Layer-3 Switching over VXLAN Revisited
My Trident 2 Chipset and Nexus 9500 blog post must have hit a raw nerve or two – Bruce Davie dedicated a whole paragraph in his Physical Networks in Virtualized Networking World blog post to tell everyone how the whole thing is a non-issue and how everything’s good in the NSX land.
It’s always fun digging into more details to figure out what’s really going on behind the scenes; let’s do it.
What I Really Claimed
Here’s what I wrote in my blog post:
Trident 2 chipset doesn’t support routing of VXLAN-encapsulated packets […] by the time the chipset figures out it’s the overlay tunnel endpoint for the incoming packet, and performs the L2 lookup of the destination MAC address, it’s too late for another L3 lookup.
The steps needed to get from the physical to the virtual world (VLAN-to-VXLAN) are totally different than the steps needed to get from the virtual to the physical world (VXLAN-to-VLAN). In the first case, a layer-3 switch (aka router):
- Receives a Ethernet packet, potentially with 802.1q tag;
- Performs L2 lookup to figure out the destination MAC address belong to the router (triggering L3 lookup);
- Performs L3 lookup to find the next hop;
- Adds next-hop specific encapsulation to the packet and sends the packet to the output interface queue.
So far the only difference between a traditional L3 switch and a VXLAN-capable L3 switch is the ability to prepend any header in front of the packet instead of swapping the MAC header. Any platform with scatter-gather capability could do this for decades.
Receiving a VXLAN-encapsulated L2 packet and performing L3 lookup at the egress is a totally different story. A layer-3 switch:
- Receives a payload-in-VXLAN-in-IP-in-MAC Ethernet packet;
- Performs a L2 lookup, which triggers L3 lookup;
- Performs L3 lookup and figures out the packet is sent to its VTEP IP address;
- Extracts original payload from VXLAN envelope;
- Performs another L2 lookup, which triggers L3 lookup;
- Performs another L3 lookup to find the next hop;
- Swaps MAC header and sends the packet to the output interface queue.
The parts marked in red are the ones that some platforms cannot do.
Hardware limitations on tunnel egress router are nothing new – Catalyst 6500 couldn’t perform hardware decapsulation of MPLS-over-GRE-over-IPsec packets (at least with the linecards we had) even though it could do individual operations in hardware.
What did VMware do?
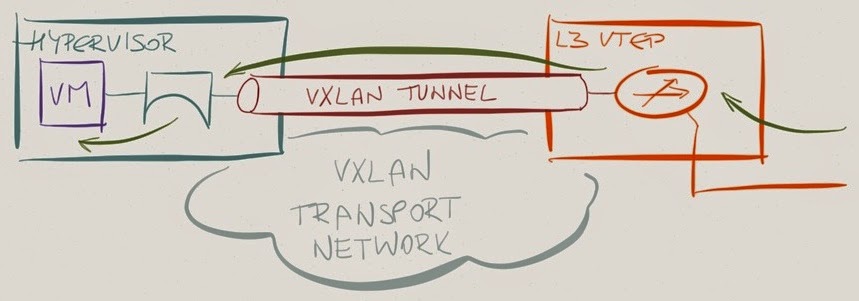
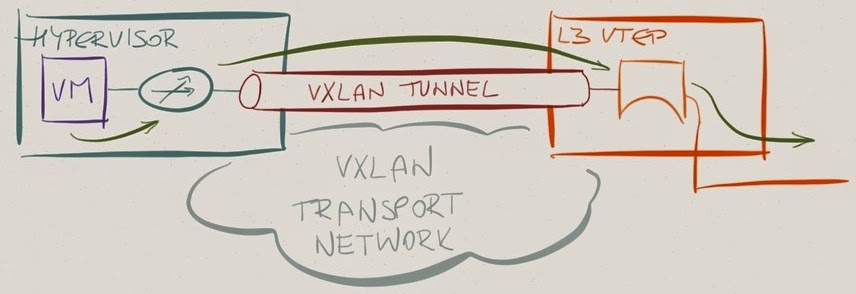
They used the existing distributed L3 forwarding functionality of VMware NSX to move the L3 lookup into the hypervisors. Based on the description in Bruce’s blog post, they use routing on VTEP in incoming direction and bridging on VTEP in the outgoing direction, effectively dancing around the hardware limitations.
Physical to virtual: Layer-3 lookup followed by VXLAN encapsulation
Virtual to physical: VXLAN decapsulation followed by layer-2 lookup
Does it matter?
The design design Bruce described removes the layer-3 boundary functionality from the L3 VTEP – all hypervisors are linked directly to the outside VLAN and must have all the L3 forwarding information that the L3 VTEP has.
It somehow reminds me of the old hack we had to use to connect MPLS/VPN networks to the Internet – just use a static route with a global next hop. Do I need to say more?
what I've wondered since VXLAN first showed up along with other "half-proprietary" options, why is this used over other vlan "tunnel" solutions (I think there's S-VLAN? and, of course, QinQ?).
I'll try to re-read the post a few more times, but I've really never understood why we needed one more "trunk" standard.
(I'm aware everything has flaws, i.e. i think there was bad support for qinq in Linux, not letting you set the ethertype because someone didn't *get* it.)
Still, is there any big advantage in the VXLAN way of things over normal "stacked VLAN" setups?