EVPN Rerouting After LAG Member Failures
In the previous two blog posts (Dealing with LAG Member Failures, LAG Member Failures in VXLAN Fabrics) we discovered that it’s almost trivial to deal with a LAG member failure in an MLAG cluster if we have a peer link between MLAG members. What about the holy grail of EVPN pundits: ESI-based MLAG with no peer link between MLAG members?
EVPN-based MLAG
Before moving on: A huge THANK YOU to Craig Weinhold, who did fantastic research on the topic and sent me most of the external links.
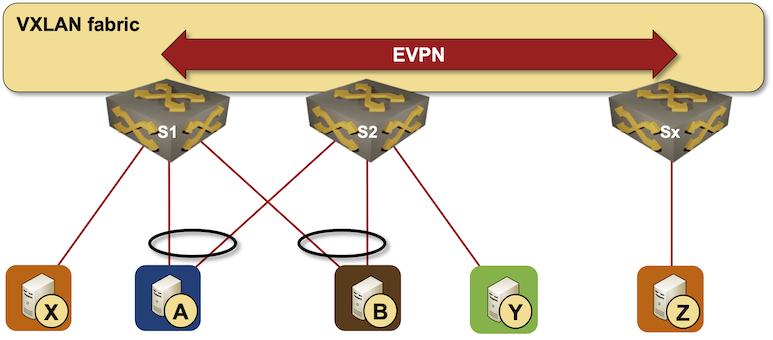
Back to EVPN. In our setup:
- S1 and S2 might both advertise MAC-A; if they do, the next hops will be different unless you’re using anycast VTEP IP addresses. The type-2 routes include Ethernet Segment Identifier (ESI) to make the active-active multihoming magic work.
- S1 and S2 advertise the link (Ethernet Segment) to A with type-4 EVPN route, allowing other nodes to figure out they can do load balancing across the two VTEPs (assuming the ASIC supports that)
- S1 and S2 figure out who the Designated Forwarder for the segment is. Even though they both receive BUM frames for the VLANs in which A participates, only one of them sends them to A.
For more high-level details, read the excellent Multihoming Models with EVPN whitepaper. If you want even more information, I’m sure you’ll find it; there are plenty of let’s dive into EVPN and dissect it articles on the Internet.
Now let’s assume the S1-A link fails, resulting in a flurry of EVPN BGP updates. S1 revokes the type-4 (ESI) route for the S1-A link and the MAC-A type-2 (MAC) route. Once the BGP routing updates propagate to the remote PE devices (for example, Sx), the remote PE devices either remove MAC-A from their forwarding table (if S2 never advertised MAC-A) or remove VTEP-S1 from the ECMP group for all MAC addresses advertised by S1 with the S1-A ESI. In the worst case, the remote PE devices must wait for S2 to advertise the MAC-A type-2 route.
Long story short: Using EVPN to implement an MLAG cluster transformed a local data-plane action that could be performed in milliseconds into a control-plane action that has to be propagated (often through a BGP route reflector) and executed on remote nodes. The EVPN-only switchover might take two or more orders of magnitude longer than the local peer link switchover. Quoting the pretty level-headed Arista whitepaper1:
With the A-A model relying on both the convergence of the underlay and EVPN overlay during a failover event, when compared to a similar MLAG topology, the A-A approach will result in more state churn across the EVPN domain and potentially slower convergence2.
We had a similar problem in traditional MPLS/VPN networks, where we used BGP PIC Edge to turn a distributed control-plane convergence into a local data-plane convergence. With the BGP PIC Edge, a PE router uses a stack of labels to push a packet that arrives at a node with a failed link straight to the outgoing interface of another node. Supposedly, we can use VTEP PIC Edge to achieve the same fast failover in VXLAN/EVPN networks. Back to Arista’s whitepaper:
To avoid any blackholing of traffic during this re-convergence, the node exhibiting the local link failure can also be configured to pre-calculate a backup path for the withdrawn routes via a VXLAN tunnel to peer node connected to the same ES, this is termed VTEP PIC edge.
VTEP PIC Edge has just two tiny little problems3:
- It needs VXLAN-to-VXLAN bridging to work (see MLAG Clusters without a Physical Peer Link for more details), and not all ASICs support that.
- VXLAN header has a single “label” (Virtual Network Identifier – VNI). Forwarding a misdirected packet to a peer node’s outgoing interface is impossible. We can only send the packet to the peer node – an excellent source of potential bridging microloops4.
You might not care about convergence speed after a LAG member failure. Feel free to use whatever solution you want if you’re OK with a blackhole that might (worst case) persist for a few seconds5. However, if your applications depend on millisecond-speed failover, you might be better off using more traditional MLAG solutions.
-
Arista supports traditional MLAG clusters, MLAG clusters with anycast VTEPs, and EVPN-only multihoming and thus has no skin in this game. ↩︎
-
I guess that’s as close as we’ll get to a vendor saying “Houston, we might have a problem” ;) ↩︎
-
I love the sound of works-best-in-PowerPoint throwaway claims in vendor whitepapers. ↩︎
-
Micro loops are a fact of life. However, we’re dealing with Ethernet packets that have no TTL and could be flooded to multiple ports. I know of several data centers that were brought down by flooding loops caused by bugs in MLAG software (in some cases, they lost two data centers because they listened to VMware consultants). Why should EVPN-based multihoming be any different? ↩︎
-
You can find horror stories claiming 20 second or even 37 second convergence times. I’m positive convergence times longer than a few seconds are a result of a configuration error, but even Juniper admits that “When there are changes in the network topology in a large-scale EVPN system, the convergence time might be significant.” ↩︎
The IETF draft (https://datatracker.ietf.org/doc/draft-rabnag-bess-evpn-anycast-aliasing/) does a good job of exploring the four systemic architecture problems with EVPN multihoming: * Control Plane Scale * Convergence and Processing overhead * Hardware Resource consumption * Inefficient forwarding during a failure
Convergence time will catch people's attention, but hardware and scale limitations may be even a more serious concern for large networks.
One more reason why I love SPB-M. LAG/Interface/Node the behaviour is always the same + redundant path is already know!
Take a look on that short video just make sense https://www.youtube.com/watch?v=i5HA50wc7kw&t=43s