… updated on Thursday, May 13, 2021 15:42 UTC
BGP-Free Service Provider Core in Pictures
I got a follow-up question to the Should I use 6PE or native IPv6 post:
Am I remembering correctly that if you run IPv6 native throughout the network you need to enable BGP on all routers, even P routers? Why is that?
I wrote about BGP-free core before, but evidently wasn’t clear enough, so I’ll try to fix that error.
Imagine a small ISP with a customer-facing PE-router (A), two PE-routers providing upstream connectivity (B and D), a core router (C), and a route reflector (R). The ISP is running IPv4 and IPv6 natively (no MPLS).
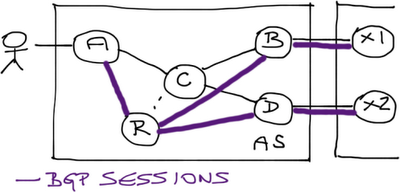
When an end-customer sends a packet toward an Internet destination (a Facebook server, for example), each router in the ISP network has to examine the packet, perform destination address lookup in its forwarding table (FIB), and forward the packet toward the next hop.
Assuming the ISP is not running BGP on the core router, the core router is not aware of any destination outside of its own AS, and thus drops the packet sent toward Facebook.
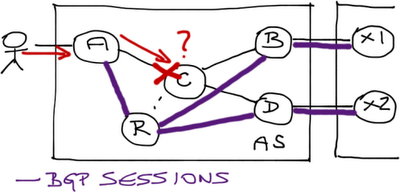
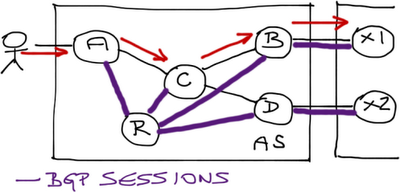
You can use default routing as a problem-solving kludge (B and D advertise default routes into the ISP’s network), or deploy BGP on the core router (C).
After a BGP session between C and R is configured, C receives all global BGP routes, and is able to forward packets toward external destinations:
There is another solution: if you deploy MPLS in the network, LDP automatically builds virtual circuits (Label Switched Paths – LSP) between any two routers. You could also use Segment Routing with MPLS to build the virtual circuits from the IGP topology information.
Ingress PE-routers use LSPs toward BGP next hops to send packets toward external destinations learned through BGP. The core router (C) thus receives labeled packet that it can switch toward the next hop without inspecting the destination IPv4 or IPv6 address, and thus there is no need to run BGP on C.
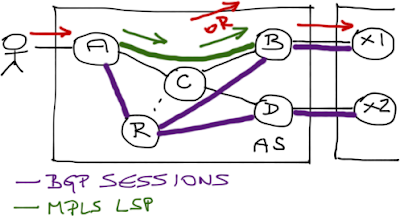
The last core router might send labeled or unlabeled IP packet (due to penultimate hop popping) to the egress PE-router. You can influence this behavior with mpls ldp explicit- null configuration command.
Why Should You Care?
There’s a simple reason to build a BGP-free core network: the core routers (or switches) don’t need to support the number of routes you’re carrying around in BGP (above 900.000 entries if you’re carrying the full Internet routing table), which means they could be cheaper, or faster, or both.
There’s also the minor routing convergence detail: with a BGP-free core, the convergence of the network depends just on the ingress and egress nodes. With BGP everywhere design, you might get new prefixes installed on the edge nodes while the core nodes are still furiously processing incoming BGP updates, resulting in black holes or microloops.
Also, unless you’re using a BGP-free core, a transit (core) switch shouldn’t be used until its BGP table has been fully loaded, resulting in yet another protocol kludge: IGP-BGP synchronization.
The tradeoffs (you know there are bound to be some, right)? You have to add yet another technology to your network (MPLS) and yet another protocol (LDP or SR-MPLS extensions for OSPF or IS-IS).
It is common inside any ISP core network to use at least one RR?
Can you share with us, why is that?
With two RR (for redundancy) you would need 2 x #PE +1 iBGP sessions
#PE being the number of PE in your network... So if you have 6 or more PE, RR decrease the number of iBGP sessions required...