consuming and labor-intensive) use of WAF that we’re used to from the layer-3/4 firewalls: learning what your web application does (learning because the design specs were never updated to reflect reality) and then applying the knowledge to filter everything else (what I sometimes call the fascist mode – whatever is not explicitly permitted is dropped).
Interesting links (2010-08-14)
A few days ago I wrote that you should always strive to understand the technologies beyond the reach of your current job. Stephen Foskett is an amazing example to follow: although he’s a storage guru, he knows way more about HTTP than most web developers and details of the web server architecture that most server administrators are not aware of. Read his High-Performance, Low-Memory Apache/PHP Virtual Private Server; you’ll definitely enjoy the details.
Deploying IPv6 article @ SearchTelecom
Following my “Transition to IPv6” articles, Jessica Scarpati from SearchTelecom.com wrote a series of articles covering the telecom transition plans and the problems they’re experiencing with the vendors and content providers.
In the second article of the series, “Deploying IPv6? Demand responsiveness from vendors, content providers”, she’s quoting John Jason Brzozowski from Comcast, John Curran from ARIN, Matt Sewell from Global Crossing and myself. My key message: vote with your money and take your business elsewhere if the vendors don’t get their act together.
Vendor performance tests

Any comment would be superfluous.
To WAF or not to WAF?
Extremely valid comment made by Pavel Skovajsa in response to my “Rest in peace, my WAF friend” post beautifully illustrates the compartmentalized state some IT organizations face; before going there, let’s start with the basic questions.
Do we need WAF ... as a function, not as a box or a specific product? It’s the same question as “do we need virus scanners” or “do we need firewalls” in a different disguise. In an ideal world where all the developers would be security-conscious and there would be no bugs, the answer is “NO”. As we all know, we’re in a different dimension and getting further away from the heavens every time someone utters “just good enough” phrase or any other such bingo-winning slogan.
It’s popular to bash IT vendors’ lack of security awareness (Microsoft comes to mind immediately), but they’re still far ahead of a typical web application developer. At least they get huge exposure, which forces them to implement security frameworks.
Interesting links (2010-08-08)
Several interesting blog posts I’ve stumbled upon in the last few days:
Should developers have access to production? A really good analysis of pros and cons (including a pinch of “this is how it’s always been done”).
Migrating from Catalyst to Nexus. As usual, there are hidden gotchas and varying default settings that make the migration more interesting than expected.
Justifying VDI. VMware has decided to deploy virtual desktops; they describe what they’ve learnt and how you should approach VDI projects.