Category: Workshop
Scaling IaaS network infrastructure
I got totally fed up with the currently popular “flat-earth with long-distance bridging” architecture paradigm while developing the Data Center Interconnects webinar. It all started with the layer-2 hypervisor switches and lack of decent L3 network-side solutions; promoting non-scalable cloudy solutions doesn’t help either.
The network infrastructure would scale better if the hypervisors would work as MPLS/VPN PE-routers, but even MPLS would hit scalability limits when the number of servers grows into tens of thousands. The only truly scalable solution is IP-over-IP or MAC-over-IP implemented in the hypervisor switches.
Ignoring STP? Be careful, be very careful
A while ago I described what it takes to integrate TRILL backbone with the legacy equipment running Spanning Tree Protocol (STP). Unfortunately, Brocade decided to use a non-standard approach to BPDU handling when implementing their TRILL-like VCS fabric. VDX switches running in fabric mode can either drop incoming BPDU frames or transport them transparently across the fabric to other edge ports. Although VDX switches support STP, RSTP and MSTP (as well as RootGuard and BPDUGuard) when configured as standalone switches, the STP processing is disabled when you configure fabric mode; VCS fabric looks like a huge shared LAN segment to the end hosts and core switches.
2013-03-31: Network OS 4.0 and above supports Distributed Spanning Tree (DiST), for more details read this blog post.
NAT64: it’s all about the legacy content
Few days ago I enjoyed listening to the Teredo-bashing Packet Pushers Podcast during which Greg & the crew simply couldn’t avoid NAT64. Tom even wrote a follow-up post explaining why NAT is bad (we all agree with that) and why we shouldn’t use it in IPv6. Unfortunately he missed the elephant in the room: it’s all about the legacy content. IPv6-only residential users have to access IPv4-only content.
NHRP Convergence Issues in Multi-Hub DMVPN Networks
Summary for differently attentive: A hub router failure in multi-hub DMVPN networks can cause spoke-to-spoke traffic disruptions that last up to three minutes.
Almost every DMVPN design I’ve seen has multiple hubs for redundancy purposes. I’ve always preached the “one hub per DMVPN tunnel” mantra (see the diagram below) to those who were willing to listen citing “NHRP issues after hub failure” as one of the main reasons you should not have two or more hubs per DMVPN tunnel.
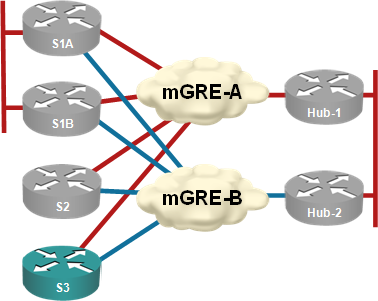
Each hub router controls an independent DMVPN tunnel
VPLS versus OTV for L2 Data Center Interconnect (DCI)
DJ Spry asked an interesting question in a comment to my MPLS/VPN in DCI designs post: “Why would one choose OTV over MPLS/VPN?” The answer is simple: it depends on what you need. MPLS/VPN provides path isolation between layer-3 domains (routed networks) across MPLS or IP infrastructure whereas OTV providers layer-2 transport (and VLAN-based path isolation) across IP infrastructure. However, it does make sense to compare OTV with VPLS (which was DJ Spry’s next question). Apart from the obvious platform dependence (OTV runs on Nexus 7000, VPLS runs on Catalyst 6500/Cisco 7600 and a few other routers) which might disappear once ASR1K gets the rumored OTV support, there’s a huge gap in functionality and complexity between the two layer-2 transport technologies.
(v)Cloud Architects, ever heard of MPLS?
Duncan Epping, the author of fantastic Yellow Bricks virtualization blog tweeted a very valid question following my vCDNI scalability (or lack thereof) post: “What you feel would be suitable alternative to vCD-NI as clearly VLANs will not scale well?”
Let’s start with the very basics: modern data center switches support anywhere between 1K and 4K (the theoretical limit based on 802.1q framing) VLANs. If you need more than 1K VLANs, you’ve either totally messed up your network design or you’re a service provider offering multi-tenant services (recently relabeled by your marketing department as IaaS cloud). Service Providers had to cope with multi-tenant networks for decades ... only they haven’t realized those were multi-tenant networks and called them VPNs. Maybe, just maybe, there’s a technology out there that’s been field-proven, known to scale, and works over switched Ethernet.
vCloud Director Network Isolation (vCDNI) scalability
When VMware launched its vCloud Director Networking Infrastructure, Greg Ferro (of the Packet Pushers Podcast fame) and myself were very skeptical about its scaling capabilities, more so as it uses MAC-in-MAC encapsulation and bridging was never known for its scaling properties. However, Greg’s VMware contacts claimed that vCDNI scales to thousands of physical servers and Greg wanted to do a podcast about it.
As always, we prepared a few questions in advance, including “How are broadcasts, multicasts and unknown unicasts handled in vCDNI-based private networks?” and “what happens when a single VM goes crazy?” For one reason or another, the podcast never happened. After analyzing Wireshark traces of vCDNI traffic, I probably know why that’s the case.
Brocade VCS fabric has almost-perfect load balancing
Short summary for differently-attentive: proprietary load balancing Brocade uses over ISL trunks in VCS fabric is almost perfect (and way better for high-throughput sessions than what you get with other link aggregation methods).
During the Data Center Fabrics Packet Pushers Podcast we’ve been discussing load balancing across aggregated inter-switch links and Brocade’s claims that its “chip-based balancing” performs better than standard link aggregation group (LAG) load balancing. Ever skeptical, I said all LAG load balancing is chip-based (every vendor does high-speed switching in hardware). I also added that I would be mightily impressed if they’d actually solved intra-flow packet scheduling.
NAT-PT is dead! Long live NAT-64!
I’m getting questions like this one all the time: “Where are we with NAT-PT? It was implemented in IOS quite a few years ago but it has never made it into ASA code.”
Bad news first: NAT-PT is dead. Repeat after me: NAT-PT is dead. Got it? OK.
More bad news: NAT-PT in Cisco IOS was seriously broken after they pulled fast switching code out of IOS. Whatever is left in Cisco IOS might be good enough for a proof-of-concept or early deployment trials, but not for a production-grade solution.
VRF-aware services in Cisco IOS
"Which Cisco IOS services work in a VRF?" is the question I get in almost any VRF-related discussion, so I made sure it’s covered very early in my Enterprise MPLS/VPN deployment webinar. This is the explanation I usually give in the webinar: