… updated on Thursday, February 3, 2022 07:33 UTC
ICMP Redirects Considered Harmful
One of my readers sent me an intriguing challenge based on the following design:
- He has a data center with two core switches (C1 and C2) and two Cisco Nexus edge switches (E1 and E2).
- He’s using static default routing from core to edge switches with HSRP on the edge switches.
- E1 is the active HSRP gateway connected to the primary WAN link.
The following picture shows the simplified network diagram:
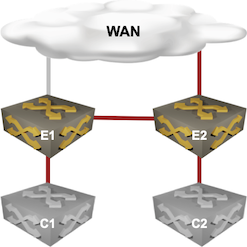
Physical connectivity
All four devices are in the same VLAN, resulting in the following logical connectivity:
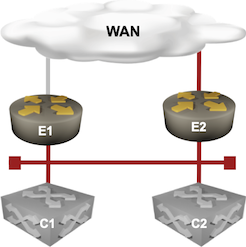
Layer-3 connectivity
He wanted to test the backup WAN link, shut down the primary link without changing the active HSRP gateway, and discovered that the core switches are no longer reachable from the outside world. Changing the HSRP gateway solved the problem. Adding another transit link between E1 and E2, and running a routing protocol on that link instead of on the current VLAN also fixed it.
I had no clue what might have gone wrong, even though the root cause was so obvious in hindsight: ICMP redirects.
C1 and C2 had no idea about the changed routing landscape. When they continued sending the outgoing packets toward E1, E1 sent them ICMP redirects, desperately trying to tell them to send the traffic to E2 instead. There were just a few tiny little problems:
- Linecard hardware cannot send ICMP redirects. All packets that generate a redirect (packets sent out through the same interface) must be forwarded to the main CPU.
- Control Plane Protection – protecting the main CPU – dropped most of those packets.
- IP routers (aka layer-3 switches) ignore ICMP redirects anyway.
Disabling ICMP redirects on the Nexus switches with no ip redirects magically solved the problem.
Considering the impact of this SNAFU, one has to wonder about the Nexus OS default settings:
- ICMP redirects are rarely useful
- Ignoring ICMP redirects on hosts is often considered a “security best practice” – they are almost as good as IPv6 Router Advertisements if you want to snatch someone’s traffic.
- Sending ICMP redirects is a performance killer.
And still, a modern network operating system has an obsolete 40-year-old technology enabled by default (still true on Nexus OS 9.3.8). Mindboggling.
On a tangential note, the current design suffers from traffic trombones: S1 and S2 send outgoing traffic to E1, which forwards it to E2 when the primary WAN link is down. That particular glitch would be easy to fix with anycast gateway or active-active VRRP. The proof is left as an exercise for the reader.
It’s All IETF Fault
Christopher Hart quickly pointed out that an IPv4 router must send ICMP Redirects as mandated by Section 5.2.7.2 of RFC 1812 (Requirements for IP Version 4 Routers).
Routers MUST be able to generate the Redirect for Host message (Code 1)
While ICMP Source Quench messages have been deprecated1 by RFC 6633 (an update to RFC 1812), nothing similar was ever done for ICMP Redirects.
In the weird world of corporate marketing, other vendors’ marketing teams would have a field day (so Christopher) if NX-OS were not an RFC-compliant IPv4 router due to disabled ICMP redirects, even if disabling this behavior by default was a universally good thing.
Cisco IOS initially disabled ICMP redirects on interfaces that had HSRP enabled – Jeroen van Bemmel sent me a link to the relevant page in Cisco IOS in a Nutshell book which was unfortunately last updated over 15 years ago.
It seems that they decided to change that behavior in IOS release 12.1, and added yet another nerd knob in a later IOS release to make it even more complex.
IPv6 requirements are slightly less outdated (RFC 4861 section 8.2, HT Darrell Root):
A router SHOULD send a redirect message, subject to rate limiting, whenever it forwards a packet that is not explicitly addressed to itself (i.e., a packet that is not source routed through the router) in which: [..a list of requirement that causes ICMP redirect to be sent…]
Want to know more? You’ll find way too many details in Christopher’s ICMP Redirects - How Data Plane Traffic Can Become Control Plane Traffic blog post.
But Wait, It Gets Worse
I focused on the sending router, but what happens when a router receives an ICMP redirect? RFC 1812 (same section) contains an interesting loophole (emphasis mine):
A router using a routing protocol (other than static routes) MUST NOT consider paths learned from ICMP Redirects when forwarding a packet.
But what happens to the locally-generated control-plane traffic? Could a router with hardware forwarding (aka a switch) listen to ICMP redirects and install them in the operating system forwarding table which is used for control-plane traffic but not in the forwarding hardware? Dmytro Shypovalov claims he’s seen that in real life:
It gets even uglier if the router accepts ICMP redirects (it shouldn’t by default, but I’ve seen some do). Redirect kernel cache entry is not installed in RIB or FIB, so local and transit traffic to the same destination take different paths.
One has to wonder: how crazy can it get?
Revision History
- 2022-02-23
- Added feedback by Christopher Hart, Darrell Root, Dmytro Shypovalov, and Jeroen van Bemmel.
-
Because nothing ever dies in IETF world ↩︎
You're not wrong, per se. But there are still lots of places where ICMP redirects are all that makes the network work, so blanket-disabling can just cause new problems. (Granted, those problems are usually of the "why would you design a network like this???" variety, and are better served by a redesign than by disabling or enabling ICMP Redirects.)
A "more correct" solution than to disable redirects, since the client using Nexus hardware, might be to deploy vPC and use vPC Peer Gateway instead of HSRP in the first place.
Put another way, the presence or absence of ICMP Redirects is a red herring, usually pointing to architectural/design issues instead. In this example, using vPC Peer Gateway or, better yet, running a minimal IGP instead of relying on static routes, eliminates ICMP Redirects from both the problem and solution spaces simultaneously.
I'm about to write a blog post saying "ICMP redirects are no longer needed", so I would love to see a scenario that still needs ICMP redirects to make the network work, regardless of how broken it is.
But I agree with you, that design is definitely suboptimal, and stumbling upon ICMP redirects is a huge red flag if you care about good design.
I also wonder about a scenario where ICMP redirects are required and would like to learn about one.
An ICMP redirect is intended to instruct the sending system to directly send the IP packets to the next-hop gateway of the gateway sending the ICMP redirect. This allows to use a path that is shorter by one router hop. Thus it is an optimization that should not be needed for correct packet transport. Thus if this optimization results in worse performance, it seems prudent to disable it.
I have seen many networks that function fine with disabled ICMP redirects. Those include both networks with manually disabled ICMP redirects and those where vendor defaults regarding disabled ICMP redirects were kept.
I can think of situations where an extra hop leads to problems due to TTL (think of hop count), but in such a situation the root cause is using a too low TTL value or lack of (or misconfigured) dynamic routing to ensure use of the intended path.
Another possibility I can think of could be overloaded links due to using a suboptimal gateway. But this can only be mitigated by ICMP redirects if ICMP redirect processing does not significantly impact forwarding performance by itself.
I am well aware that I cannot know all possible scenarios and thus would like to learn of an example where ICMP redirects make the network work.
[BTW in the scenario described in the blog post, changing the active gateway according to uplink state (e.g., via interface or object tracking and preemption) would have avoided ICMP redirect generation, too.]
To add to the point of using real hardware for testing, don’t overlook any redundancy/fail-over states and protocols in your design that may rely on ICMP redirect usage in some manner.
Funny, this topic reminded me on early use cases for ICMP redirect. Back in the old days(late 80s early 90s) where you had a segment with two routers connected to it some used ICMP redirect as a poor man’s fail over solution. You would set your workstation's default GW to your own address and ARP on everything but if an upstream prefix was not available on R1, R1 would send ICMP redirect to your workstation to go to R2 for that prefix, you ARP, then go through R2. If you lost R1 completely you would ARP anyway and get R2. I believe this was before you can have two default GWs set or before DHCP to set GW.
A bit chatty on the wire but it worked.
I tried to do something similar on a Cisco router. It didn't end well...
https://blog.ipspace.net/2009/10/my-stupid-moments-interface-default.html
FWIW, Nexus can learn redirects, but its TCAM table size is zero by default.
Second, I would never build this as shown but, if I had to, HSRP with object tracking (https://www.cisco.com/c/en/us/td/docs/switches/datacenter/nexus9000/sw/6-x/unicast/configuration/guide/l3_cli_nxos/l3_hsrp.html#87823)
Third, redirects are just a symptom. The root cause are STATIC ROUTES.
E.g, what's not said is how the reader had E1 and E2 routing configured. We assume that E1 has "ip route 0.0.0.0/0 <WAN next-hop>" and floating static "ip route 0.0.0.0/0 <E2 next-hop> 201", but that's not the only way to do it.
If the routing table has other, less-specific routes that overlap the WAN next-hop, then the switch would recursively route the default route, rather than withdraw it. Novice engineers can be flummoxed by recursive routing. To get things working, some turn to interface next-hops ("ip route 0.0.0.0/0 <WAN interface>") which appear to work well as long as the upstream does proxy ARP (an IOS/IOS-XE default). Unfortunately with interface next-hop, each destination becomes a host route and E1's host eventually table blows up.
With static routes, there are hundreds of such ways to shoot yourself in the foot because of their interaction with ICMP redirects, ARP , ICMP TTL exceeded loops, interface state, recursive routing, .... Add in VPC/MLAG and HSRP behavior is turned on its head. Sprinkle in storage arrays or load-balancers that do non-RFC compliant forwarding (eg, F5 "auto last hop"), and all forwarding assumptions are out the window. That L3 switch might as well be a blender without a lid.
An all-too-common result is that the network evolves with enough duct tape static routes and google-fu to get hosts talking, but the actual forwarding mechanisms at work are beyond the operator's comprehension. They now operate a brittle network where any little change might have big side effects.