Precedence of Ansible Extra Variables
I stay as far away from Ansible as possible these days and use it only as a workflow engine to generate device configurations from Jinja2 templates and push them to lab devices. Still, I manage to trigger unexpected behavior even in these simple scenarios.
Ansible has a complex system of variable (fact) precedence, which mostly makes sense considering the dozen places where a variable value might be specified (or overwritten). Ansible documentation also clearly states that the extra variables (specified on the command line with the -e keyword) have the highest precedence.
Now consider these simple playbooks. In the first one, we’ll set a fact (variable) and then print it out:
BGP Labs: Override Neighbor AS Number in AS Path
When I described the need to turn off the BGP AS-path loop prevention logic in scenarios where a Service Provider expects a customer to reuse the same AS number across multiple sites, someone quipped, “but that should be fixed by the Service Provider, not offloaded to the customer.”
Not surprisingly, there’s a nerd knob for that (AS override), and you can practice it in the next BGP lab exercise: Fix AS-Path in Environments Reusing BGP AS Numbers.
Availability Zones in VMware NSX-Based Cloud
One of the ipSpace.net subscribers sent me this question:
How could I use NSX to create a cloud-like software network layer enabling a VMware enterprise to create a public cloud-like availability zone concept within a data center (something like Oracle Cloud does)?
That’s easy: stop believing in VMware marketing shenanigans.
Podcast: Network Automation Source(s) of Truth
Figuring out how to describe your network (also known as “create a source of truth”) is one of the most challenging tasks you’ll face when building a network automation solution (more). As always, the devil is in the details, starting with “and what exactly is The Truth?”.
We discussed those details in a lively Packet Pushers podcast with Claudia de Luna, David Sinn, Dinesh Dutt, Drew Conry-Murray and Ethan Banks. Have fun!
BGP Labs: Work with FRR and Cumulus Linux
FRR or (pre-NVUE) Cumulus Linux are the best bets if you want to run BGP labs in a resource-constrained environment like your laptop or a small public cloud instance. However, they both behave a bit differently from what one might expect from a networking device, including:
- Interfaces are created through standard Linux tools;
- You have to start the FRR management CLI from the Linux shell;
- If you need a routing daemon (for example, the BGP daemon), you must enable it in the FRR configuration file and restart FRR.
A new lab exercise covers these intricate details and will help you get fluent in configuring BGP on FRR or Cumulus Linux virtual machines or containers.
BGP Graceful Restart Considered Harmful
A networking engineer with a picture-perfect implementation of a dual-homed enterprise site using BGP communities according to RFC 1998 to select primary- and backup uplinks contacted me because they experienced unacceptably long failover times.
They measured the failover times caused by the primary uplink loss and figured out it takes more than five minutes to reestablish Internet connectivity to their site.
Is It The End, Or Can You Do Something in 2024?
David Bombal invited me for another annual chat last December, focusing on (what else) networking careers in 2024. The results were published a few days ago, and I was amazed at how good it turned out. I always love chatting with David; this time, his editing team did a masterful job.
netlab 1.7.1: Eye Candy

What do you get when you write code next to a Christmas tree? You can expect to get tons of eye candy, and that’s what netlab release 1.7.1 is all about.
It all started with a cleanup idea: I could replace the internal ASCII table-drawing code with the prettytable library. Stefan was quick to point out that I should be looking at the rich library, and the rest is history:
Registration No Longer Needed to Download Free PDFs
I published dozens of free-to-download slide decks on ipSpace.net. Downloading them required the free ipSpace.net subscription which is no longer available because I refuse to play a whack-a-mole game with spammers.
You might like the workaround I had to implement to keep those PDFs accessible: they are no longer behind a regwall.
You can find the list of all the free content ipSpace.net content here. The Conferences and Presentations page is another source of links to public presentations.
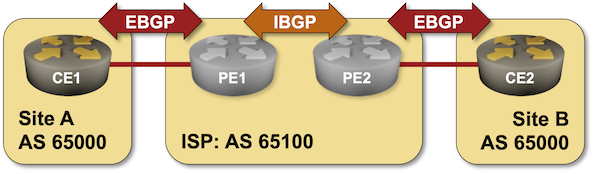
BGP Labs: Reuse BGP AS Number Across Sites
When I published the Bidirectional Route Redistribution lab exercise, some readers were quick to point out that you’ll probably have to reuse the same AS number across multiple sites in a real-life MPLS/VPN deployment. That’s what you can practice in today’s lab exercise – an MPLS/VPN service provider allocated the same BGP AS number to all your sites and expects you to deal with the aftermath.