Azure Networking Update Is Completed
I planned to write a few interesting blog posts last week, but then got sucked into updating Azure Networking webinar. At least I got that completed 😊; the webinar materials now include these new Azure services:
I also added descriptions of numerous new features:
netlab Release 1.4.1: Cisco ASAv
The star of the netlab release 1.4.1 is Cisco ASAv support: IPv4 and IPv6 addressing, IS-IS and BGP, and libvirt box building instructions.
Other new features include:
- VRRP on VyOS
- Anycast gateway and VRRP on Dell OS10 (with a bunch of caveats)
- Unnumbered OSPF interfaces on VyOS
- Support for all EVPN bundle services
- FRR version 8.4.0
Upgrading is as easy as ever: execute pip3 install --upgrade networklab.
New to netlab? Start with the Getting Started document and the installation guide.
Congestion Control Algorithms Are Not Fair
Creating a mathematical model of queuing in a distributed system is hard (Queuing Theory was one of the most challenging ipSpace.net webinars so far), and so instead of solutions based on control theory and mathematical models we often get what seems to be promising stuff.
Things that look intuitively promising aren’t always what we expect them to be, at least according to an MIT group that analyzed delay-bounding TCP congestion control algorithms (CCA) and found that most of them result in unfair distribution of bandwidth across parallel flows in scenarios that diverge from spherical cow in vacuum. Even worse, they claim that:
[…] Our paper provides a detailed model and rigorous proof that shows how all delay-bounding, delay-convergent CCAs must suffer from such problems.
It seems QoS will remain spaghetti-throwing black magic for a bit longer…
Worth Reading: Troubleshooting EVPN Control Plane
When trying to decide whether to use EVPN for your next data center fabric, you might want to consider how easy it is to configure and troubleshoot.
You’ll find a few configuration hints in the Multivendor Data Center EVPN part of the EVPN Technical Deep Dive webinar. For the troubleshooting part, check out the phenomenal Troubleshooting EVPN with Arista EOS article by Tony Bourke.
Video: Cloud Infrastructure-as-Code
With AWS re:Invent 2022 being just a few days away, it’s time for another cloudy Friday video: using infrastructure-as-code principles to provision public cloud resources by Matthias Luft (part of Introduction to Cloud Computing webinar).
Azure Networking Update (Phase 1)
Last week I completed the first part of the annual Azure Networking update. The Azure Firewall section is already online; hope you’ll find it useful. I already have the materials for the Private Link and Gateway Load Balancer services, but haven’t decided whether to schedule another live session to cover them, or just create a short video.
Then there are a half-dozen smaller things I found while processing a year worth of Azure networking News. You’ll find them (and links to documentation) in New Azure Services and Features document.
Integrated Routing and Bridging (IRB) Design Models
Imagine you built a layer-2 fabric with tons of VLANs stretched all over the place. Now the users want to exchange traffic between those VLANs, and the obvious question is: which devices should do layer-2 forwarding (bridging) and which ones should do layer-3 forwarding (routing)?
There are four typical designs you can use to solve that challenge:
- Exchange traffic between VLANs outside of the fabric (edge routing)
- Route on core switches (centralized routing)
- Route on ingress (asymmetric IRB)
- Route on ingress and egress (symmetric IRB)
This blog post is an overview of the design models; we’ll cover each design in a separate blog post.
Network Automation: a Service Provider Perspective
Antti Ristimäki left an interesting comment on Network Automation Considered Harmful blog post detailing why it’s suboptimal to run manually-configured modern service provider network.
I really don’t see how a network any larger and more complex than a small and simple enterprise or campus network can be developed and engineered in a consistent manner without full automation. At least routing intensive networks might have very complex configurations related to e.g. routing policies and it would be next to impossible to configure them manually, at least without errors and in a consistent way.
netlab: IRB with Anycast Gateways
netlab release 1.4 added support for static anycast gateways and VRRP. Today we’ll use that functionality to add anycast gateways to the VLAN trunk lab:
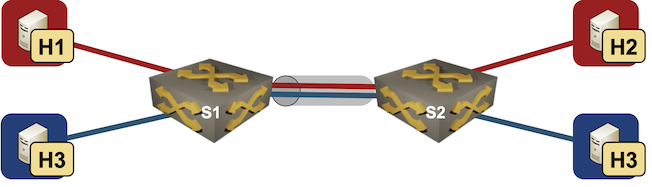
Lab topology
We’ll start with the VLAN trunk lab topology and make the following changes:
Worth Reading: Resolverless DNS
Geoff Huston published a lengthy article (as always) describing talks from recent OARC meeting, including resolver-less DNS and DNSSEC deployment risks.
Definitely worth reading if you’re at least vaguely interested in the technology that supposedly causes all network-related outages (unless it’s BGP, of course)