Distributed Firewalls: a Ticking Bomb
Are you ever asked to use a layer-2 Data Center Interconnect to implement distributed active-active firewalls, supposedly solving all the L3 issues and asymmetrical-traffic-flow-over-stateful-firewalls problems? Don’t be surprised; I was stupid enough (or maybe just blinded by the L2 glitter) in 2010 to draw the following diagram illustrating a sample use of VPLS services:
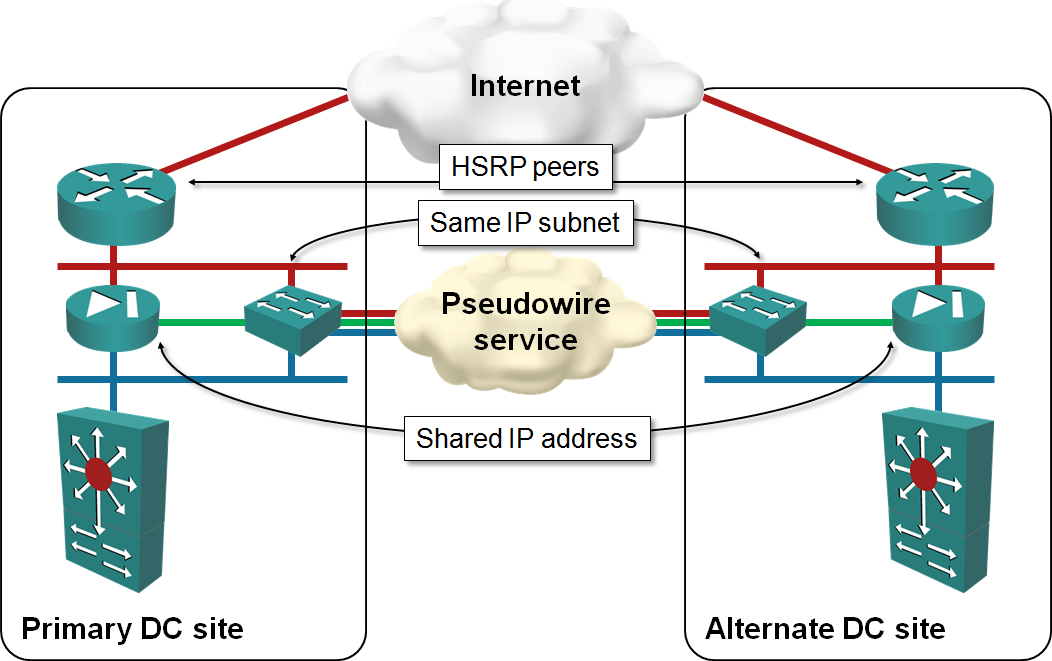
Distributed Firewalls Connected with Layer-2 Data Center Interconnect
The solution looks ideal: both WAN routers would advertise the same IP prefix to the outside world, attract the customer traffic and pass the traffic through the nearest firewall. The inside routers would take care of proper traffic distribution (inbound traffic might need to traverse the DCI link) and the return traffic would follow the shortest path toward the WAN (or Internet) cloud. The active-active firewalls would exchange flow information, solving the asymmetrical flow problems.
Now ask yourself: what happens if the DCI link fails? Some of the inbound traffic will arrive to the wrong edge router and get dropped, and the firewalls will go into split-brain mode. You’ll clearly experience problems in both data centers.
Usually we use pairs of devices (routers and firewalls in this particular example) in redundant configurations to increase the overall system availability. I am no expert in high availability calculations, but one of the hidden assumptions in designs where devices have to exchange state information (active-active firewalls, for example) is that the non-redundant component (the link between the devices) has to be as reliable as the devices themselves.
In a stretched subnet design the weakest link of the whole system is the data center interconnect; in most cases, stretched subnets would decrease the overall availability of the system.
A reliable layer-3 solution is not much easier to design. A while ago I was involved in a redesign of a global network. The customer had very knowledgeable networking team (it was a total pleasure working with them) and we tried really hard to find a redundant data center design that would allow them to advertise a single L3 prefix from both data centers. We even reached the point where we had a working design that would survive all sorts of failures, but it got too complex for the customer (and they were absolutely right to reject it and fall back to simpler options).
Unless you believe in the miracles of TCP-based anycasting, it seems the best option you have to implement distributed data centers is still the time-proven design: DNS-based load balancing between data centers in combination with data-center-specific+summary-as-a-backup prefix advertising into BGP.
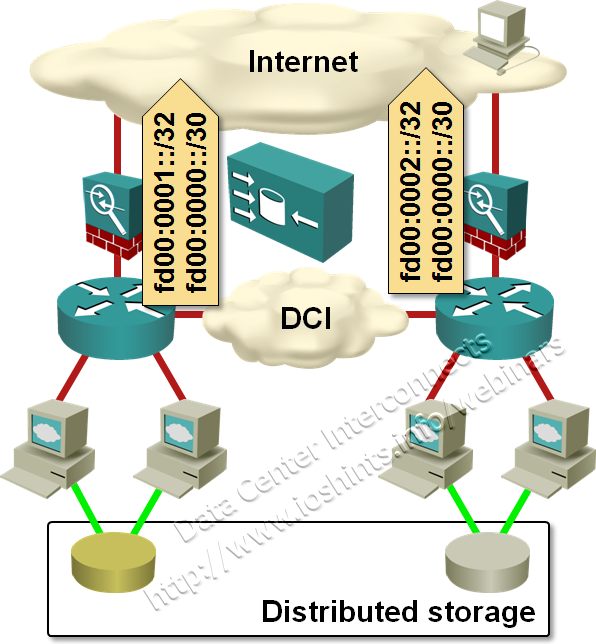
DNS-based multisite load balancing
More information
The Data Center Interconnects webinar describes numerous design and implementation aspects of L2 and L3 data center interconnects, but if you want to design a reliable data center multisite architecture, you REALLY SHOULD watch the Designing Active-Active and Disaster Recovery Data Centers webinar.
Just few words of appreciation for you... is there no saturday or no sunday for you?? Dont you take holidays??? When do you actually rest.... Wish I had the same dedication :(
Please correct me if I'm wrong.
So, beside your Google style solution, there is no other alternative?
Thanks
To reduce the risk of the datacenter interconnect, what I have done in multiple occasions within the past year was recommend a strategy where the client had a primary fast datacenter interconnect (usually dark fiber) between his 2 sites and as a backup to that use an L2TPv3 pseudowire over what is usually the client's existing L3 WAN. To avoid bridging each site's STP domain, I would use either REP (Cisco) or RRPP (HP) as a ring protocol responsible for the datacenter "ring", each link being terminated on either ME3400s with Cisco or an IRF pair of A-series HP switches.
With REP, you can only break the ring with STP in one location, and you have to use a stackwise pair in the other end with flex links to both of the local "ring devices". One of the Cisco Live sessions had some nice designs that suggested that, and it works very well.
With an IRF pair, those problems are taken care of as the device is a single entity, and thus only runs the ring protocol over the datacenter interconnect (the private fiber and the pseudowire).
The end result is that the risks of a dual active, split-brain scenario are very much reduced, and the ring protocol ensures fast convergence and STP domain isolation.
Alternatives depend on how reliable you want your design to be and how reliable you think your DCI link is (see also the comment from mnantel)
> Unless you believe in the miracles of TCP-based anycasting
What problems do you expect there? Rare session failures and reshakings... anything else?
If the difference in paths needed to reach them (as seen from outside) is big enough, anycasting should work like a dream ... but then you'd probably need a different DCI design anyway as your DCI link won't have infinite bandwidth.
ISPs must be different anyway for redundancy. Loadbalancing is a metter of playing with communities.
Secondly, I think you did a Hitchhiker's. The answer is 42 but what is the question?
To be be honest I don't see a problem that can't be solved in the architecture in your first diagram. If a split brain situation occurs then propagate the external IP prefix to only one WAN router. (based on the quorum reachability)
What am I overlooking here?
Best regards,
Also, assuming your right DC is the "chosen victim", how does it know the DCI link failed (and it should cut itself from the Internet) and not the left DC (in which case it should not do so)?
Thanks for conversation yesterday. Still I think anycast is much better solution for lots of designs today. Despite you say it could not work in some situations, I can find too few of them.
Even if a weird ISP gets equal path via different peers (very uncommon situation) it would be unbelivably weird of him to configure ebgp load sharing and further more balancing per packet not flow. True miracle are things working without human intervention, it's architect's/engineer's job to find these 1% issue cases and fix them.
People do not rely on anycast because they were tought in their childhood "TCP-anycast doesn't work, forget it!" Well, it does in fact and saves huge amunts of money and nerves.
Solution is not for vendors or integrators getting money for selling boxes and complicated designs. It's for internal staff willing to sleep well and get money for doing nothing.
Anycast is not for clusters. Who cares? They are back-ends. You can choose DCI with AToM and pay for it or create your own with L2TPv3+IPSec+Internet to syncronize them. Traffic will go through the same ISP equipment with the same delays/jitter/ploss. These L2 links must be kept as few as possible or totally avoided by configuring primary/secondary options on front-ends.
HTTP can work with anycast and it's the major application companies need today, even global monsters. I bet there are so few tcp applications lacking support of this technology that it should be brought back to humankind.
If there's anyone with a large company network to design I'd love to participate and implement anycast. Really. 'Cos it works! =)
What I would do is create an IP SLA on both WAN routers that monitor one (or more) device(s) that can only be reached via the DCI. (for example the core router in the other data center)
If the DCI fails then both WAN routers notice this. The question is then what should happen. It depends what services are available in both datacenters. Depending on that answer you have multiple options. You can designate one datacenter to take over all services by routing the ip-prefix to one location or you can split the ip-prefix in two (or more) and give each datacenter the part it can handle based on backend availability and expected load.
Am I missing something?
Best regards,
Also, I guess it depends on what you consider acceptable. To me, having user TCP connections fail (and seeing an error page) during normal operation even only once a day is unacceptable. We should be striving for 0 errors during normal operation. Errors should only happen during failures.
Some firewall vendors make active/active synchronization as easy as clicking a button and waiting a few minutes for the flow data to syncrhonize. If we know there will be an outage, we sync then we perform the maintenance, then we un-sync.
DCI fiber is confirmed to take different path.
The chosen firewall is able to support LAG and is active with the chosen dynamic routing protocol.
VRF introduce in DC.
With that in mind, there will be "lots" of saving for the same type of service level.
I am considering a design for a customer in which their DCI is 4 LAGed pairs of customer-owned dark fiber between two buildings which are 100ft from each other. (I know...not much for DR, but it's what they have to work with). We could tag separate VLANs across the DCI to interconnect the various pairs of devices (eg. one for HSRP/IBGP on the internet edge routers, another for state-sync on the firewalls).
Would you still frown on this architecture if the data centers were on opposite ends of the same building?
Opposite ends of the same data center?
Opposite ends of the same rack?
You can see the crux of my question is becoming "What precise factors make the DCI such a weak to be avoided as a cluster link.
Is it:
a - High Latency?
b - Probability of being mechanically disturbed by the ditch diggers?
c - Probability of being logically disturbed by malfunctioning service provider equipment?
d - Using the same link to connect multiple "clusters" (ie. tagging a VLAN for each cluster link instead of using a separate cable for each cluster link as would normally be the case if they were in the same data center) I DO hate the idea that losing this DCI would require every pair of devices to simultaneously recalculate mastership.
In my case criteria A and C are not a concern due to the short distance, and the private nature of the customer-owned fiber. However B and D are still factors to be weighed.
Thoughts?
You want to have a single failure domain? Go ahead, create a VLAN. You want to have resilience? Do a proper L3 design.
Regarding the line that reads, "A reliable layer-3 solution is not much easier to design." --- Is the use of the word, "not" a typo perhaps? I ask this just because I'm confused, since the first sentence seems incongruent with the remainder of that paragraph. The rest of the paragraph appears to convey that your client decided to fall back to an L3 DCI, in light of the complexity of the stretched L2 design you devised.
Please forgive my question, if this isn't a typo. I ask this only for the purpose of clarifying my understanding of your post.
Thanks,
Scott
http://blog.ipspace.net/2013/01/redundant-data-center-internet.html
Hope this helps,
Ivan
also, as of the date writing this post, would you still see the last design picture + bgp advertising a specific and summary route the best viable solution, and what would be the best DCI option that would go along.