The Myth of Scaling From On-Premises Data Center into a Public Cloud
Every now and then someone tries to justify the “wisdom” of migrating VMs from on-premises data center into a public cloud (without renumbering them) with the idea of “scaling out into the public cloud” aka “cloud bursting”. My usual response: this is another vendor marketing myth that works only in PowerPoint.
To be honest, that statement is too harsh. You can easily scale your application into a public cloud assuming that:
- You have a scale-out architecture with eventually-consistent database at the bottom;
- You have already learned how to deploy independent swimlanes (totally uncoupled application stacks), how to synchronize data between them, and how to handle inevitable conflicts;
- You are already replicating data into a public cloud (for example for backup purposes).
Turning the replicated data that already reside in a public cloud into yet another swimlane is a piece of cake (assuming you also figured out infrastructure-as-code-based deployments). Add another entry to your DNS-based load balancing and you’re done.
However, that’s not what the enterprise-focused $vendor evangelists have in mind. Here’s a typical explanation, courtesy of Piotr Jablonski:
What about a use case for development/staging where the company want to test a new app on 10 servers and they have 2 on-prem and they don’t need to wait for new hardware? They can run 8 servers or more in the cloud. For a production use case, if workloads are contained, then scaling-out a particular app layer is a viable option. Do you think a VPN/interconnect/DCI kills benefits of the scale-out?
I have just one word for that idea: latency.
Here’s a longer explanation I gave in the Designing Active-Active and Disaster Recovery Data Centers webinar.
Assume you have a typical multi-layer application stack consisting of a web server, an application server, a database server, and a storage array (and don’t get me started on what happens when you decide to replace that with microservices ;).
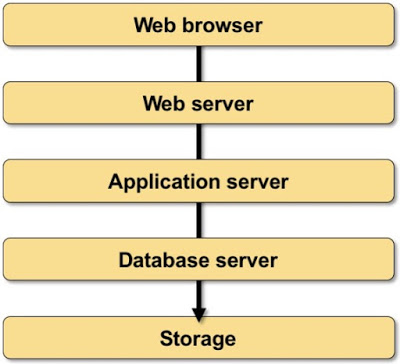
Typical application stack
Now imagine that layer X has to make N requests to layer X-1 to satisfy a request coming from the client. In a typical scenario the number of requests increase down the stack (more so if the developers never mastered the dark art of SQL JOIN statement) - supposedly over 90% of the traffic stays within large data centers.
The number of requests made between layers of an application stack typically doesn’t matter if the underlying server is fast enough, and if the latency is negligible (end-to-end latency in a data center is measured in microseconds)… but what happens if you increase the latency between parts of your application stack?
To illustrate that, let’s draw boxes between individual layers of an application stack, with the width of the box indicating the number of requests, and the height of the box indicating latency. The area of the box is then the total time a component of an application stack has to wait for data while processing a client request. That time is usually directly added to whatever usual response time your application has, as most applications haven’t been written with asynchronous processing and/or multithreading in mind.
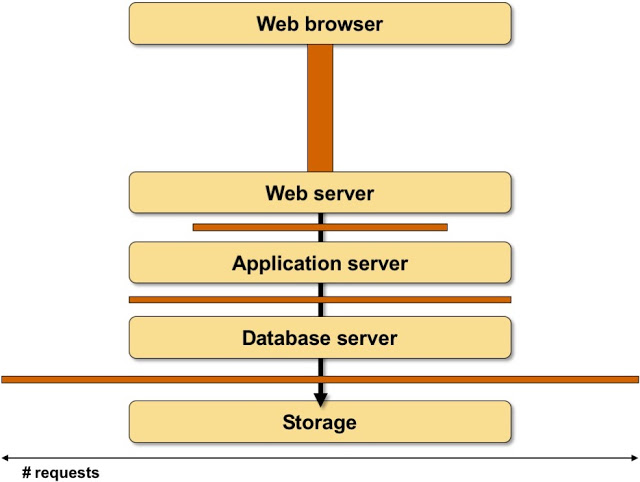
Latency added to the application stack
Now imagine you increase latency between application stack components. Some of the boxes grow ridiculously large.
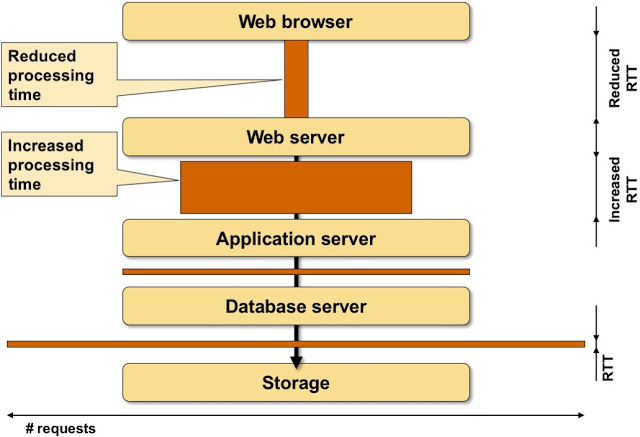
The effects of increased latency between application stack components
Of course you might argue that having an application with 10- or 100-second response time (instead of the usual 100 msec one) is useful. YMMV, but please don’t waste everyone else’s time.
To recap: cloudbursting should stay in PowerPoint.
Finally, what could you do if your organization got infected by this particular strain of stupidity? If your applications run on Linux add artificial latency (at least one RTT worth of it) using tc to the components that should be moved into the public cloud, lean back and enjoy the results. Need even more cloud marketing antidote? You might get it in our Networking in Public Cloud Deployments online course.
For the switching network -> yes, it can be a single digit microseconds. But when we include a FW then we have 50+ usecs additionally, over 200 usecs if a cluster of FW is there. Next when we add OSs it can be another hundreds of usecs, and when the app reads the data from SSD disks, it becomes miliseconds (1MB takes 1ms). If a local data center is close to the public cloud data center, like 20km, it is just about 55 microseconds on top of the end-to-end latency. So scaling out is possible as the latency tax is comparable to one router e.g. Cisco ASR9k.
You cited me "For a production use case, if workloads are contained, then scaling-out a particular app layer is a viable option."
Here is the important part -> "if workloads are contained". This helps to keep latency at the minimum level and avoid tromboning effects or even a single passing of data across VPN within the application. Just for storage replication. This is simple math, not a typical $vendor's evangelist explanation. ;)
Of course, a tax latency increases quickly, so scaling out becomes possible for fully contained applications only.
It seems to me we're having the same discussion in various disguises for at least a decade (from the times you were working at Cisco when we first met at PLNOG), and they always go along the same lines:
* Someone makes a ridiculous claim using the magic technologies of L2DCI and vMotion;
* I point out why it's ridiculous (and it's usually pretty simple to do that);
* You find a corner case where it might work with a lot of assumptions, proper engineering etc.
I honestly don't care if you managed to implement a solution that should better be left in PowerPoint to solve a particularly pressing business need... after all, I did design a network with 20+ parallel EIGRP processes and route redistribution between them... but there's difference between:
* doing something that needs to be done;
* talking about that in public without clearly stating all the assumptions, prerequisites and limitations;
* marketing that as the best thing since sliced bread.
When you're making comments in public, you're influencing the thinking of other people, so please (at the very minimum) do no harm. See also https://blog.ipspace.net/2016/01/whatever-happened-to-do-no-harm.html
In this topic in the comment section:
https://blog.ipspace.net/2020/02/live-vmotion-into-vmware-on-aws-cloud.html
I wrote: "Stretching workload belonging to the same traffic group and a subnet should be avoided as much as possible".
This is a clear statement that we want both do what needs to be done with no harm.
What I would like to avoid is an overgeneralization. Every technology can become a corner case even EVPN with BGP in a data center (without IGP). Especially with the advent of new solutions. The same applies to EIGRP, IP LFA, L2 DCI etc. I discussed with you on one topic about "all the assumptions, prerequisites and limitations". Then you stopped and moved to the other blog post. Naturally, all assumptions become dispersed. Taking a snippet of my statement, moving to the next page, saying that it is a typical $vendor's claim is another overgeneralization but put in the context of a person. That is not fair. As a workaround, I will try to copy all the assumptions in any public post in discussions with you. I hope it will be ok.
Sometimes I get tired of comment thread format, so I write a new blog post going into more details, but I always link back to the source comment, so anyone interested in the context can figure it out. I used that same link, checked what you wrote, and you never ever mentioned "latency". Now that I bring it up, your answer is "but of course I considered that, and you got it wrong, because latency across a firewall is higher than the latency across a switch". Whatever.
As for overgeneralization, the "drive slowly, the road is icy" advice is also an overgeneralization, as it clearly does not apply to Finnish rally drivers. Does that mean that it doesn't apply to the rest of us?
I'm stopping my side of this debate right here, as it's clear we're not getting anywhere, and wish good luck to whoever wants to try out cloudbursting ideas in real life.
I have nothing against moving a discussion to a new blog post. My only objection is that, meantime, based on our unfinished conversation, you composed a message of "a typical explanation of the enterprise-focused $vendor evangelist". Agree, such a conclusion can be an effect of the unfinished conversation. That's why I tried to explain my point of view giving as precise latency numeric values as possible. Someone who doesn't think about latency doesn't have them in mind, isn't it?
I think the networking community needs technical discussions even if there are some temporary grudges. Thank you for your blog posts and interesting topics! All the best! :)
- Asynchronous approach (in opposite to synchronous one) - is not so deterministic. Any request could finish in different order, and in result - you will get very different UI experience even in similar initial conditions.
- Instead on focusing on determinism and optimizations, better protocol and infrastructure - you follow initially limited design.
- If you want scalability and quality of solution - you should scale your database, because database is the most bottleneck. Proper sharding can give you maximum performance and quality (ACID) for most application cases. If done properly - you still have to implement ACID manually - for rare set of operations that accept latency/rollback.
- For best performance and user-experience - you should plan data-center & application architecture. The statement - Just move to cloud - doesn't solve scalability issues.