Category: switching
Data Center Bridging (DCB) Congestion Notification (802.1Qau)
The last (and the least popular) Data Center Bridging (DCB) standard tries to solve the problem of congestion in large bridged domains (PFC enables lossless transport and ETS standardizes DWRR queuing). To illustrate the need for congestion control, consider a simple example shown in the following diagram:
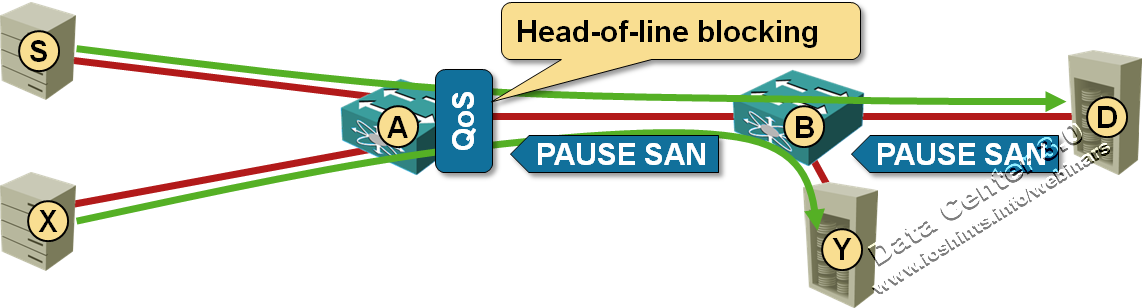
It came to my attention that a vendor might be using this blog post to justify the need for QCN in FCoE environments. Should that be the case, please make sure you also read about the difference between dense and sparse FCoE, the (lack of) need for QCN in FCoE and whether it makes sense to run FCoE over TRILL. Finally, consider how you’ll troubleshoot FCoE environments.
VPLS is a technology, not just a service provider offering
The Internet Exchange and Peering Points Packet Pushers Podcast is as good as the rest of them (listen to it first and then continue reading), but also strangely relevant to the data center engineers. When you look beyond the peering policies, route servers and BGP tidbits, an internet exchange is a high-performance large-scale layer-2 network that some data center switching vendors are dreaming about ... the only difference being that the internet exchanges have to perform extremely well using existing products and technologies, not the shortest-path-bridging futures promised by the vendors.
… updated on Sunday, May 8, 2022 09:21 UTC
Multi-Chassis Link Aggregation (MLAG) Basics
If you ask any networking engineer building layer-2 fabrics the traditional way about his worst pains, I’m positive Spanning Tree Protocol (STP) will be very high on the shortlist. In a well-designed fully redundant hierarchical bridged network where every device connects to at least two devices higher in the hierarchy, you lose half the bandwidth to STP loop prevention whims.
Introduction to 802.1Qaz (Enhanced Transmission Selection – ETS)
Enhanced Transmission Selection (ETS) is the second part of the Data Center Bridging puzzle (I’ve already described Priority Flow Control). It specifies two different technologies:
- Queuing mechanisms in bridges
- Data Center Bridging eXchange protocol: a Control/Negotiation protocol that allows bridges and hosts to negotiate QoS parameters in a bridged network.
Although some bridges from some vendors supported numerous QoS mechanisms in the past, 802.1Qaz is the first attempt to standardize a richer set of QoS behaviors than the strict priority queuing defined in 802.1p.
Virtual aggregation: a quick fix for FIB/TCAM overflow
During the Big Hot and Heavy Switches podcast, Dan Hughes complained that the Nexus 7000 switch cannot take the full BGP table. The reason is simple: it’s TCAM (FIB) has only 56.000 entries and the BGP table has almost 350.000 routes.
Nexus 7000 is a Data Center switch, so the TCAM size is not really a limitation (it would usually have a default route toward the WAN core), but the same problem is experienced by Service Providers all over the world – the TCAM/FIB size of their high-speed routers is limited.
… updated on Saturday, December 26, 2020 13:51 UTC
RIBs and FIBs (aka IP Routing Table and CEF Table)
Every now and then, I’m asked about the difference between Routing Information Base (RIB), also known as IP Routing Table and Forwarding Information Base (FIB), also known as CEF table (on Cisco’s devices) or IP forwarding table.
Let’s start with an overview picture (which does tell you more than the next thousand words I’ll write):
Port or Fabric Extenders?
Among other topics discussed during the Big Hot and Heavy Switches (Part 1) podcast (if you haven’t listened to it yet, it’s high time you do), we’ve mentioned port extenders. As our virtual whiteboard is not always clearly visible during the podcast (although we scribble heavily on it), here’s the big-picture architecture:
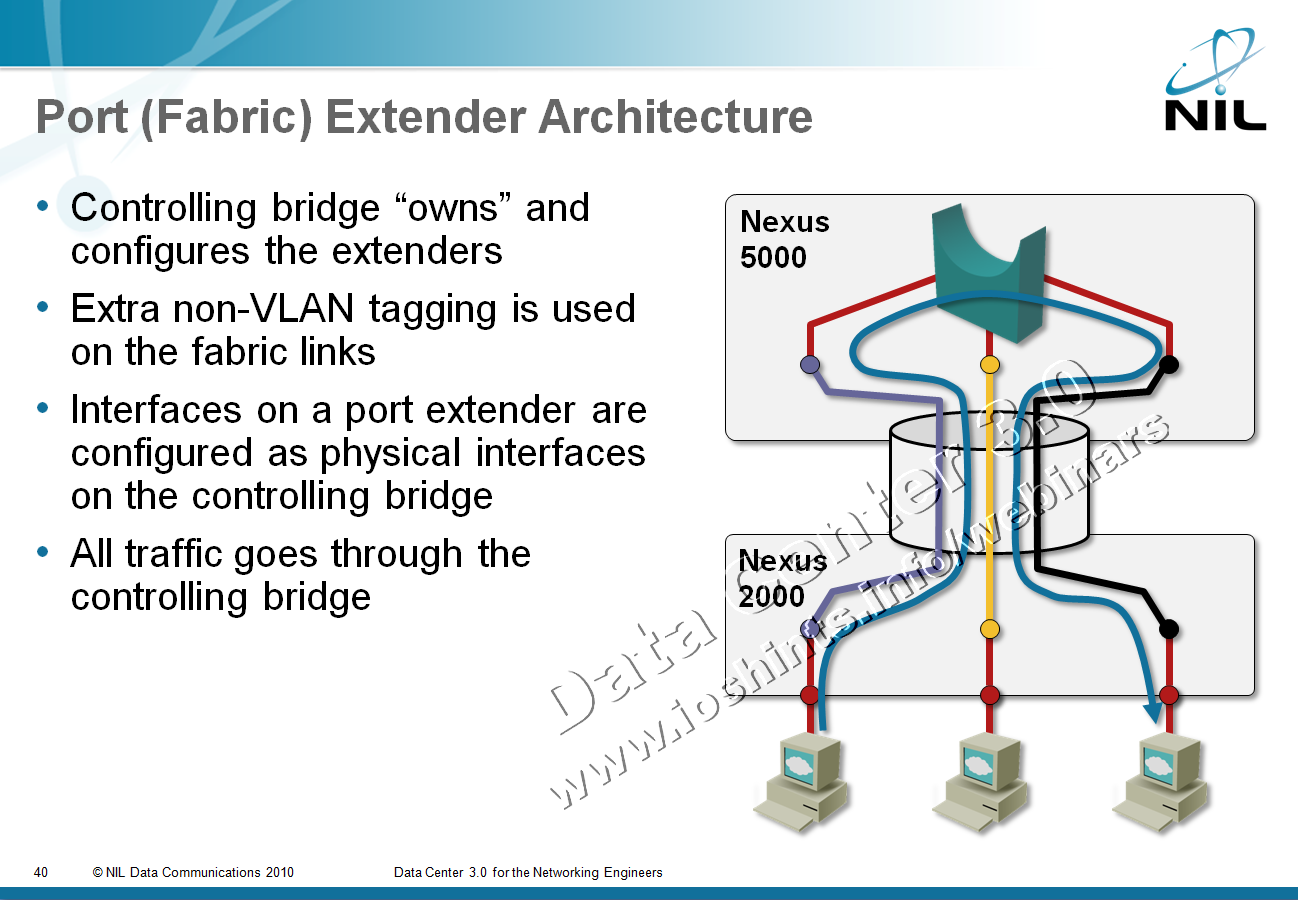
After the podcast I wanted to dig into a few minor technical details and stumbled into a veritable confusopoly.
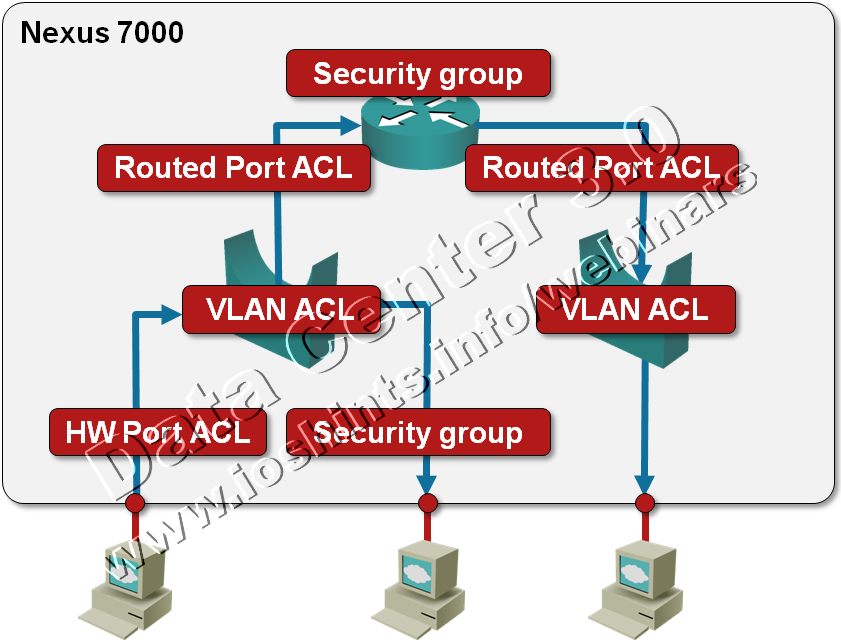
Packet Filters on a Nexus 7000
We’re always quick to criticize ... and usually quiet when we should praise. I’d like to fix one of my omissions: a few days ago I was trying to figure out whether Nexus 7000 supports IPv6 access lists (one of the presentations I was looking at while researching the details for my upcoming Data Center webinar implied there might be a problem) and was pleasantly surprised by the breadth of packet filters offered on this platform. Let’s start with a diagram.
Server Virtualization Has Totally Changed the Data Center Networking
There’s an extremely good reason Brad Hedlund mentioned server virtualization in his career advice: it has fundamentally changed the Data Center networking.
Years ago, we’ve treated servers as oversized IP hosts. From the networking perspective, they were no different from other IP hosts. Some of them had weird clustering requirements, some of them had multiple uplinks that had to be managed somehow, but those were just minor details. Server virtualization is a completely different beast.
Bridges: a Kludge that Shouldn't Exist
During the last weeks I tried hard to sort out my thoughts on routing and bridging; specifically, what’s the difference between them and why you should use routing and not bridging in any large-scale network (regardless of whether it happens to be cramped into a single building called Data Center).
My vague understanding of layer 2 (Data Link layer) of the OSI model was simple: it was supposed to provide frame transport between neighbors (a neighbor is someone who is on the same physical medium as you are); layer 3 (Network layer) was supposed to provide forwarding between distant end nodes. Somehow the bridges did not fit this nice picture.
As I was struggling with this ethereally geeky version of a much older angels-on-a-pin problem, Greg Ferro of EtherealMind.com (what a coincidence, isn’t it) shared a link to a GoogleTalk given by Radia Perlman, the author of the Spanning Tree Protocol and co-author of TRILL. And guess what – in her opening minutes she said “Bridges don’t make sense. If you do packet forwarding, you should do it on layer 3”. That’s so good to hear; I’m not crazy after all.
Where would you need bridging in the Data Center
In the recent months, there’s been a lot of buzz about next-generation Data Center bridging, including the Earth Is Flat rediscovery from Brocade (I thought that was settled in middle ages) and a TRILL article in SearchNetworking (which quoted both Greg and me as being on the opposite sides of the TRILL debate).
The more I think about this problem, the more I’m wondering whether we really need large-scale bridging in data centers (it looks like Google can live quite happily without it). We definitely need some bridging, but generic large-scale inter-site monstrosity? I doubt.
Please try to help me: forget all the “this is how we do it” presumptions, figure out a scenario where you absolutely need bridging and describe it in the comments.
Interconnecting two core switches
Ethan Banks has a great article @ PACKETattack: in Assembly Required – Interconnecting 2 Ethernet Chassis Switches he describes various options you have when you want to connect your redundant core switches. Using more than one physical link is the obvious choice; most people are careful enough to use at least two linecards, but the true magic begins when you start considering the bandwidth allocation to individual linecards and port groups within linecards.
The thrills of TRILL
Tired of losing half of your bandwidth to spanning tree? TRILL will solve all your problems, bring the world peace and make better coffee than Starbucks (hint: the second claim is fake and the third one is not so hard to achieve).
Undoubtedly TRILL is an interesting technology that can alleviate the spanning tree limitations. Unfortunately I’ve seen a very similar technology being heavily misused in the past (resulting in some fantastic failures) and remain skeptical about the deployment of TRILL. My worst case scenario: TRILL will make it too simple to deploy plug-and-pray bridged (vendors will call them “switched”) networks with no underlying design that will grow beyond control and implode.
Greg Ferro has kindly invited me to be a guest author on his excellent blog Etherealmind.com and I simply had to spill my thoughts on TRILL in the TRILL: It’s a DéJà-Vu All Over Again article after they’ve been discussing it during one of the Packet Pushers podcast.
Understanding MSTP
Ten steps of small LAN design
Every so often someone tries to apply the “let all be friends and love each other” mentality to LAN networks and designs a pure layer-2 switched LAN (because it’s simpler). Jay contributed a ten-step “what happens next” description in his comment to my “Lies, damned lies and product marketing” post. The steps are so hilarious I simply had to repost them:
- Build everything at layer 2 because "it's simpler".
- Scale a little.
- Things start breaking mysteriously. Run around in circles. Learn about packet sniffers and STP.
- Learn about layer 3 features in switches you already own. Start routing.
- Scale more.
- Things start breaking mysteriously. Learn about TCAMs. Start wishing for NetFlow.
- Redesign. Buy stuff.
- Scale more.
- VMWare jockeys start asking about bridging across the WAN.
- Enroll in hair loss program.