Blog Posts in May 2011
EVB (802.1Qbg) – the S component
The Edge Virtual Bridging (EVB; 802.1Qbg) standard solves two important layer-2-based virtualization issues:
- Automatic provisioning of access switches based on hypervisor-signaled information (discussed in the EVB eases VLAN configuration pains article)
- Multiplexing of multiple logical 802.1Q links over a single physical link.
Logical link multiplexing might seem a solution in search of a problem until you discover that VMware-related design documents usually recommend using 6 to 10 NICs per server – an approach that either wastes switch ports or is hard to implement with blade servers’ mezzanine cards (due to limited number of backplane connections).
Building CsC-enabled MPLS backbone
Just got this question from one of my Service Provider friends: “If I am building a new MPLS backbone from scratch, should I design it with Carrier’s Carrier in mind?” Of course you should ... after all, the CsC functionality has almost no impact on the MPLS backbone (apart from introducing an extra label in the label stack).
… updated on Wednesday, July 6, 2022 14:40 UTC
For the Record: I Am Not Against OpenFlow ...
… as some of its supporters seem to believe every now and then (I do get severe allergic reaction when someone claims it will change the laws of physics or when I’m faced with technical inaccuracies peddled by an Instant Expert not to mention knee-jerking financial experts). Even more, assuming it can cross the adoption gap1, it could fundamentally change the business models of networking vendors (maybe not in the way you’d like them to be changed).
On the more technological front, I still don’t expect to see miracles. Most OpenFlow-related ideas I’ve heard about have been tried (and failed) before. I fail to see why things would be different just because we use a different protocol to program the forwarding tables.
I wrote about my OpenFlow views in an article that was published on SearchNetworking.com in 2011. That article is long gone, so I’m including in this blog post.
If you haven’t spent the last few weeks on a forgotten island with no satellite phone coverage, you’ve probably noticed the spiking levels of hype surrounding the newest internetworking technology OpenFlow. The networking industry is obviously in dire need of the next big thing. The last time I saw something similar to this was in the early 2000s when MPLS was supposed to solve every internetworking problem ever envisioned. In those days the levels of hype were so high that someone wrote an April 1st RFC describing the use of MPLS for electricity transport.
Like MPLS, OpenFlow won’t bring world peace, cure cancer or discover alien civilizations. It might, however, help change the internetworking environment in the same way Unix and Linux changed the operating system landscape by providing a standard way of configuring forwarding tables in a distributed switching architecture.
But that doesn’t account for the explosion of OpenFlow announcements at Interop. After all, OpenFlow was an unknown academic toy only a few months ago. In fact, the speed with which vendors were able to throw together a proof-of-concept code indicates one of the drawbacks of OpenFlow: it’s a simple low-level API (some people are comparing it to BIOS). The hard part of the exercise will be writing the controller software that everyone is already raving about. But that won’t be easy. Networking vendors have invested thousands of man-years into similar efforts. So those that expect revolutionary new controller applications appearing out of the blue sky probably also believe in tooth fairy and unicorn tears.
One of the most extreme analogies I’ve heard so far compared OpenFlow to a C compiler. Instead of using off-the-shelf applications, now we have the ability to develop our own. This might be true, but someone still has to develop these applications, test them and make sure they scale, which is one of the biggest hurdles OpenFlow has to cross. Meanwhile, vendors are already touting controller applications as the “magic” ingredient, but I wouldn’t expect miracles. As technical guru and professor Scott Shenker explained: “[OpenFlow] doesn’t let you do anything you couldn’t do on a network before.”
Moreover, even if OpenFlow were comparable to a C compiler, we haven’t seen an explosion of database packages or spreadsheet programs just because we have a C compiler. A few vendors own the majority of the market in each application segment, and the OpenFlow controller landscape might look very similar in a few years. There will likely be a few makers of commoditized hardware based on common merchant silicon and a few software vendors (probably including Cisco, Juniper and VMware) providing the vast majority of the controller nodes. And just in case you still believe OpenFlow will bring down prices and shrink the fat margins of some internetworking companies, take a brief look at Oracle’s financial reports.
Still Want to Know More about OpenFlow?
If you’re keen on figuring out how an obsolete protocol worked, you’ll find all the gory details in the OpenFlow Deep Dive webinar. If you’re more interested in real-life solutions, explore other SDN or network automation webinars.
Revision History
- 2022-07-06
- Added the OpenFlow article to the blog post
-
Hint: It did not. ↩︎
MPLS/VPN Transport Options
Jason sent me an interesting question a few days ago: “assuming a vSwitch *did* support MPLS/VPN PE router functionality, what type of protocol support would be needed on the access layer switches?”
While the MPLS/VPN support in hypervisor switches remains in the realm of science fiction, it’s worth knowing that there are at least five different transport options you can use between PE-routers. Here they are, from the most decoupled to the most tightly coupled ones:
Data Center Fabric Architectures update#1
Two months ago I wrote the Data Center Fabric Architectures post jokingly defining Borg and Big Brother architectures. In the meantime, a number of vendors have launched (or announced) their fabric products and the post badly needed an update.
I decided to move the updated text to my main web site (where it will be easier to edit), wrote an introductory section, removed a few tongue-in-cheek comments (after all, it’s time to get serious if Cisco’s Data Center blog links to your article) and added numerous links to in-depth articles and examples of individual architectures.
Scalability of Common Services MPLS/VPN topology
Nosx added a very valid point-of-view to the MPLS/VPN Common Services Design that uses a shared common service Route Target across numerous client VRFs:
This is an overly complex and unsupportable approach to shared services. Having to touch thousands of VRFs to create a shared services VPN is unacceptable. The correct approach is to touch only the "services" vrf, and import/export to each RT that you wish to insert the services into.
As always, the right answer is “it depends.” If you have few large customers, it makes way more sense to add their RTs to the common services VRF. If you have many small customers, adding RTs to the common services VRF does not scale.
Interesting links (2011-05-22)
My Inbox is (yet again) overflowing with great links.
IPv6
Tassos is describing the DHCPv6 prefix delegation nightmare in great details.
Cut Me Some SLAAC, Or Why You Need RA Guard by Tom the Networking Nerd describes the details of the recently-hyped SLAAC vulnerability. Conclusion: work with a vendor that knows a bit about fixing security problems.
IPv6 Neighbor Discovery exhaustion attack and IPv6 subnet sizes
A few days ago I got an interesting question: “What’s your opinion on the IPv6 NDP exhaustion attack and the recommendation to use /120 instead of /64?”
I guess we all heard the fundamentalist IPv6 mantra by now: “Every subnet gets a /64.” Being a good foot soldier, I included it in my Enterprise IPv6 webinar. Time to fix that slide and admit what we also knew for a long time: IPv6 is classless and we have yet to see the mysterious device that dies in flames when sniffing a prefix longer than a /64.
Router reload after 15 minutes of failed pings
Jeroen sent me an interesting challenge: he would like to reload the router when the 3G WAN interface gets stuck (I thought my Nokia phone is the only one exhibiting this problem, but obviously I was wrong). The reload-on-failed-ping EEM applet I’ve published would be a perfect solution, but it uses track delay and the maximum delay timeout is three minutes, while Jeroen would like to wait 15 minutes before reloading the router.
Scaling IaaS network infrastructure
I got totally fed up with the currently popular “flat-earth with long-distance bridging” architecture paradigm while developing the Data Center Interconnects webinar. It all started with the layer-2 hypervisor switches and lack of decent L3 network-side solutions; promoting non-scalable cloudy solutions doesn’t help either.
The network infrastructure would scale better if the hypervisors would work as MPLS/VPN PE-routers, but even MPLS would hit scalability limits when the number of servers grows into tens of thousands. The only truly scalable solution is IP-over-IP or MAC-over-IP implemented in the hypervisor switches.
I tried to organize all these thoughts in the “How to build a scalable IaaS cloud network infrastructure” article that was recently published by SearchTelecom ... and just a few days after the article was published, Brad Hedlund pointed me to Infrastructure as a Service Builder’s Guide document, which is saying almost the same thing (and coming to flawed conclusions because they had to promote OpenFlow and NEC).
Ignoring STP? Be careful, be very careful
A while ago I described what it takes to integrate TRILL backbone with the legacy equipment running Spanning Tree Protocol (STP). Unfortunately, Brocade decided to use a non-standard approach to BPDU handling when implementing their TRILL-like VCS fabric. VDX switches running in fabric mode can either drop incoming BPDU frames or transport them transparently across the fabric to other edge ports. Although VDX switches support STP, RSTP and MSTP (as well as RootGuard and BPDUGuard) when configured as standalone switches, the STP processing is disabled when you configure fabric mode; VCS fabric looks like a huge shared LAN segment to the end hosts and core switches.
2013-03-31: Network OS 4.0 and above supports Distributed Spanning Tree (DiST), for more details read this blog post.
FlexNetwork: the first impressions
HP’s FlexNetwork architecture launch at Interop has received mixed responses: from pretty positive from Tom the Networking Nerd to cautiously optimistic from Greg (Etherealmind) Ferro and more cautious analysis by Shamus McGillicuddy. For a grumpy skeptic’s take, read my FastPacket blog post.
NAT64: it’s all about the legacy content
Few days ago I enjoyed listening to the Teredo-bashing Packet Pushers Podcast during which Greg & the crew simply couldn’t avoid NAT64. Tom even wrote a follow-up post explaining why NAT is bad (we all agree with that) and why we shouldn’t use it in IPv6. Unfortunately he missed the elephant in the room: it’s all about the legacy content. IPv6-only residential users have to access IPv4-only content.
Published on , commented on July 6, 2022
OpenFlow Is Like IPv6
Frequent eruptions of OpenFlow-related hype (example: Being Open about Virtualization and Cloud Interoperability published after Brocade Technology Day Summit) call for a continuous myth-busting efforts. Let’s start with a widely-quoted (and immediately glossed-over) fact from Professor Scott Shenker, a founding board member of the Open Networking Foundation: “[OpenFlow] doesn’t let you do anything you couldn’t do on a network before.”
To understand his statement, remember that OpenFlow is nothing more than a standardized version of communication protocol between control and data plane. It does not define a radically new architecture, it does not solve distributed or virtualized networking challenges and it does not create new APIs that the applications could use. The only thing it provides is the exchange of TCAM (flow) data between a controller and one or more switches.
Cold fusion-like claims are nothing new in the IT industry. More than a decade ago another group of people tried to persuade us that changing the network layer address length from 32 bits to 128 bits and writing it in hex instead of decimal solves global routing and multihoming and improves QoS, security and mobility. After the reality distortion field collapsed, we were left with the same set of problems exacerbated by the purist approach of the original IPv6 architects.
Learn from the past bubble bursts. Whenever someone makes an extraordinary claim about OpenFlow, remember the “it can’t do anything you couldn’t do before” fact and ask yourself:
- Did we have a similar functionality in the past? If not, why not? Was there no need or were the vendors too lazy to implement it (don’t forget they usually follow the money)?
- Did it work? If not, why not?
- If it did - do we really need a new technology to replace a working solution?
- Did it get used? If not, why not? What were the roadblocks? Why would OpenFlow remove them?
Repeat this exercise regularly and you’ll probably discover the new emperor’s clothes aren’t nearly as shiny as some people would make you believe.
More to Explore
Want to hear the real-life SDN, OpenFlow or IPv6 story? Check out the ipSpace.net webinars available with standard subscription.
Revision History
- 2022-07-06
- Replaced a link to a Brocade blog post with an archived copy
Complexity Belongs to the Network Edge
Whenever I write about vCloud Director Networking Infrastructure (vCDNI), be it a rant or a more technical post, I get comments along the lines of “What are the network guys going to do once the infrastructure has been provisioned? With vCDNI there is no need to keep network admins full time.”
Once we have a scalable solution that will be able to stand on its own in a large data center, most smart network admins will be more than happy to get away from provisioning VLANs and focus on other problems. After all, most companies have other networking problems beyond data center switching.
Yearly subscription: too good to be true?
Occasionally I get e-mails from readers that can’t believe my description of yearly webinar subscription is correct. A few days ago I got this set of questions:
If I pay the $199.00 does that mean I have access to ALL of your webinars?
Absolutely, all sixteen of them (with new ones being added every two or three months). And don’t forget you also get unlimited access to all live webinars.
Edge Virtual Bridging (EVB; 802.1Qbg) eases VLAN configuration pains
Challenge: If you want to deploy virtual machines belonging to different security zones within the same physical host, you have to isolate them. VLANs are the most common approach. If you want to migrate a running VM from one host to another while preserving its user sessions, you usually have to rely on bridging. The set of VLANs needed on a trunk link between the hypervisor host and access switch is thus unpredictable (more information in my VMware Networking Deep Dive webinar)
Solution#1 (painful): Configure all possible VLANs on the trunk link. Stretched VLANs spanning the whole data center are an ideal ingredient of a major meltdown.
OSPF and Connected Networks: To Redistribute or Not?
A few days ago, I was discussing a data center design with a seasoned network architect. During the MPLS discussions, he made an offhand remark “There are still some switches running OSPF and using network 0.0.0.0 and redistribute connected.” My first thought was, “This can’t be good,” but I had no idea how bad it was until I ran a lab test.
The generic dilemma along the lines of “should I make connected interfaces part of my OSPF process (and make them passive) or should I redistribute them into OSPF” has no clear-cut answer (apart from the obvious “it depends”) ... and Google will quickly find you tons of lengthy discussions.
NHRP Convergence Issues in Multi-Hub DMVPN Networks
Summary for differently attentive: A hub router failure in multi-hub DMVPN networks can cause spoke-to-spoke traffic disruptions that last up to three minutes.
Almost every DMVPN design I’ve seen has multiple hubs for redundancy purposes. I’ve always preached the “one hub per DMVPN tunnel” mantra (see the diagram below) to those who were willing to listen citing “NHRP issues after hub failure” as one of the main reasons you should not have two or more hubs per DMVPN tunnel.
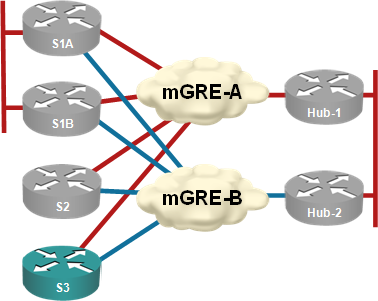
Each hub router controls an independent DMVPN tunnel
Interesting links (2011-05-01)
Working on the May Day feels like an oxymoron, but Sundays are about the only time I can clean up my overflowing Inbox.
The best post I’ve stumbled across recently is undoubtedly 38 life lessons I’ve learned in 38 years (thank you, @greg_meehan). I will try to remember the slow down one. Another great one: Managing IT people from Storagebod. Been there, seen that (and failed a few times).
And here’s the usual long list of links: