Blog Posts in March 2022
Is MPLS/VPN Too Complex?
Henk Smit made the following claim in one of his comments:
I think BGP-MPLS-VPNs are over-complicated. And you don’t get enough return for that extra complexity.
TL&DR: He’s right (and I just violated Betteridge’s law of headlines)
The history of how we got to the current morass might be interesting for engineers who want to look behind the curtain, so here we go…
Duplicate ARP Replies with Anycast Gateways
A reader sent me the following intriguing question:
I’m trying to understand the ARP behavior with SVI interface configured with anycast gateways of leaf switches, and with distributed anycast gateways configured across the leaf nodes in VXLAN scenario.
Without going into too many details, the core dilemma is: will the ARP request get flooded, and will we get multiple ARP replies. As always, the correct answer is “it depends” 🤷♂️
BGP Labeled Unicast on Arista EOS
A week ago I described how Cisco IOS implemented BGP Labeled Unicast. In this blog post we’ll focus on Arista EOS using the same lab as before:
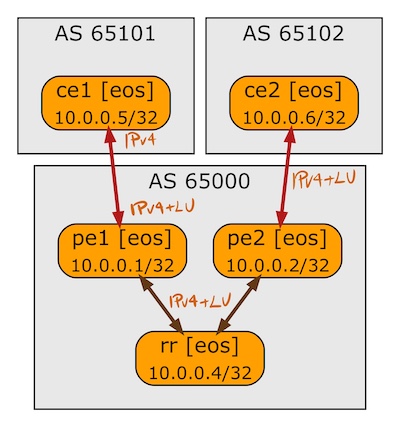
BGP sessions in the BGP-LU lab
… updated on Friday, May 31, 2024 13:51 +0200
Combining BGP and IGP in an Enterprise Network
Syed Khalid Ali left the following question on an old blog post describing the use of IBGP and EBGP in an enterprise network:
From an enterprise customer perspective, should I run iBGP, iBGP+IGP (OSPF/ISIS/EIGRP), or IGP with mutual redistribution on the edge routers? I was hoping you could share some thoughtful insight on when to select one over the other.
We covered many relevant details in the January 2022 Design Clinic; here’s the CliffNotes version. Remember that the road to hell (and broken designs) is paved with great recipes and best practices and that I’m presenting a black-and-white picture because I don’t feel like transcribing our discussion into an oversized blog post. People wrote books on this topic; search for “Russ White books” to find a few.
Finally, there’s no good substitute for understanding how things work (which brings me to another webinar ;).
Worth Reading: VMware Operations Guide
Iwan Rahabok’s open-source VMware Operations Guide is now also available in Markdown-on-GitHub format. Networking engineers support vSphere/NSX infrastructure might be particularly interested in the Network Metrics chapter.
Draw a Network Diagram from Excel Spreadsheet
Would you happen to have your network connectivity data in a tabular format (Excel or similar)? Would you like to make a graph out of that?
Look at the Excel-to-Graphviz solution created by and Salman Naqvi and Roman Urchin. It might not be exactly what you’re looking for, but you might get a few ideas and an inspiration to do something similar.
Video: Managed SD-WAN Services
Should service providers offer managed SD-WAN services? According to Betteridge’s law of headlines, the answer is NO, and that’s exactly what I explained in a short video with the same name.
Turns out there’s not much to explain; even with my usual verbosity I was done in five minutes, so you might want to watch SD-WAN Technical Challenges as well.
Beware: Ansible Reorders List Values in Loops
TL&DR: Ansible might decide to reorder list values in a loop parameter, resulting in unexpected order of execution and (in my case) totally borked device configuration.
A bit of a background first: I’m using an Ansible playbook within netlab to deploy initial device configurations. Among other things, that playbook deploys configuration snippets for numerous configuration modules, and the order of deployment is absolutely crucial. For example, you cannot activate BGP neighbors in Labeled Unicast (BGP-LU) address family (mpls module) before configuring BGP neighbors (bgp module).
BGP Labeled Unicast on Cisco IOS
While researching the BGP RFCs for the Three Dimensions of BGP Address Family Nerd Knobs, I figured out that the BGP Labeled Unicast (BGP-LU, advertising MPLS labels together with BGP prefixes) uses a different address family. So far so good.
Now for the intricate bit: a BGP router might negotiate IPv4 and IPv4-LU address families with a neighbor. Does that mean that it’s advertising every IPv4 prefix twice, once without a label, and once with a label? Should that be the case, how are those prefixes originated and how are they stored in the BGP table?
As always, the correct answer is “it depends”, this time on the network operating system implementation. This blog post describes Cisco IOS behavior, a follow-up one will focus on Arista EOS.
MPLS/LDP Creation Myths
Hannes Gredler wrote an interesting comment to my Segment Routing vs LDP in Hub-and-Spoke Networks blog post:
In 2014 when I did the first prototype implementation of MPLS-SR node labels, I was stunned that just with an incremental add of 500 lines of code to the vanilla IPv4/IPv6 IS-IS codebase I got full any-to-any connectivity, no sync issues, no targeted sessions for R-LFA …. essentially labeled transport comes for free.
Based on that, one has to wonder “why did we take the LDP detour and all the complexity it brings?”. Here’s what Hannes found out:
Automating NSX-T Deployments
Nicholas Michel open-sourced an automation solution (video) that deploys the whole NSX-T infrastructure stack including:
- NSX-T manager virtual machines
- NSX-T uplink profiles and IP pools
- Transport zones and transport nodes (NSX-T modules on ESXi hypervisors)
- Edge clusters including BGP, EVPN and BFD
Once the infrastructure is set up, his solution uses a Terraform configuration file to deploy multiple tenants: external VLANs, tier-0 gateways, BGP neighbors, tier-1 gateways, and application segments.
While the infrastructure part of his solution might be fully reusable, the tenant deployments definitely aren’t, but they provide a great starting point if you decide to build a fully automated provisioning system.
Video: Kubernetes Networking Model
After describing the Kubernetes architecture in the introductory part of the excellent Kubernetes Networking Deep Dive webinar, Stuart Charlton focused on what matters most to networking engineers: Kubernetes networking model.
So-Called Modern VPNs: Marketing and Reality
Someone left a “killer” comment1 after reading the Should We Use LISP blog post. It start with…
I must sadly say that your view on what VPN is all about is pretty rusty and archaic :( Sorry! Modern VPNs are all pub-sub based and are already turning into NaaS.
Nothing new there. I’ve been called old-school guru from an ivory tower when claiming TRILL is the wrong direction and we should use good old layer-3-based design2, but let’s unpack the “pub-sub” bit.
… updated on Friday, March 18, 2022 07:02 UTC
Hub-and-Spoke VPLS: Revenge of LDP
In the Segment Routing vs LDP in Hub-and-Spoke Networks blog post I explained why you could get into interesting scaling issues when running MPLS with LDP in a large hub-and-spoke network, and how you can use Segment Routing (MPLS edition) to simplify your design.
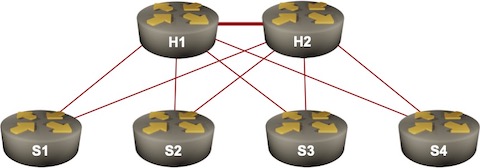
Sample hub-and-spoke network
Now imagine you’d like to offer VPLS services between hubs and spokes, and happen to be using equipment that uses targeted LDP sessions to signal pseudowires. Guess what happens next…
netsim-tools Release 1.1.4
netsim-tools release 1.1.4 includes a number of seemingly unrelated goodies; here’s the the reasoning (or story) behind some of them:
netlab clab tarball creates a tar package that can be deployed with containerlab without netsim-tools
Feedback: Ansible for Networking Engineers
One of ipSpace.net subscribers sent me the following feedback on Ansible for Networking Engineers webinar:
The “Ansible for Network Engineers” webinar is of the highest caliber. I’ve taken Ansible courses with your CCIE peers, and though they are good, I objectively feel, that I get more of a total comprehensive understanding with network automation here at ipSpace. Also, I enjoy your professional care-free tone, and how you pepper humor into the subject matter.
I’ve setup a virtual lab with Ubuntu 18.04 LTS server, and am using both Aruba and Cisco switches/routers. Ansible has lots of nuances that will take me time to fully get a grip-on– but, that’s why I subscribe with the network pros like ipSpace.
Worth Reading: Switching the Technology Stack
Did you ever wonder why a company would replace a working technology with an overhyped pile of half-baked code? Why we at $FAMOUS_COMPANY Switched to $HYPED_TECHNOLOGY by Saagar Jha is a hilarious take on the subject.
Want more? How about migrating your Exadata database to AWS?
Video: Functions-as-a-Service Demo
Serverless computing (marketing term for code running on servers managed by other people) is one of the must-have terms if you’re playing a Buzzword Bingo, but what does it really mean and how does the whole thing work?
Matthias Luft and Florian Barth illustrated the concept during the Introduction to Cloud Computing webinar with a short demo in which they build a simple AWS Lambda function. For a more network-centric view, read the Can We Ping a Lambda Function blog post by Noel Boulene.
Should We Use LISP?
LISP started as yet-another ocean-boiling project focused initially on solving the “we use locators as identifiers” mess (not quite), and providing scalable IPv6 connectivity over IPv4-only transport networks by adding another layer of indirection and thus yet again proving RFC 1925 rule 6a. At least those are the diagrams I remember from the early “look at this wonderful tool” presentations explaining for example how Facebook is using LISP to deploy IPv6 (more details in this presentation).
Somehow that use case failed to gain traction and so the pivots1 started explaining how one can use LISP to solve IP mobility or IP multihoming or live VM migration, or to implement IP version of conversational learning in Cisco SD-Access. After a few years of those pivots, I started dismissing LISP with a short “cache-based forwarding never worked well” counterargument.
Segment Routing vs LDP in Hub-and-Spoke Networks
I got an interesting question that nicely illustrates why Segment Routing (the MPLS variant) is so much better than LDP. Imagine a redundant hub-and-spoke network with hundreds of spokes. Let’s settle on 500 spokes – IS-IS supposedly has no problem dealing with a link-state topology of that size.
Let’s further assume that all routers advertise only their loopbacks1 and that we’re using unnumbered hub-to-spoke links to minimize the routing table size. The global routing table thus contains ~500 entries. MPLS forwarding tables (LFIB) contain approximately as many entries as each router assigns a label to every prefix in the routing table2. What about the LDP table (LIB – Label Information Base)?
Flow-Based Packet Forwarding
In the Cache-Based Packet Forwarding blog post I described what happens when someone tries to bypass the complexities of IP routing table lookup with a forwarding cache.
Now imagine you want to implement full-featured fast packet forwarding including ingress- and egress ACL, NAT, QoS… but find the required hardware (TCAM) too expensive. Wouldn’t it be nice if we could send the first packet of every flow to a CPU to figure out what to do with it, and download the results into a high-speed flow cache where they could be used to switch the subsequent packets of the same flow. Welcome to flow-based packet forwarding.
netsim-tools Release 1.1.3
netsim-tools release 1.1.3 brings a number of goodies, including:
- OSPFv3 support on a few platforms (we’re still looking for contributors to implement OSPFv3 on other platforms)
- EIGRP implementation of common routing protocol features (router ID, passive and external interfaces)
- Configurable address family support for IS-IS, OSPF and EIGRP
- Support for /31 IPv4 P2P links
- Configurable MTU for VyOS and RouterOS
Worth Reading: Misconceptions about Route Origin Validation
Use the email sent by Randy Bush to RIPE routing WG mailing list every time a security researcher claims a technology with no built-in security mechanism is insecure (slightly reworded to make it more generic).
Lately, I am getting flak about $SomeTechnology not providing protection from this or that malicious attack. Indeed it does not.
Worth Reading: AI Makes Animists of Us All
Erik Hoel published a wonderful article describing how he’s fighting the algorithm that is deciding whether to approve a charge on his credit card.
My credit card now has a kami. Such new technological kamis are, just like the ancient ones, fickle; sometimes blessing us, sometimes hindering us, and all we as unwilling animists can do is a modern ritual to the inarticulate fey creatures that control our inboxes and our mortgages and our insurance rates.
There are networking vendors unleashing similar “spirits” on our networks. Welcome to the brave new world ;)
Video: Comparing TCP/IP and CLNP
If you were building networks in early 1990s you probably remember at least a half-dozen different network protocols. Only one of them survived (IPv6 came later), with another one (CLNP) providing an interesting view into a totally different parallel universe that evolved using a different set of fundamental principles.
After introducing the network-layer addressing, I compared the two and pointed out where one or the other was clearly better.
You might think that it makes no sense to talk about protocols that were rarely used in old days, and that are almost non-existent today, but as always those who cannot remember the past are doomed to repeat it, this time reinventing CLNP principles in IPv6-based layer-3-only data center fabrics.
… updated on Wednesday, March 9, 2022 07:44 UTC
Data Plane Quirks in Virtual Network Devices
Have you noticed an interesting twist in the ICMP Redirects saga: operating systems of some network devices might install redirect entries and use them for control plane traffic – an interesting implementation side effect of the architecture of most modern network devices.
A large majority of network devices run on some variant of Linux or *BSD operating system, the only true exception being ancient operating systems like Cisco IOS1. The network daemons populate various routing protocol tables and compute the best routes that somehow get merged into a single routing table that might still be just a data structure in some user-mode process.
… updated on Saturday, March 12, 2022 07:17 UTC
Contribute to netlab: OSPFv3
Every other blue moon I get a question along the lines of “how could I contribute to netlab”. The process is pretty streamlined and reasonably (I hope) documented in Contributor Guidelines; if you want to get started with an easy task, try implementing OSPFv3 for one of almost a dozen devices (vSRX implementation by Stefano Sasso is a picture-perfect example):
Repost: LISP Is a False Economy
Minh Ha left this comment on the Packet Forwarding 101 blog post. As is usually the case, it’s fun reading and it would be a shame not to repost it as a standalone blog post (even though I don’t necessarily agree with all his conclusions).
I always enjoy Bela’s great insights, esp. on hardware and transport networks, but this time I beg to differ. LISP, is a false economy. It was twisted from the start, unscalable right from the get-go. In Networking and OS, to name (ID) something is to locate it, and vice versa. So the name LISP itself reflects a false distinction. Due to this misconception, LISP proponents are unable to establish the right boundary conditions, leading to the size of xTRs’ RIB diverging (going unbounded). In a word, it has come full circle back to BGP, an exemplary manifestation of RFC 1925 rule 6.