Category: Workshop
You can't ignore IPv6 any longer (in seven steps)
We know the world will eventually run out of IPv4 addresses, but while at least some service providers got the message and already deployed IPv6, it seems like most enterprise IT departments still practice the denial strategy. It’s worrisome to read articles from Jeff Doyle describing the ignorance of his enterprise clients, so I’ll try (yet again) to explain why you should start IPv6 planning NOW.
Does Bridge Assurance Make UDLD Obsolete?
I got an interesting question from Andrew:
Would you say that bridge assurance makes UDLD unnecessary? It doesn't seem clear from any resource I've found so far (either on Cisco's docs or on Google)."
It’s important to remember that UDLD works on physical links whereas bridge assurance works on top of STP (which also implies it works above link aggregation/port channel mechanisms). UDLD can detect individual link failure (even when the link is part a LAG); bridge assurance can detect unaggregated link failures, total LAG failure, misconfigured remote port or a malfunctioning switch.
Framed-IPv6-Prefix used as delegated DHCPv6 prefix
Chris Pollock from io Networks was kind enough to share yet another method of implementing DHCPv6 prefix delegation on PPP interfaces in his comment to my DHCPv6-RADIUS integration: the Cisco way blog post: if you tell the router not to use the Framed-IPv6-Prefix passed from RADIUS in the list of prefixes advertised in RA messages with the no ipv6 nd prefix framed-ipv6-prefix interface configuration command, the router uses the prefix sent from the RADIUS server as delegated prefix.
This setup works reliably in IOS release 15.0M. 12.2SRE3 (running on a 7206) includes the framed-IPv6-prefix in RA advertisements and DHCPv6 IA_PD reply, totally confusing the CPE.
Delegated IPv6 prefixes – RADIUS configuration
In the Building Large IPv6 Service Provider Networks webinar I described how Cisco IOS uses two RADIUS requests to authenticate an IPv6 user (request#1) and get the delegated prefix (request#2). The second request is sent with a modified username (-dhcpv6 is appended to the original username) and an empty password (the fact that is conveniently glossed over in all Cisco documentation I found).
FreeRADIUS server is smart enough to bark at an empty password, to force the RADIUS server to accept a username with no password you have to use Auth-Type := Accept:
Site-A-dhcpv6 Auth-Type := Accept
cisco-avpair = "ipv6:prefix#1=fec0:1:2400:1100::/56"
DHCPv6-RADIUS integration: the Cisco way
Yesterday I described how the IPv6 architects split the functionality of IPCP into three different protocols (IPCPv6, RA and DHCPv6). While the split undoubtedly makes sense from the academic perspective, the service providers offering PPP-based services (including DSL and retrograde uses of PPP-over-FTTH) went berserk. They were already using RADIUS to authenticate PPP users ... and were not thrilled by the idea that they should deploy DHCPv6 servers just to make the protocol stack look nicer.
IPv6CP+DHCPv6+SLAAC+RA = IPCP
Last week I got an interesting tweet: “Hey @ioshints can you tell me what is the radius parameter to send ipv6 dns servers at pppoe negotiation?” It turned out that the writer wanted to propagate IPv6 DNS server address with IPv6CP, which doesn’t work. Contrary to IPCP, IPv6CP provides just the bare acknowledgement that the two nodes are willing to use IPv6. All other parameters have to be negotiated with DHCPv6 or ICMPv6 (RA/SLAAC).
The following table compares the capabilities of IPCP with those offered by a combination of DHCPv6, SLAAC and RA (IPv6CP is totally useless as a host parameter negotiation tool):
Traffic Trombone (what it is and how you get them)
Every so often I get a question “what exactly is a traffic trombone/tromboning”. Here’s my attempt at a semi-formal definition.
Traffic trombone is a term (probably invented by Greg Ferro) that colorfully describes inter-VLAN traffic flows in a network with stretched (usually overlapping) L2 domains.
In a traditional L2/L3 data center architecture with small L2 domains in the access layer and L3 forwarding across the core network, the inter-subnet traffic flows were close to optimal: a host would send a packet toward the first-hop (ingress) router (across a bridged L2 subnet), the ingress router would forward the packet across an optimal path toward the egress router, and the egress router would deliver the packet (yet again, across a bridged L2 subnet) to the destination host.
L2 DCI with MLAG over VPLS transport?
One of the answers I got to my “How would you use VPLS transport in L2 DCI” question was also “Can’t you just order two VPLS services, use them as P2P links and bundle the two links into a multi-chassis link aggregation group (MLAG)?” like this:
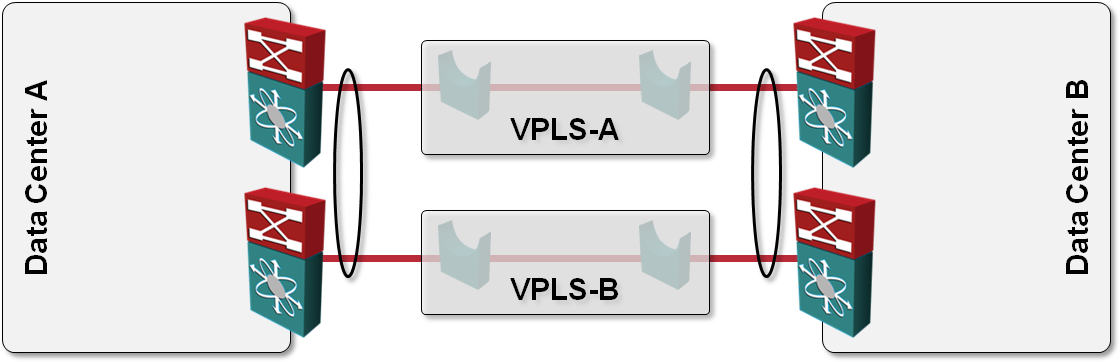
How would you use VPLS transport in L2 DCI?
One of the questions answered in my Data Center Interconnect webinar is: “what options do I have to build a layer-2 interconnect with transport technology X”, with X ∈ {dark-fiber, DWDM, SONET, pseudowire, VPLS, MPLS/VPN, IP}. VPLS is one of the tougher nuts to crack; it provides a switched LAN emulation, usually with no end-to-end spanning tree (which you wouldn’t want to have anyway).
Imagine the following simple scenario where we want to establish redundant connectivity between two data centers and the only transport technology we can get is VPLS (or some other Carrier Ethernet LAN service):
VEPA or vCloud Network Isolation?
If I could design my dream data center with total disregard to today’s limitations (and technologies from an alternate universe), it would have optimal connectivity between any two endpoints (real or virtual), no limits on VM mobility and on-demand L4-7 services insertion (be it firewalling, load balancing or something else) ... all of that implemented on truly scalable trombone-free networking infrastructure (in a dream world I don’t care whether it’s called routing or bridging).