Blog Posts in February 2021
Video: High-Level Technology Guidelines
I concluded the Focus on Business Challenges First presentation (part of Business Aspects of Networking Technologies webinar) with a few technology guidelines starting with:
- Be vendor-agnostic (always look around to see what others are doing);
- Try to understand how the technology you’re evaluating works (it will help you spot the potential problems before they crash your network);
- Always select what’s best for your business, not for the sales quota of your friendly $vendor account manager.
For more guidelines, watch the video.
Does Unequal-Cost Multipathing Make Sense?
Every now and then I’m getting questions along the lines “why doesn’t X support unequal-cost multipathing (UCMP)?” for X in [ OSPF, BGP, IS-IS ].
To set the record straight: BGP does support some rudimentary form of unequal-cost multipathing with the DMZ Bandwidth community, but it only works across multiple egress points from a single autonomous system. Follow-up nerd knobs described how to use the same community over EBGP sessions; not sure whether anyone implemented that part (comments welcome).
Routing in Stretched VLAN Designs
One of my readers was “blessed” with the stretched VLANs requirement combined with the need for inter-VLAN routing and sub-par equipment from a vendor not exactly known for their data center switching products. Before going on, you might want to read his description of the challenge he’s facing and what I had to say about the idea of building stackable switches across multiple locations.
Here’s an overview diagram of what my reader was facing. The core switches in each location work as a single device (virtual chassis), and there’s MLAG between core and edge switches. The early 2000s just called and they were proud of the design (but to be honest, sometimes one has to work with the tools his boss bought, so…).
Virtual Networks and Subnets in AWS, Azure, and GCP
Now that we know what regions and availability zones are, let’s go back to Daniel Dib’s question:
As I understand it, subnets in Azure span availability zones. Do you see any drawback to this? Does subnet matter if your VMs are in different AZs?
Wait, what? A subnet is stretched across multiple failure domains? Didn’t Ivan claim that’s ridiculous?
TL&DR: What I claimed was that a single layer-2 network is a single failure domain. Things are a bit more complex in public clouds. Keep reading and you’ll find out why.
MUST READ: Designing a Simple Disaster Recovery Solution
A few weeks ago Adrian Giacometti described a no-stretched-VLANs disaster recovery design he used for one of his customers.
The blog post and related LinkedIn posts generated tons of comments (and objections from the usual suspects), prompting Adrian to write a sequel describing the design requirements he was facing, tradeoffs he made, and interactions between server and networking team needed to make it happen.
Worth Reading: How To Put Faith in $someTechnique
The next time you’re about to whimper how you can’t do anything to get rid of stretched VLANs (or some other stupidity) because whatever, take a few minutes and read How To Put Faith in UX Design by Scott Berkun, mentally replacing UX Design with Network Design. Here’s the part I loved most:
[… ]there are only three reasonable choices:
- Move into a role where you make the important decisions.
- Become better at influencing decision makers.
- Find a place to work that has higher standards (or start your own).
Unfortunately the most common choice might be #4: complain and/or do nothing.
Podcast: State of Networking (Early 2021)
In January, Jason Edelman kindly invited me for a chat about the state of (software defined) networking and network automation in particular. The recording was recently published on Network Collective.
Data Model Transformations in Network Automation Solutions
Last year I wrote an article describing data model optimization going from a simple this is what we need to configure individual devices to a highly polished high-level network nodes and links model. Not surprisingly, as Jeremy Schulman was quick to point out, the latter one had Jinja2 templates you wouldn’t want to debug. Ever. You can’t run away from complexity… but you can manage it.
Many successful network automation solutions (example: Cisco NSO) solve the “we’d love to work with high-level data models but hate complex templates” challenge with data transformation: operators work with an abstracted data model describing services, nodes and links, and the device configuration templates use low-level data derived from the abstracted data models through a series of business logic rules or lookups (aka network design).
Link-State Routing Protocols Are Eventually Consistent
One of my readers sent me this interesting question:
Assuming we are running a very large OSPF area with a few thousand nodes. If we follow the chain reaction of OSPF LSA flooding while the network is converging at the same time, how would all routers come to know that they all now have same view of area link states and there are no further updates or convergence?
I have bad news: the design requirements for link state protocols effectively prevent that idea from ever working well.
Availability Zones and Regions in AWS, Azure and GCP
My friend Daniel Dib sent me this interesting question:
As I understand it, subnets in Azure span availability zones. Do you see any drawback to this? Does subnet matter if your VMs are in different AZs?
I’m positive I don’t have to tell you what networks, subnets, and VRFs are, but you might not have worked with public cloud availability zones before. Before going into the details of Daniel’s question (and it will take us three blog posts to get to the end), let’s introduce regions and availability zones (you’ll find more details in AWS Networking and Azure Networking webinars).
Rant: Don't Ever Compare Enterprise IT Shenanigans with Apollo 13
Here’s a recent tweet by my friend Joe Onisick that triggered this blog post:
My favorite people are the ones that start with “how could we make that work?” Before jumping into all of their preconceived bs on why it won’t work.
I couldn’t agree more with that sentiment. The number of people who would invent all sorts of excuses just to avoid turning on their brains and keep to their cozy old methods is staggering. Unfortunately, someone immediately had the urge to switch into what I understood to be a heroic MacGyver mode (or maybe it was just my lack of caffeine, in which case I apologize for the misquote… but you might still like the rest of the rant):
Worth Reading: Internet of Trash
I love the recent Internet of Trash article by Geoff Huston, in particular this bit:
“Move fast and break things” is not a tenable paradigm for this industry today, if it ever was. In the light of our experience with the outcomes of an industry that became fixated on pumping out minimally viable product, it’s a paradigm that heads towards what we would conventionally label as criminal negligence.
Of course it’s not just the Internet-of-Trash. Whole IT is filled with examples of startups and “venerable” companies doing the same thing and boasting about their disruptiveness. Now go and read the whole article ;)
Worth Reading: Advice(s) for Engineering Managers
Just in case you were recently promoted to be a team leader or a manager: read these somewhat-tongue-in-cheek advices:
- How do I feel worthwhile as a manager when my people are doing all the implementing? by Charity Majors
- The Non-psychopath’s Guide to Managing an Open-source Project by Kode Vicious.
Need more career advice? How about The Six Year Rule by Bryan Sullins… or you could go and reread my certifications-related blog posts.
Video: Cisco SD-WAN Policies Review
The second part of the Cisco SD-WAN webinar focused on design considerations and trade-offs in several scenarios. David Penaloza briefly reviewed the types of policies and their capabilities before discussing what to keep in mind when designing the solution.
Repost: On the Importance of Line-Rate Switching of Small Packets
I made a flippant remark in a blog comment…
While it’s academically stimulating to think about forwarding small packets (and applicable to large-scale VoIP networks), most environments don’t have to deal with those. Looks like it’s such a non-issue that I couldn’t find recent data; in the good old days ~50% of the packets were 1500 byte long.
… and Minh Ha (by now a regular contributor to my blog) quickly set me straight with a lengthy comment that’s too good to be hidden somewhere at the bottom of a page. Here it is (slightly edited). Also, you might want to read other comments to the original blog post for context.
State Consistency in Distributed SDN Controller Clusters
Why Can't We Have Good Things Like Partition-Resilient SDN Controllers
Every now and then I get a question along the lines of “why can’t we have a distributed SDN controller (because resiliency) that would survive network partitioning?” This time, it’s not the incompetency of solution architects or programmers, but the fundamental limitations of what can be done when you want to have consistent state across a distributed system.
TL&DR: If your first thought was CAP Theorem you’re absolutely right. You can probably stop reading right now. If you have no idea what I’m talking about, maybe it’s time you get fluent in distributed systems concepts after you’re finished with this blog post and all the reference material linked in it. Don’t know where to start? I put together a list of resources I found useful.
Demonstrate Small Automation Wins
Long long time ago in a country far far away when traveling was still a thing I led an interesting data center fabric design workshop. We covered tons of interesting topics, including automating network services deployments (starting with VLAN self-service for server admins).
As was often the case in my workshops, we had representatives from multiple IT teams sitting in the room, and when I started explaining how I’d automate VLAN deployments, the server administrator participating in the workshop quickly chimed in: “that’s exactly how I implemented self-service for some of our customers, it makes perfect sense to use the same approach for server port and VLAN provisioning”, and everyone else in the room agreed… apart from the networking engineer, who used a counter-argument along the lines of “we only provision a new VLAN or server port every few days, we can do it by hand” and no amount of persuasion would move him.
OMG, It's Graphs Everywhere
One of the subscribers watching the Graph Algorithms in Networks webinar found the webinar had an interesting impact on his perspective (according to his feedback):
This is genuine content that I haven’t seen anywhere else. It helps to get up to speed on computer science topics that are relevant to network professionals. After attending this webinar, I couldn’t unsee the graphs anymore that are almost everywhere in networking.
This webinar is now free, as are other webinars by Rachel Traylor, including Network Connectivity, Graph Theory, and Reliable Network Design and Queuing Theory.
Worth Reading: Visualizing BGP-LS Tables
When I’d first seen BGP-LS I immediately thought: “it would be cool to use this to fetch link state topology data from the network and build a graph out of it”. In those days the only open-source way I could find to do it involved Open DayLight controller’s BGP-LS-to-REST-API converter, and that felt like deploying an aircraft carrier to fly a kite.
Things have improved dramatically since then. In Visualizing BGP-LS Tables, HB described how he solved the challenge with GoBGP, gRPC interface to GoBGP, and some Python code to parse the data and draw the topology graph with NetworkX. Enjoy!
Worth Reading: Finding Bugs in C and C++ Compilers
Something to keep in mind before you start complaining about the crappy state of network operating systems: people are still finding hundreds of bugs in C and C++ compilers.
One might argue that compilers are even more mission-critical than network devices, they’ve been around for quite a while, and there might be more people using compilers than configuring network devices, so one would expect compilers to be relatively bug-free. Still, optimizing compilers became ridiculously complex in the past decades trying to squeeze the most out of the ever-more-complex CPU hardware, and we’re paying the price.
Keep that in mind the next time a vendor dances by with a glitzy slide deck promising software-defined nirvana.
Video: Finding Paths Across the Network
Regardless of the technology used to get packets across the network, someone has to know how to get from sender to receiver(s), and as always, you have multiple options:
- Almighty controller
- On-demand dynamic path discovery (example: probing)
- Participation in a routing protocol
For more details, watch Finding Paths Across the Network video.
MUST READ: Fast and Simple Disaster Recovery Solution
More than a year ago I was enjoying a cool beer with my friend Nicola Modena who started explaining how he solved the “you don’t need IP address renumbering for disaster recovery” conundrum with production and standby VRFs. All it takes to flip the two is a few changes in import/export route targets.
I asked Nicola to write about his design, but he’s too busy doing useful stuff. Fortunately he’s not the only one using common sense approach to disaster recovery designs (as opposed to flat earth vendor marketectures). Adrian Giacometti used a very similar design with one of his customers and documented it in a blog post.
Impact of Centralized Control Plane Partitioning
A long-time reader sent me a series of questions about the impact of WAN partitioning in case of an SDN-based network spanning multiple locations after watching the Architectures part of Data Center Fabrics webinar. He therefore focused on the specific case of centralized control plane (read: an equivalent of a stackable switch) with distributed controller cluster (read: switch stack spread across multiple locations).
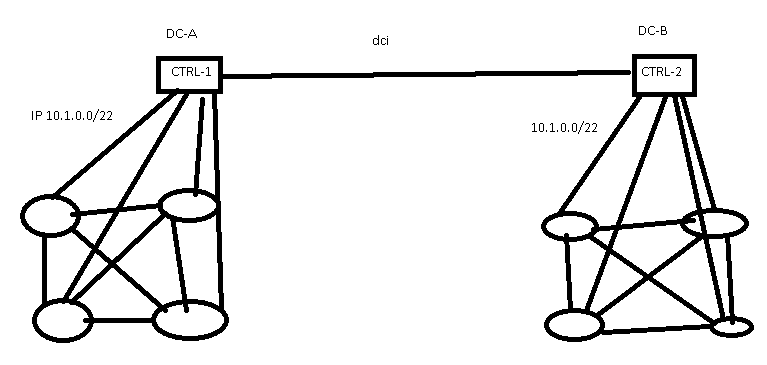
SDN controllers spread across multiple data centers
Rant: Broadcom and Network Operating System Vendors
Minh Ha left the following rant as a comment on my 5-year-old What Are The Problems with Broadcom Tomahawk? blog post. It’s too good to be left gathering dust there. Counterarguments and other perspectives are highly welcome.
So basically a lot of vendors these days are just glorified Broadcom resellers :p. It’s funny how some of them try to up themselves by saying they differentiate their offerings with their Network OS.
Thank You for All the Great Work Miha
Almost exactly a year ago Miha Markočič joined the ipSpace.net team. He was fresh out of university, fluent in Python, but with no networking or automation background… so I decided to try my traditional method of getting new team members up to speed: throw them into the deep water, observe how quickly they learn to swim, and give them a few tips if it seems like they might be drowning.
It worked out amazingly well. Miha quickly mastered the intricacies of AWS and Azure, and created full-stack automation solutions in Ansible, Terraform, CloudFormation and Azure Resource Manager to support the AWS and Azure webinars, and the public cloud networking online course.