Category: Vxlan
Lab: Anycast Gateways on VXLAN Segments
Most vendors “discovered” anycast gateways when they tried implementing routing between MAC-VRFs in an EVPN environment and hit all the usual tripwires (more about that later). A few exceptions (like Arista) supported them on VLAN segments for over a decade, and it was a no-brainer to extend that support to VXLAN segments.
Want to try out how that works? The Anycast Gateways on VXLAN Segments lab exercise is just what you need.

You can run the lab on your own netlab-enabled infrastructure (more details), but also within a free GitHub Codespace or even on your Apple-silicon Mac (installation, using Arista cEOS container, using VXLAN/EVPN labs).
Lab: More Complex EVPN/VXLAN Bridging Scenario
In the first EVPN/VXLAN lab, we added the EVPN control plane to bridging over VXLAN. Now, let’s try out a more complex scenario: several EVPN MAC-VRFs mapped to different VLAN segments on individual PE-devices.

You can run the lab on your own netlab-enabled infrastructure (more details), but also within a free GitHub Codespace or even on your Apple-silicon Mac (installation, using Arista cEOS container, using VXLAN/EVPN labs).
Lab: Routing Between VXLAN Segments
In the previous EVPN/VXLAN lab exercises, we covered the basics of Ethernet bridging over VXLAN and the use of the EVPN control plane to build layer-2 segments.
It’s time to move up the protocol stack. Let’s see how you can route between VXLAN segments, this time using unique unicast IP addresses on the layer-3 switches.

You can run the lab on your own netlab-enabled infrastructure (more details), but also within a free GitHub Codespace or even on your Apple-silicon Mac (installation, using Arista cEOS container, using VXLAN/EVPN labs).
Lab: VXLAN Bridging with EVPN Control Plane
In the previous VXLAN labs, we covered the basics of Ethernet bridging over VXLAN and a more complex scenario with multiple VLANs.
Now let’s add the EVPN control plane into the mix. The data plane (VLANs mapped into VXLAN-over-IPv4) will remain unchanged, but we’ll use EVPN (a BGP address family) to build the ingress replication lists and MAC-to-VTEP mappings.
Lab: More Complex VXLAN Deployment Scenario
In the first VXLAN lab, we covered the very basics. Now it’s time for a few essential concepts (before introducing the EVPN control plane or integrated routing and bridging):
- Each VXLAN segment could have a different set of VTEPs (used to build the BUM flooding list)
- While the VXLAN Network Identifier (VNI) must be unique across the participating VTEPs, you could map different VLAN IDs into a single VNI (allowing you to merge two VLAN segments over VXLAN)
- Neither VXLAN VNI nor VLAN ID has to be globally unique (but it helps to make them unique to remain sane)
New Project: Open-Source VXLAN/EVPN Labs
After launching the BGP labs in 2023 and IS-IS labs in 2024, it was time to start another project that was quietly sitting on the back burner for ages: open-source (and free) VXLAN/EVPN labs.
The first lab exercise is already online and expects you to extend a single VLAN segment across an IP underlay network using VXLAN encapsulation with static ingress replication.
EVPN Designs: Multi-Pod with IP-Only WAN Routers
In the multi-pod EVPN design, I described a simple way to merge two EVPN fabrics into a single end-to-end fabric. Here are a few highlights of that design:
- Each fabric is running OSPF and IBGP, with core (spine) devices being route reflectors
- There’s an EBGP session between the WAN edge routers (sometimes called border leaf switches)
- Every BGP session carries IPv4 (underlay) and EVPN (overlay) routes.
In that design, the WAN edge routers have to support EVPN (at least in the control plane) and carry all EVPN routes for both fabrics. Today, we’ll change the design to use simpler WAN edge routers that support only IP forwarding.
EVPN Designs: Multi-Pod Fabrics
In the EVPN Designs: Layer-3 Inter-AS Option A, I described the simplest multi-site design in which the WAN edge routers exchange IP routes in individual VRFs, resulting in two isolated layer-2 fabrics connected with a layer-3 link.
Today, let’s explore a design that will excite the True Believers in end-to-end layer-2 networks: two EVPN fabrics connected with an EBGP session to form a unified, larger EVPN fabric. We’ll use the same “physical” topology as the previous example; the only modification is that the WA-WB link is now part of the underlay IP network.
… updated on Sunday, September 28, 2025 11:23 +0200
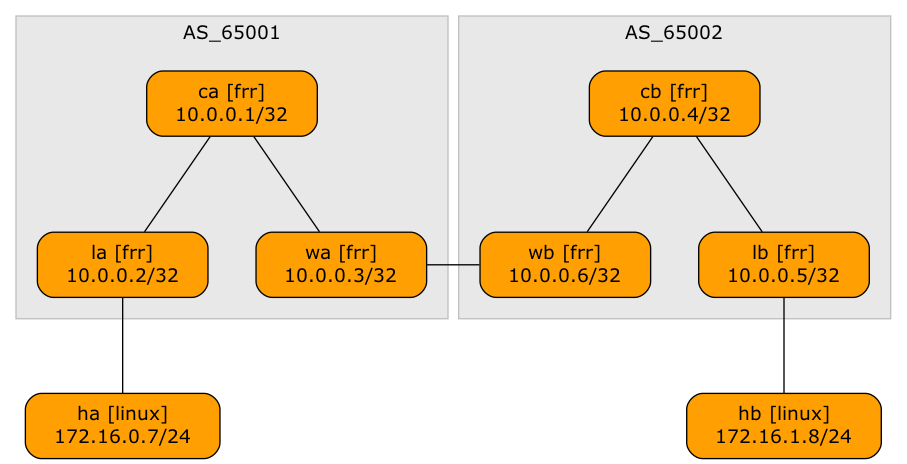
EVPN Designs: Layer-3 Inter-AS Option A
A netlab user wanted to explore a multi-site design where every site runs an independent EVPN fabric, and the inter-site link is either a layer-2 or a layer-3 interconnect (DCI). Let’s start with the easiest scenario: a layer-3 DCI with a separate (virtual) link for every tenant (in the MPLS/VPN world, we’d call that Inter-AS Option A)
Lab topology
EVPN Designs: EVPN IBGP over IPv4 EBGP
We’ll conclude the EVPN designs saga with the “most creative” design promoted by some networking vendors: running an IBGP session (carrying EVPN address family) between loopbacks advertised with EBGP IPv4 address family.

Oversimplified IBGP-over-EBGP design
There’s just a tiny gotcha in the above Works Best in PowerPoint diagram. IBGP assumes the BGP neighbors are in the same autonomous system while EBGP assumes they are in different autonomous systems. The usual way out of that OMG, I painted myself into a corner situation is to use BGP local AS functionality on the underlay EBGP session: