The Linux Bridge MTU Hell
It all started with an innocuous article describing the MTU basics. As the real purpose of the MTU is to prevent packet drops due to fixed-size receiver buffers, and I waste spend most of my time in virtual labs, I wanted to check how various virtual network devices react to incoming oversized packets.
As the first step, I created a simple netlab topology in which a single link had a slightly larger than usual MTU… and then all hell broke loose.
provider: libvirt
nodes:
r:
device: eos
h:
device: linux
links:
- r:
h:
mtu: 1600
After starting the lab, both devices could ping each other.
r#ping h
PING h (172.16.0.2) 72(100) bytes of data.
80 bytes from h (172.16.0.2): icmp_seq=1 ttl=64 time=4.51 ms
80 bytes from h (172.16.0.2): icmp_seq=2 ttl=64 time=0.548 ms
80 bytes from h (172.16.0.2): icmp_seq=3 ttl=64 time=0.506 ms
80 bytes from h (172.16.0.2): icmp_seq=4 ttl=64 time=0.650 ms
vagrant@h:~$ ping Ethernet1.r -c 3
PING Ethernet1.r (172.16.0.1) 56(84) bytes of data.
64 bytes from Ethernet1.r (172.16.0.1): icmp_seq=1 ttl=64 time=1.30 ms
64 bytes from Ethernet1.r (172.16.0.1): icmp_seq=2 ttl=64 time=1.16 ms
64 bytes from Ethernet1.r (172.16.0.1): icmp_seq=3 ttl=64 time=1.23 ms
However, when I tried to use packet sizes above 1500 bytes, I could ping the Linux VM from the Arista VM but failed in the other direction.
r#ping h size 1600
PING h (172.16.0.2) 1572(1600) bytes of data.
1580 bytes from h (172.16.0.2): icmp_seq=1 ttl=64 time=1.20 ms
1580 bytes from h (172.16.0.2): icmp_seq=2 ttl=64 time=0.922 ms
1580 bytes from h (172.16.0.2): icmp_seq=3 ttl=64 time=0.594 ms
vagrant@h:~$ ping Ethernet1.r -s 1500
PING Ethernet1.r (172.16.0.1) 1550(1578) bytes of data.
^C
--- Ethernet1.r ping statistics ---
3 packets transmitted, 0 received, 100% packet loss, time 2045ms
When faced with a bizarre behavior like this, my brain should have been screaming MTU1, but I must have been sluggish. It took quite a bit of packet capture to figure things out.
Behind the Scenes
I was using libvirt/KVM/QEMU to start two VMs connected with a Linux bridge; my connectivity looked almost exactly like the following diagram from the Capturing Traffic in Virtual Networking Labs blog post (more connectivity details in Links in Virtual Labs)
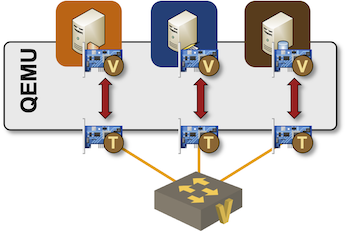
After starting the lab, I could quickly identify the Linux bridge and the two interfaces connected to it:
$ virsh net-list
Name State Autostart Persistent
----------------------------------------------------
default active yes yes
vagrant-libvirt active no yes
X_1 active yes yes
$ virsh net-info X_1
Name: X_1
UUID: e499a610-2716-4f88-87b6-2ef6a37fed58
Active: yes
Persistent: yes
Autostart: yes
Bridge: virbr1
$ brctl show virbr1
bridge name bridge id STP enabled interfaces
virbr1 8000.52540011f3fe yes vgif_h_1
vgif_r_1
Armed with that information, I started packet capture on the egress interface (vgif_h_1), the bridge (virbr1), and the ingress interface (vgif_r_1). I could see the traffic sent by the Linux host, and I could see it on the Linux bridge, but it never got to the outgoing tap interface:
$ sudo tcpdump -v -i vgif_h_1 ip
tcpdump: listening on vgif_h_1, link-type EN10MB (Ethernet), snapshot length 262144 bytes
09:04:12.430482 IP (tos 0x0, ttl 64, id 44539, offset 0, flags [DF], proto ICMP (1), length 1528)
172.16.0.2 > 172.16.0.1: ICMP echo request, id 1618, seq 45, length 1508
09:04:13.454456 IP (tos 0x0, ttl 64, id 45358, offset 0, flags [DF], proto ICMP (1), length 1528)
172.16.0.2 > 172.16.0.1: ICMP echo request, id 1618, seq 46, length 1508
^C
2 packets captured
2 packets received by filter
0 packets dropped by kernel
pipi@brick2:~$ sudo tcpdump -v -i virbr1 ip
tcpdump: listening on virbr1, link-type EN10MB (Ethernet), snapshot length 262144 bytes
09:04:20.622563 IP (tos 0x0, ttl 64, id 48558, offset 0, flags [DF], proto ICMP (1), length 1528)
172.16.0.2 > 172.16.0.1: ICMP echo request, id 1618, seq 53, length 1508
09:04:21.646501 IP (tos 0x0, ttl 64, id 49287, offset 0, flags [DF], proto ICMP (1), length 1528)
172.16.0.2 > 172.16.0.1: ICMP echo request, id 1618, seq 54, length 1508
^C
2 packets captured
2 packets received by filter
0 packets dropped by kernel
pipi@brick2:~$ sudo tcpdump -v -i vgif_r_1 ip
tcpdump: listening on vgif_r_1, link-type EN10MB (Ethernet), snapshot length 262144 bytes
^C
0 packets captured
0 packets received by filter
0 packets dropped by kernel
Finally, my subconscious kicked in and screamed MTU. Even though both VMs increased the MTU on the virtual NICs, the MTU of all three Linux devices was set to 1500 :(
$ ip link
25893: virbr1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 52:54:00:11:f3:fe brd ff:ff:ff:ff:ff:ff
25895: vgif_r_1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master virbr1 state UNKNOWN mode DEFAULT group default qlen 1000
link/ether fe:54:00:fc:db:54 brd ff:ff:ff:ff:ff:ff
25897: vgif_h_1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master virbr1 state UNKNOWN mode DEFAULT group default qlen 1000
link/ether fe:54:00:82:79:b2 brd ff:ff:ff:ff:ff:ff
Root cause: QEMU does not adjust the MTU of the Linux TAP interface when the VM changes the NIC MTU.
The unabridged reality is even worse than that:
- If the MTU is specified for the QEMU TAP interface (using the
:libvirt__mtuVagrant parameter), QEMU passes that value as the maximum possible MTU to the VM NIC (assuming it can; I tested this for the virtio NICs but not for E1000). A well-behaved VM operating system can never exceed the MTU of the infrastructure interface. - When no MTU is specified for the QEMU TAP interface, it’s set to 1500 for the TAP interface, but there’s no limit on the VM side (the maximum MTU for the VM NIC is 65535).
A bit of consistency would go a long way toward preventing unnecessary headaches.
However, one thing still bothered me: why did the ping from the Arista switch to the Linux host work? Time for another packet capture:
$ sudo tcpdump -v -i vgif_r_1 ip
tcpdump: listening on vgif_r_1, link-type EN10MB (Ethernet), snapshot length 262144 bytes
09:10:52.205892 IP (tos 0x0, ttl 64, id 25829, offset 0, flags [none], proto ICMP (1), length 1600)
172.16.0.1 > 172.16.0.2: ICMP echo request, id 4, seq 1, length 1580
09:10:52.206141 IP (tos 0x0, ttl 64, id 38156, offset 0, flags [+], proto ICMP (1), length 1500)
172.16.0.2 > 172.16.0.1: ICMP echo reply, id 4, seq 1, length 1480
09:10:52.206147 IP (tos 0x0, ttl 64, id 38156, offset 1480, flags [none], proto ICMP (1), length 120)
172.16.0.2 > 172.16.0.1: icmp
^C
3 packets captured
3 packets received by filter
0 packets dropped by kernel
$ sudo tcpdump -v -i vgif_h_1 ip
tcpdump: listening on vgif_h_1, link-type EN10MB (Ethernet), snapshot length 262144 bytes
09:11:11.802368 IP (tos 0x0, ttl 64, id 30203, offset 0, flags [+], proto ICMP (1), length 1500)
172.16.0.1 > 172.16.0.2: ICMP echo request, id 5, seq 1, length 1480
09:11:11.802375 IP (tos 0x0, ttl 64, id 30203, offset 1480, flags [none], proto ICMP (1), length 120)
172.16.0.1 > 172.16.0.2: icmp
09:11:11.802526 IP (tos 0x0, ttl 64, id 38875, offset 0, flags [none], proto ICMP (1), length 1600)
172.16.0.2 > 172.16.0.1: ICMP echo reply, id 5, seq 1, length 1580
^C
3 packets captured
3 packets received by filter
0 packets dropped by kernel
Something weird was going on: I could see a single packet leaving each VM but two packets leaving the Linux bridge. I quickly realized the second packet leaving the Linux bridge was a fragment (contrary to the Linux host, the Arista switch does not set the DF bit by default), but who was doing the fragmentation?
It turns out the answer is the Linux bridge. When someone decided it made sense to firewall traffic that was bridged (not routed) by the Linux bridge, they had to implement IPv4 defragmentation of ingress traffic to inspect it. Those packets must be fragmented on egress interfaces, causing IP fragmentation of bridged traffic even when the module that implements filtering of bridged traffic is not loaded.
As the Linux bridge (in my setup) does not have an IP address, it cannot generate the ICMP unreachable reports, resulting in a lovely local PMTUD black hole. Great job, everyone!
Workarounds:
- Increase the MTU on the QEMU tap interfaces
- Use something that behaves more like a patch panel, not a Swiss Army Knife of unwanted behavior. Maybe it’s time to test how Open vSwitch works in these scenarios.
Let’s wrap up with some good news: this behavior does not impact the QEMU UDP tunnels or the containerlab labs. Containerlab sets MTU on vEth interfaces to 9500, and the TAP interfaces used by vrnetlab QEMU-VMs-in-containers have huge MTU.
-
It couldn’t have been DNS or BGP, they were both AWOL. ↩︎
great bit! I just had great fun discovering that MTU is apparently only applied on egress?! Which also means that, contrary to my previous belief, a packet bigger than the MTU on an ingress port will not cause a packet too big message to be sent back. Which means trouble when the egress interface can not reach the sender of the packet. But that's only a theoretical scenario, right? Right...
Technically, a packet too big on ingress should be dropped (as it could not fit into the input buffer), but of course, that's not how Linux bridges work; they are just shuffling pointers to packet buffers.
Anyway, the bridge SHOULD NOT send the PTB message anyway (or mess with the packets), and in my case, it COULD NOT because it had no IP address.
Finally, there's nothing the egress interface could do -- it never saw the packet anyway.
My favourite "perk" of linux bridging is when it drops MTU to the lowest MTU of its members. It can bite hard on Cumulus with one mistake.