IRB Models: Edge Routing
The simplest way to implement layer-3 forwarding in a network fabric is to offload it to an external device1, be it a WAN edge router, a firewall, a load balancer, or any other network appliance.
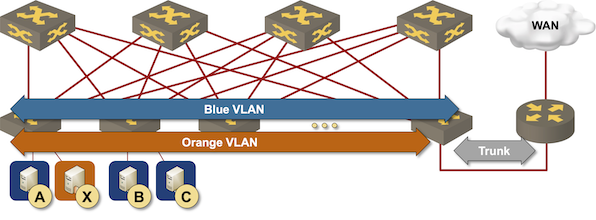
Routing at the (outer) edge of the fabric
While the hipsters sipping EVPN Kool-Aid might consider that approach a design from the 1990s, it’s used more often than you might expect, for example:
- When the majority of the traffic goes through a WAN edge router toward external destinations;
- When all the traffic between a subnet and external destinations has to be inspected by a security appliance;
- When you’re using virtual network appliances in combination with layer-2-only overlay virtual networks2;
- When the amount of routed traffic is small, and the vendor overcharges for layer-3 forwarding capabilities in the fabric switches3;
- In aggregation networks, when switch ports are way cheaper than router ports, it makes sense to aggregate the traffic in a layer-2 switch and forward it through a single faster port to a router4.
This design seems like the simplest possible thing you might be asked to implement until someone says, “but we need two edge devices for redundancy.” Welcome to the first-hop redundancy hell.
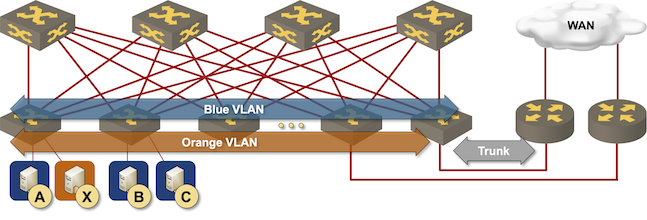
Redundant routing at the (outer) edge of the fabric
In a perfect world, everyone would be using IPv6, the IPv6 hosts would happily load-balance traffic between multiple adjacent routers, and we could fine-tune the router advertisement (RA) messages to allow a sub-second failover on a router failure.
Meanwhile, on Planet Earth:
- Way too many environments still use IPv4.
- Most IP hosts use a single default route toward a single default gateway, and that default gateway can have a single MAC address.
- RA-based redundancy is often considered too slow (see IPv6 High Availability Strategies webinar for more details), so we have to use first-hop redundancy protocols even in IPv6 deployments.
Even worse, we can’t use active-active FHRP implementations or anycast gateways in this design because we cannot have the same MAC address (the MAC address of the first-hop router) present on two fabric ports.
There are no good solutions to this problem; the only thing you can do is to choose one that sucks the least:5
- Use each device as the first-hop gateway for half of the subnets and hope that you got it right and that a sudden increase in traffic won’t bring down one of the devices6.
- Use active/active FHRP implementation or an anycast gateway with a link aggregation group (LAG) between the fabric and the redundant devices. The LAG makes redundant devices appear as a single node in the network fabric so that they can use the same MAC address. Have fun dealing with MLAG implementations on both ends of those links.
- Use a proprietary implementation like GLBP that uses different MAC addresses in ARP replies for the same IP address, effectively spreading the load across redundant devices based on the host ARP entries.
- Give up and accept that having a redundant solution that is more than 50% loaded doesn’t make sense anyway. That will make your CFO unhappy, but you might still have a running network after one of the devices fails during the peak traffic period.
You’ll find more details in the VRRP, Anycasts, Fabrics and Optimal Forwarding blog post.
What’s Next?
Subsequent blog posts will focus on the intricate details of intra-fabric routing, but it might take me a while to publish them. If you’re in a hurry, you’ll find those details in Leaf-and-Spine Fabric Architectures and EVPN Technical Deep Dive webinars.
-
Proving RFC 1925 Rule 6 ↩︎
-
Which happens to be the case in many Cisco ACI deployments due to the inherent complexity of more comprehensive designs. ↩︎
-
One would hope that’s not the case in 2023, but I stopped being surprised at vendor shenanigans a long while ago. ↩︎
-
You REALLY don’t want to have a dozen 100G ports with average utilization below 10% on a reassuringly expensive carrier-grade router. ↩︎
-
In your personal opinion ;), we’re deep in the It Depends territory. ↩︎
-
One of my customers managed to (consistently) crash a firewall from a major vendor when doing daily backups over the network. ↩︎
"While the hipsters sipping EVPN Kool-Aid" , I feel very seen right now. Haha. Great write up.