BGP AS Numbers on MLAG Members
I got this question about the use of AS numbers on data center leaf switches participating in an MLAG cluster:
In the Leaf-and-Spine Fabric Architectures you made the recommendation to have the same AS number on all members of an MLAG cluster and run iBGP between them. In the Autonomous Systems and AS Numbers article you discuss the option of having different AS number per leaf. Which one should I use… and do I still need the EBGP peering between the leaf pair?
As always, there’s a bit of a gap between theory and practice ;), but let’s start with a leaf-and-spine fabric diagram illustrating both concepts:
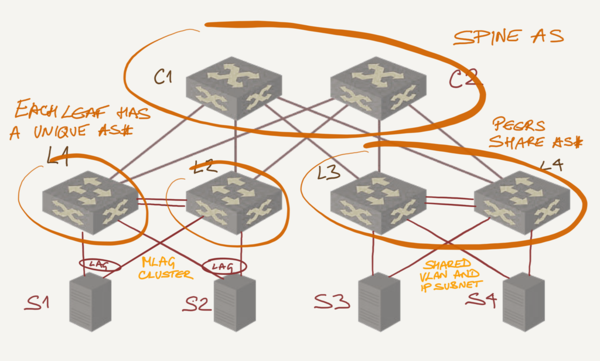
Unique versus shared AS Numbers
In theory, it feels right to have the same AS number for all members of an MLAG cluster (L3 and L4 in the above diagram). After all, they advertise the same subnets. If you go for that design, run IBGP on the peering link.
In practice, dealing with “these two switches have to have the same AS number” creates additional complexity when you want to standardize configurations as well as corner cases in configuration templates. After a lengthy discussion with Dinesh Dutt we came to the conclusion that while using different AS numbers on MLAG members (L1 and L2 in the above diagram) doesn’t feel right from BGP perspective, simplified configurations might be more important.
Regardless of which design you choose, you still need BGP peering between MLAG members. One of them might lose a subnet (all ports in the subnet VLAN) and needs to know its peer still has it. However, there’s any need for additional filtering on the inter-leaf BGP session. In the EBGP case, the leaf-to-spine path will always be better (due to shorter AS path length) than leaf-leaf-spine path; in the IBGP case the external path will be preferred over the internal one.
More Details
- Start with the Data Center BGP article
- Explore Leaf-and-Spine Fabric Architectures webinar
- If you’re interested in deploying EVPN in your data center fabric, I can highly recommend the EVPN Technical Deep Dive webinar
Need even more details? Explore our BGP in Data Center Fabrics series.
Hi Ivan,
First, thanks a lot for all the quality content you produce and for this post.
Two things i'd like to discuss:
The eBGP session between the MLAG pair is an 'underlay' peering right ? (evpn af activated). I don't see any value in running overlay peering in each customer VRF there... but I may be wrong ? Can you confirm or precise what peering type your were thinking of ?
Imagine the case we have a ToR pair but without MLAG, running eBGP with downstream servers (i don't say it's good, but...). Would you run the same setup ?
eBGP seems fine overall as you don't deal with iBGP loop prevention rules and knobs, which is translated in a more straightforward configuration, but it does not change the fact that you have to clearly "lock" what the pair of switches advertise.
Thank you,
Hi,
You REALLY SHOULD watch the two webinars I mentioned at the end of the blog post, here are a few short answers:
Hope this helps, Ivan