MLAG Deep Dive: LAG Member Failures in VXLAN Fabrics
In the Dealing with LAG Member Failures blog post, we figured out how easy it is to deal with a LAG member failure in a traditional MLAG cluster. The failover could happen in hardware, and even if it’s software-driven, it does not depend on the control plane.
Let’s add a bit of complexity and replace a traditional layer-2 fabric with a VXLAN fabric. The MLAG cluster members still use an MLAG peer link and an anycast VTEP IP address (more details).
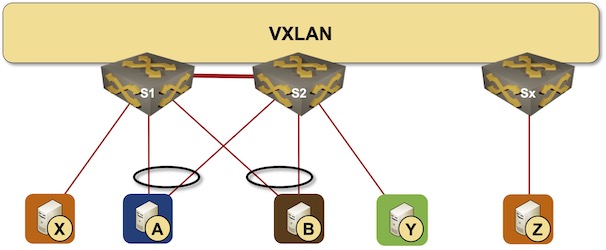
MLAG cluster connected to a VXLAN fabric
The good news: nothing has changed. For example, when the S1-A link fails, S1 immediately starts forwarding the traffic toward A over the peer link, and S2 forwards those packets to the S2-A link. We still need control-plane adjustments to enable flooding, but the unicast traffic flow is uninterrupted.
Now let’s add EVPN to the mix and assume that the MLAG cluster members advertise the MAC and IP addresses of the dual-connected nodes with the anycast IP address as the next hop, and the addresses of the orphan nodes with the switch-specific VTEP IP address as the next hop (more details).
MLAG members can still use the failover to the peer link, keeping the unicast traffic uninterrupted. They can even keep quiet about the change if they don’t use unicast VTEP IP addresses in EVPN updates.
However, an optimized EVPN implementation that uses anycast VTEP for dual-connected nodes and unicast VTEP for orphan nodes has to tell the rest of the fabric to use an optimized forwarding path (send the traffic straight to the switch connected to the orphan node).
It’s no big deal. The switch connected to the orphan node (S2 in our example) can fake a MAC move event and advertise A’s MAC address with an increased sequence number and unicast next hop. The switch dealing with the link failure (S1 in our example) can revoke the original advertisement for MAC-A, and the failover is seamless; not a single unicast packet needs to be lost during EVPN convergence.
Not surprisingly, the situation is not as rosy if your vendor believes in EVPN-only multihoming.
We dont use vpc in our setup for vxlan and evpn.We use individual Unique next hop for each Leaf pair .In this case convergence works out easily, when S1--A link fails, S1 withdraws the MAC address and IP address and traffic automatically switches from S1 to S2.
That is true, but some people with operational experience keep complaining about convergence times. Anyhow, we'll cover this setup in the next blog post.
For convergence, set the MAC address aging timer to 10 seconds and underlying routing protocol should be ISIS where the next hop is pointed to the new next hop.
Use arping on the Linux Host to send traffic locally so that the local switch doesnt timeout the MAC and withdraw the prefixes.
Well-implemented MLAG with a peer link can give you convergence in milliseconds. What convergence time are you talking about?
Convergence of MAC IP in the customer network. Vlan based MAC network and VNI based MAC network.
Many servers (hosts) dont support vpc or multi chassis LAG and hence it is easy to implement vxlan evpn fabrics without LAGs
It's true that many servers don't support VPC/MLAG. To be fair, I've never seen one unless you count Cumulus Linux as a host ;)
However, that's irrelevant. The beauty of MLAG is that the server does not know it's connected to two switches. See https://blog.ipspace.net/2010/10/multi-chassis-link-aggregation-basics.html for more details.
In the scenario which i am working , We have ESXi hosts with 2 uplinks connected to two Leaf switches,ESXi doesnt support vpc and hence broadcast hashing is not possible.
Esxi sends broadcast traffic on two uplinks and creates a loop with vpc peer link.
When u create vpc on the two switches, on ESXi puts a error message saying LACP system ID is different. In ESxi LACP system ID has to be same on both the leaf switches.
I guess it's time to go back to the basics of how ESXi networking works. Either you have LAG configured on both ends of the link, or you have a disaster on your hands (blog posts were written about this at least 15 years ago).
Also, if a host complains about a mismatch in the remote LACP system ID, then you configured MLAG incorrectly.
However, this is totally off-topic, so let's stop the discussion.