Weird: Wrong Subnet Mask Causing Unicast Flooding
When I still cared about CCIE certification, I was always tripped up by the weird scenario with (A) mismatched ARP and MAC timeouts and (B) default gateway outside of the forwarding path. When done just right you could get persistent unicast flooding, and I’ve met someone who reported average unicast flooding reaching ~1 Gbps in his data center fabric.
One would hope that we wouldn’t experience similar problems in modern leaf-and-spine fabrics, but one of my readers managed to reproduce the problem within a single subnet in FabricPath with anycast gateway on spine switches when someone misconfigured a subnet mask in one of the servers.
Imagine the following FabricPath network (diagram taken from Data Center Fabric Architectures webinar):
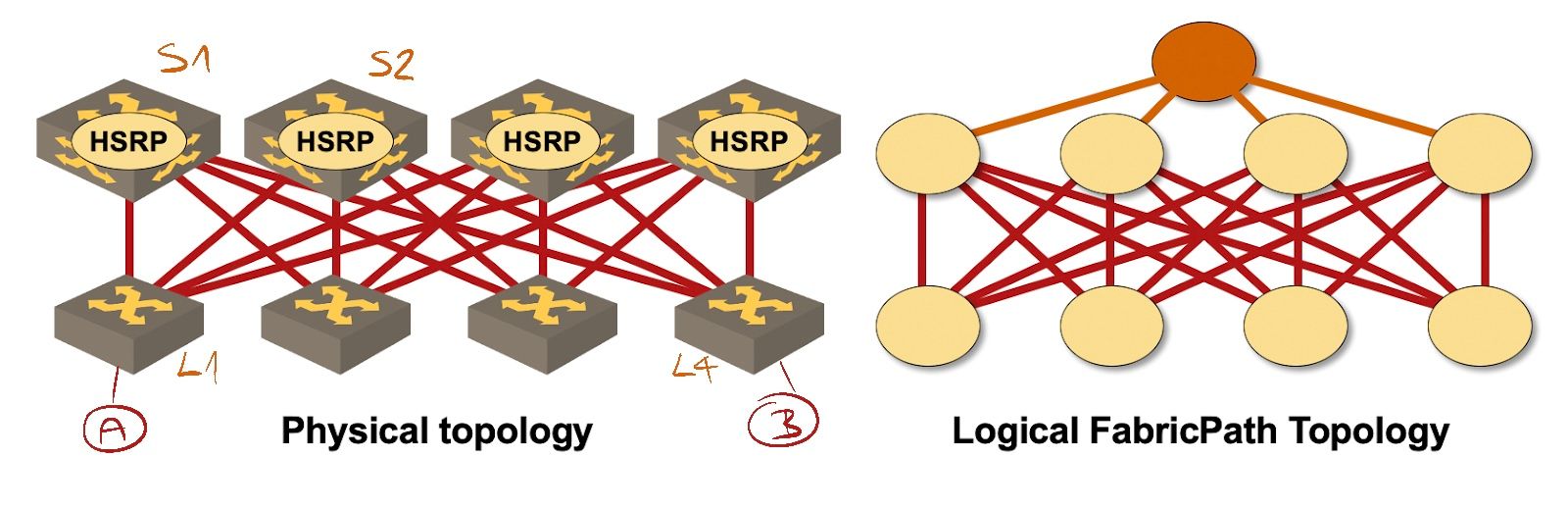
FabricPath Leaf-and-Spine Fabric
Server A attached to leaf L1 has incorrect subnet mask 255.255.255.255, whereas server B attached to leaf L2 has correct subnet mask 255.255.255.0.
When A sends a packet to B, it does not send an ARP request for B, but uses default gateway (anycast gateway on spine switches) due to incorrect subnet mask. The spine switch receiving the packet (let’s assume it’s S1) routes it, and sends it back into the same subnet toward B. The routed packet has S1’s source MAC address (SMAC), thus nobody but L1 and S1 see A’s SMAC.
When B sends a packet to A, it does send an ARP request for A, and when the reply comes back (with A’s SMAC) all switches know where A is… until the MAC table entry for A times out, and that’s when the unicast flooding starts. L4 has no idea where A is (and it never sees any traffic from A, see above), and the only thing it can do is to flood unicast traffic toward A.
Got it? Now try to figure out:
- Would you observe the same behavior in non-EVPN VXLAN fabrics with anycast gateway configured on leaf switches?
- Would EVPN solve the problem?
- Bonus question (and I have no clue what the answer is): what would you see in an Avaya (now Extreme) SPB fabric?
It would be great to see a few answers in the comments, but do wait a day or two before posting them.
More Information
You might find these webinars useful when trying to answer the above questions:
- Leaf-and-Spine Fabric Architectures
- EVPN Technical Deep Dive
- Data Center Fabric Architectures - www.ipSpace.net
You might also want to read these blog posts to understand how anycast gateway on leaf switches works (the blog posts talk about Arista’s VARP, but that’s just terminology):
How about setting the MAC aging time to a high value on the switches , Would it be a good protection for this kind of behavior ?
Ivan, re EVPN, I think it was designed to deal with, among other things, this situation, with its route type 2 and ARP suppression. Assuming the leaf switches here are PE running the anycast gateway, S1 will snoop A's ARP and create the routes for A. EVPN propagates this update in the underlay to all other interested VTEPs. So L4 will be eventually-consistent with L1 wrt knowledge of A. Even when the MAC table entry times out first due to badly designed timers, one route type 2 of A will be wiped but not the other created by ARP snooping, that one will stand as long as ARP hasn't timed out, AFAIK anyway. So with any decent implementation, L4 can take a look at the RIB and see the MAC+IP route for A and forward it to L1 across the underlay. With this 2-level fabric, it doesn't matter whether you use MPLS or VXLAN as transport.
If one adds another superspine layer to the fabric, and the spines now become the PE, EVPN logics still prevent this flooding, then things get complicated fast with ESI and split-horizon, and the amount of flooding will increase nonetheless vs the 2-layer case because DF election doesn't prevent BUM from being sent to non-DF, only has them drop it on reception. IMO, in this situation with 3 layers and ESI and everything, EVPN MPLS is superior to EVPN VXLAN because it allows the handling BUM traffic and loop prevention in a simpler and therefore more elegant and robust way. The VXLAN's way of dealing with this sounds more like a kludge to me, due to its inability to do stacking. And with MPLS, one can also achieve valley-free routing even in that kind of complex fabric, if one insists on it.
And I'm not sure why people still want to run SPB in 2020. Sounds like RFC 1925 rule 3.
Sorry, the 2nd paragraph in my comment should read like this (would be great if comments are editable here Ivan :))
If one adds another superspine layer to the fabric and the spines now become the PE, then things get complicated fast with ESI and split-horizon. EVPN logics still prevent this flooding, but the amount of flooding will increase nonetheless vs the 2-layer case because DF election doesn't prevent BUM from being sent to non-DF, only has them drop it on reception. IMO, in this situation with 3 layers and ESI and everything, EVPN MPLS is superior to EVPN VXLAN because it allows the handling BUM traffic and loop prevention in a simpler and therefore more elegant and robust way. The VXLAN's way of dealing with this sounds more like a kludge to me, due to its inability to do stacking. And with MPLS, one can also achieve valley-free routing even in that kind of complex fabric, if one insists on it, again thanks to label stacking.
@Joe: Increasing MAC timer would help in the original scenario (where MAC table aged out before ARP table), but not in this one.
@Minh Ha: I would keep things simpler and have VXLAN encapsulation on the fabric edge, not in the middle (spine) layer.
Ivan, I don't know if by now you've found the answer to the 3rd question, but it seems I've come across it by accident the other day, when searching your blogs for old posts on SPB.
On this one, Ludovico, who worked for Avaya, made some comments about the mechanics of their SPB platform:
https://blog.ipspace.net/2014/04/is-is-in-avayas-spb-fabric-one-protocol.html
Reading through it, and looks like they've implemented their product very much aligned with SPBM standard. So essentially the MAC learning part is all data-plane, much like VPLS, Fabric Path and the likes.
The reason EVPN can be safe to this unicast flooding behaviour is because it implements control-plane learning of MAC in addition to data-plane flood-and-learn, so it has an additional source of truth to check when needing info. The pure data-plane products are therefore, all stuck with this flooding vulnerability.
So looks like that would address question 1 as well, as this condition applies to all data-plane-learning only fabrics :)) .
And yes, I'll still stick to my original view that SPBM, itself being a great engineering effort, is still an effort to make pigs fly nonetheless. Reason being they try to force-fit a hierarchical paradigm (IP) into a flat scheme (Ethernet).