Category: Ip Routing
… updated on Friday, November 26, 2021 15:35 UTC
Multi-Threaded Routing Daemons
When I wrote the Why Does Internet Keep Breaking? blog post a few weeks ago, I claimed that FRR still uses single-threaded routing daemons (after a too-cursory read of their documentation).
Donald Sharp and Quentin Young politely told me I was an idiot I should get my facts straight, I removed the offending part of the blog post, promised to write another one going into the details, and Quentin improved the documentation in the meantime, so here we are…
Non-Stop Routing (NSR) 101
After Non-Stop Forwarding, Stateful Switchover and Graceful Restart, it’s time for the pinnacle of high-availability switching: Non-Stop Routing (NSR)1.
The PowerPoint-level description of this idea sounds fantastic:
- A device runs two active copies of its control plane.
- There is no cold/warm start of the backup control plane. The failover is almost instantaneous.
- The state of all control plane protocols is continuously synchronized between the two control plane instances. If one of them fails, the other one continues running.
- A failure of a control plane instance is thus invisible from the outside.
If this sounds an awful lot like VMware Fault Tolerance, you’re not too far off the mark.
Interactions Between BFD and Graceful Restart
We have school holidays this week, so I’m reposting wonderful comments that would otherwise be lost somewhere in the page margins. Today: Dmitry Perets on the interactions between BFD and GR.
Well, assuming that the C-bit is set honestly (will be funny if not) and assuming that the Helper is using this bit correctly (and I think it’s pretty well defined what “correctly” means - see section 4.3 in RFC 5882), the answer is pretty clear.
Graceful Restart and BFD
The whole High Availability Switching series started with a question along the lines of “does it make sense to run BFD together with Graceful Restart”. After Non-Stop Forwarding 101, Graceful Restart 101, and Graceful Restart and Convergence Speed we finally have enough information to answer that question.
TL&DR: Most probably not.
A more nuanced answer depends (as always) on a gazillion implementation details.
Graceful Restart and Routing Protocol Convergence
I’m always amazed when I encounter networking engineers who want to have a fast-converging network using Non-Stop Forwarding (which implies Graceful Restart). It’s even worse than asking for smooth-running heptagonal wheels.
As we discussed in the Fast Failover series, any decent router uses a variety of mechanisms to detect adjacent device failure:
- Physical link failure;
- Routing protocol timeouts;
- Next-hop liveliness checks (BFD, CFM…)
Graceful Restart and Other Control Plane Protocols
In the Graceful Restart 101 blog post, I promised to discuss the ugly parts of this concept in a follow-up post. It turns out we’ll need more than one; today, we’ll focus on other control plane protocols in an access network scenario.
Imagine an access router with multiple uplinks serving a bunch of non-redundantly-connected customers:
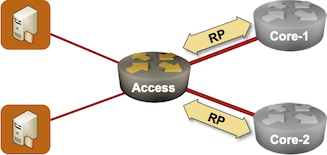
Non-redundant access network
Video: Public Cloud Networking Is Different
Even though you need plenty of traditional networking constructs to deploy a complex application stack in a public cloud (packet filters, firewalls, load balancers, VPN, BGP…), once you start digging deep into the bowels of public cloud virtual networking, you’ll find out it’s significantly different from the traditional Ethernet+IP implementations common in enterprise data centers.
For an overview of the differences watch the Public Cloud Networking Is Different video (part of Introduction to Cloud Computing webinar), for more details start with AWS Networking 101 and Azure Networking 101 blog posts, and continue with corresponding cloud networking webinars.
Graceful Restart (GR) 101
In the Non-Stop Forwarding (NSF) article, I mentioned that the routers adjacent to the device using NSF have to play along to make the idea work. That capability is called Graceful Restart. Today we’ll explore its intricate details, be diplomatic, and leave the shortcomings and tradeoffs for another blog post.
The Problem
Imagine an access (provider edge) router providing connectivity services to its clients and running a routing protocol with one or more upstream devices.
Unexpected Interactions Between OSPF and BGP
It started with an interesting question tweeted by @pilgrimdave81
I’ve seen on Cisco NX-OS that it’s preferring a (ospf->bgp) locally redistributed route over a learned EBGP route, until/unless you clear the route, then it correctly prefers the learned BGP one. Seems to be just ooo but don’t remember this being an issue?
Ignoring the “why would you get the same route over OSPF and EBGP, and why would you redistribute an alternate copy of a route you’re getting over EBGP into BGP” aspect, Peter Palúch wrote a detailed explanation of what’s going on and allowed me to copy into a blog post to make it more permanent:
Video: Comparing Routing and Bridging
After covering the basics of transparent Ethernet bridging and IP routing, we’re finally ready to compare the two. Enjoy the ride ;)