L2TP default routing: solutions
There are three tools that can (according to a CCIE friend of mine) solve any networking-related problems: GRE tunnels, PBR and VRFs. The solutions to the L2TP default routing challenge nicely prove this hypothesis; most of them use at least one of those tools.
Policy-based routing on virtual template interface. Use the default route toward the Internet and configure PBR with set default next-hop on the virtual template interface. The PBR is inherited by all virtual access interfaces, ensuring that the traffic from remote sites always passes the network core (and the firewall, if needed).
Small Steps to Large Complexity
Imagine you have a large retail network: your remote offices use ISDN to dial into the central site and upload/download whatever periodic reports they have. Having a core router connected to an ISDN PRI interface is the perfect solution:
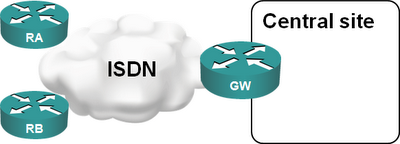
A few years later, ISDN is becoming too slow for your increased traffic needs and you want to replace it with DSL or VPN-over-Internet solution. Your Service Provider offers you PPPoE forwarding with L2TP. This is a perfect solution as it allows you to minimize the changes:
New CCIE track: IOS Numbering
In a comment to my “Did you notice 15.1T is released?” post kcuorbax shared exciting news about the new CCIE track launched yesterday:
CCIE Numbering experts will have the outstanding ability to find if a bug fixed in release A is fixed in release B. They will understand why new features are inadvertently introduced in mainline trains and why developers forget to commit fixes in the branches where the bugs were discovered. They will master the double numbering of IOS-XE and the sudden change from 12.2XN to 15.0S.
Anyone brave enough to try to take this exam?
RFC 5789: PATCH Method for HTTP
This looks like another April 1st RFC (but it's apparently not):
Several applications extending the Hypertext Transfer Protocol (HTTP) require a feature to do partial resource modification. The existing HTTP PUT method only allows a complete replacement of a document. This proposal adds a new HTTP method, PATCH, to modify an existing HTTP resource.
Did you notice 15.1T is released?
Unveiling of the Cisco IOS release 15.1(1)T was the extreme opposite of the CRS-3 and Catalyst 3750-X splashes; the next release of one of the foundations of Cisco’s core business deserved a modest two-paragraph mention in the What's New in Cisco Product Documentation page.
If you’re a voice guru, you’ll probably enjoy the list of 20+ voice-related new features, including the all-important Enhanced Music on Hold. For the rest of us, here’s what I found particularly interesting:
First-ever end-to-end optical traffic grooming with CRS-3
One of the exciting new features of the recently launched CRS-3 router enables Service Providers to implement first-ever all-optical end-to-end traffic grooming. One of the new linecards (unfortunately not compatible with CRS-1 due to increased hardware complexity) supports the SFSS protocol (defined in RFC 4824).
Using a high-quality video link and all-optical spatial separators you can easily transport more than one SFSS instance on the same wavelength, allowing you to implement a true sub-lambda traffic grooming in the optical domain. There’s just one gotcha: due to the encoding requirements of SFSS, you cannot carry it in the dense channel spacing of DWDM; you have to use CWDM or even wider optical bands depending on the receiver’s capabilities.
… updated on Friday, December 4, 2020 14:02 UTC
MPLS TE Autoroute Fundamentals
An MPLS Traffic Engineering (MPLS TE) tunnel is a unidirectional Label Switched Path (LSP) established between the tunnel head-end Label Switch Router (LSR) and tail-end LSR. Once the tunnel is established and operational, it’s ready to forward IPv4 data traffic. However, no traffic will enter the tunnel unless the IPv4 routing tables and CEF tables are modified. You can push the traffic into an MPLS TE tunnel with a static route or with policy-based routing (PBR) or modify the behavior of the link-state algorithm used to implement MPLS TE in your network.
The autoroute functionality configured with the tunnel mpls autoroute announce interface configuration command automatically inserts the MPLS TE tunnel in the SPF tree and ensures the tunnel is used to transport all the traffic from the head-end LSR to all destinations behind the tail-end LSR.
Upgrade, Reboot, Repeat

Disclaimer: No, this post has absolutely nothing to do with any software I regularly blog about.
The FTP Butterfly Effect
Anyone dealing with FTP and firewalls has to ask himself “what were those guys smokingthinking?” As we all know, FTP is seriously broken interestingly-designed:
- Command and data streams use separate sessions.
- Layer-3 addresses and layer-4 port numbers are carried in layer-7 messages.
- FTP server opens a reverse session to a dynamic port assigned by the FTP client.
Once upon a time, there was a very good reason for this weird behavior. As Marcus Ranum explained in his Internet nails talk @ TEDx (the title is based on the For Want of a Nail rhyme), the original FTP program had to use two sessions because the sessions in the original (pre-TCP) Arpanet network were unidirectional. When TCP was introduced and two sessions were no longer needed (or, at least, they could be opened in the same direction), the programmer responsible for the FTP code was simply too lazy to fix it.
Innovative coincidences
In another close-to-perfect series of events, Scott Berkun has just published his latest speech on innovation delivered at The Economists’ Ideas Economy event. I loved this part (you might have noticed I’m following the Schneier Blogging Template) ...
You can put the word innovation on the back of a box, or in an advertisement, or even in the name of your company, but that does not make it so. Words like radical, game-changing, breakthrough, and disruptive are similarly used to suggest something in lieu of actually being it. You can say innovative as many times as you want, but it won’t make you an innovator, nor make inventions, patents or profits magically appear in your hands.
… but you should really take the time to read the whole article; it's a gem.
Any similarity to the recent Innovation is Everywhere event is obviously pure coincidence. If you don’t believe me, read some more statistics-based debunking from the resident skeptic Michael Shermer.
IP Multicast is like Banyan Vines
Every now and then I stumble upon an elegy lamenting the need to study IP Multicast to pass one or the other certification exam. The history obviously repeats itself; we’ve been dealing with similar problems in the past and one of my favorite examples is Banyan VINES.
If you’ve been working with Cisco routers for more than 15 years, you might still have fond memories of Router Software Configuration (RSC) course, at its time one of the best networking courses. In those prehistoric days, the networks were multi-protocol, running all sorts of things in parallel with IPv4. The week-long RSC course thus covered (at least) the following protocols: IPv4, AppleTalk, Novell IPX, DecNET, XNS, Banyan VINES, CLNP and SNA (I probably forgot one or two). By the third day, everyone (including the instructor) was sick-and-tired of the endless stream of lookalike protocols and ready to skip a section or two.
Poll results: Internet traffic transport options
I was somewhat surprised by the results of my recent “Do you use MPLS to transport Internet traffic?” poll. I had assumed that most Service Provider networks today use MPLS-based BGP-free core, but almost half of the respondents transport Internet traffic natively.
Off-topic: Sounding like the Tin Man
One of the things I wanted to do in the last week was to publish samples of my webinars on YouTube. Sounds simple: you take the Webex recording, convert it to another file format, add an opening and closing slide and you’re done. Like always, the devil is in the details.
Webex has a standalone conversion utility that runs on Linux. The audio retrieval part reliably crashes on my Fedora, so I end up having the advancing slides video with no audio. The conversion process takes as long as the original recording; each try takes quite a long time. No wonder I gave up.
Borderless Networks, Take Two
Another cloudy product launch happened on Wednesday: the next step in the Borderless Networks saga with the tagline Innovation is Everywhere (what a revelation; we were not aware of that before the event).
Must read: why is cloud computing a bad metaphor
I wanted to entertain you with some juicy opinions about the webcast, but that will have to wait; I’m going rock climbing in a few minutes. In the meantime, you can satisfy your inner Dilbert with a comprehensive technical (what a relief!) summary of the products and technologies launched on Wednesday published by Jennifer McAdams in the Cisco’s Innovation blog. Thank you, Jennifer! Great job; exactly what the engineers need.
CLNS and CLNP
Yap Chin Hoong has been looking at the OSI protocol stack I’ve published and asked an interesting question: “where is CLNS in that protocol stack?”
The OSI protocol stack has a major advantage over the TCP/IP stack: it defines both the protocols and the APIs between the layers. CLNS (Connection-less network Service) is the API (the function calls that allow transport layers to exchange datagrams across the network) while CLNP (Connection-less network Protocol) is the layer-3 protocol that implements CLNS. In my diagram, CLNS would be a thin line above CLNP between L3 and L4 boxes.