MLAG Deep Dive: Dealing with LAG Member Failures
Craig Weinhold pointed me to a complex topic I managed to ignore in my MLAG Deep Dive series: how does an MLAG cluster reroute around a failure of a LAG member link?
In this blog post, we’ll focus on traditional MLAG cluster implementations using a peer link; another blog post will explore the implications of using VXLAN and EVPN to implement MLAG clusters.
We’ll also ignore the interesting question of “how is the LAG member link failure detected?”1 and focus on “what happens next?” using the sample MLAG topology:
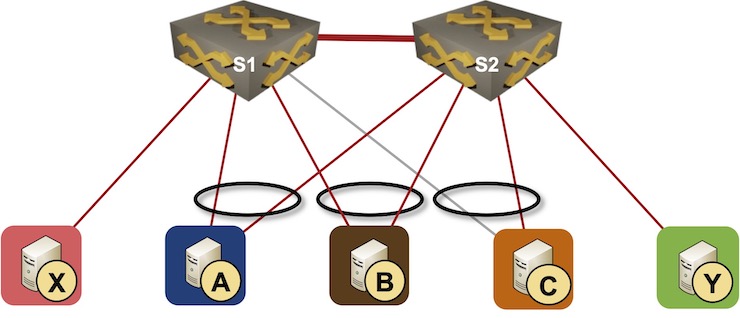
Simple MLAG topology
Imagine the link A-S1 fails. S1 can no longer send traffic to A, but it knows (through control-plane communication) that the link between S2 and A still works. To keep forwarding traffic to A, S1 needs to replace the (now defunct) forwarding entry for MAC-A with an entry pointing to the peer link.
That change could be made by the local control plane or preprogrammed in the forwarding ASIC (see the fast failover series for more details). There’s no need to flush the local MAC table entries, involve STP link-down procedures, or wait for MAC-A to be rediscovered through dynamic MAC learning.
What happens on S2 depends on the way its forwarding ASIC is programmed (see MLAG Deep Dive: Layer-2 Flooding for more details). S2 could use a simple ACL that blocks packets arriving through the peer link from being sent to MLAG member links or a more sophisticated approach in which only the flooded packets are blocked to prevent duplicate flooded packets from being sent to MLAG-attached nodes.
Suppose S2 blocks all traffic arriving through the peer link from reaching A. In that case, we’re dealing with a hard-to-troubleshoot failure scenario in which approximately 50% of the traffic sent toward A is dropped until S2 adjusts its forwarding data structures.
| Traffic flow | Forwarded or blocked? |
|---|---|
| X → A | blocked |
| X → Y | forwarded |
| B → A (via S1) | blocked |
| B → A (via S2) | forwarded |
A more optimal implementation (forward unicast traffic but do not flood traffic from the peer link onto MLAG member links) would retain full unicast connectivity while dropping some of the BUM traffic (similar to the above table). BUM traffic flooding must be restored through a control-plane intervention: when S1 informs S2 that it lost all MLAG member links with A, S2 turns A into an orphan node, adjusts the peer link ACL, and starts flooding BUM traffic from the peer link to the S2-A link.
Finally, it’s worth noting that the MLAG member link failure remains a localized event. LAG is implemented pretty low in the data link layer, and a member link failure does not propagate to higher layers. STP or routing protocols are, therefore, not involved. Unicast traffic should recover almost instantaneously (in the millisecond range, but see Fast Failover Techniques and Technologies for details), and the flooding resumes after the switches participating in the MLAG cluster synchronize their control planes (hopefully in the tens or hundreds of milliseconds range).
Next: LAG Member Failures in VXLAN Fabrics Continue
-
The answer to that one could be Gigabit Ethernet OAM, micro-BFD, UDLD, or LACP ↩︎