Blog Posts in September 2023
Worth Reading: Single-Port LAGs
Lindsay Hill described an excellent idea: all ports on your switches routers should be in link aggregation groups even when you have a single port in a group. That approach allows you to:
- Upgrade the link speed without changing any layer-3 configuration
- Do link maintenance without causing a routing protocol flap
It also proves RFC 1925 rule 6a, but then I guess we’re already used to that ;)
How GitHub Saved My Day
I always tell networking engineers who aspire to be more than VLAN-munging CLI jockeys to get fluent with Git. I should also be telling them that while doing local version control is the right thing to do, you should always have backups (in this case, a remote repository).
I’m eating my own dog food1 – I’m using a half dozen Git repositories in ipSpace.net production2. If they break, my blog stops working, and I cannot publish new documents3.
Now for a fun fact: Git is not transactionally consistent.
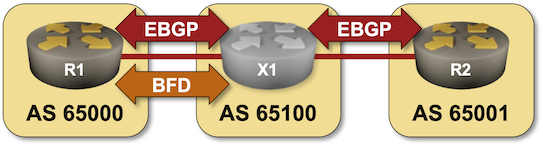
BGP Labs: Use BFD to Speed Up Convergence
In the next BGP labs exercise, you can practice tweaking BGP timers and using BFD to speed up BGP convergence.
Why Do We Need Source IP Addresses in IP Headers?
After discussing names, addresses and routes, and the various addresses we might need in a networking stack, we’re ready to tackle an interesting comment made by a Twitter user as a reply to my Why Is Source Address Validation Still a Problem? blog post:
Maybe the question we should be asking is why there is a source address in the packet header at all.
Most consumers of network services expect a two-way communication – you send some stuff to another node providing an interesting service, and you usually expect to get some stuff back. So far so good. Now for the fun part: how does the server know where to send the stuff back to? There are two possible answers1:
Does EVPN/VXLAN over SD-WAN Make Sense?
It looks like we might be seeing VXLAN-over-SDWAN deployments in the wild. Here’s the “why that makes sense” argument I received from a participant of the ipSpace.net Design Clinic in which I wasn’t exactly enthusiastic about the idea.
Also, the EVPN-over-WAN idea is not hypothetical since EVPN+VXLAN is now the easiest way to build L3VPN with data center switches that don’t support MPLS LDP. Folks with no interest in EVPN’s L2 features are still using it for L3VPN.
Let’s unravel this scenario a bit:
Repost: L2 Is Bad
Roman Pomazanov documented his thoughts on the beauties of large layer-2 domains in a LinkedIn article and allowed me to repost it on ipSpace.net blog to ensure it doesn’t disappear
First of all: “L2 is a single failure domain”, a problem at one point can easily spread to the entire datacenter.
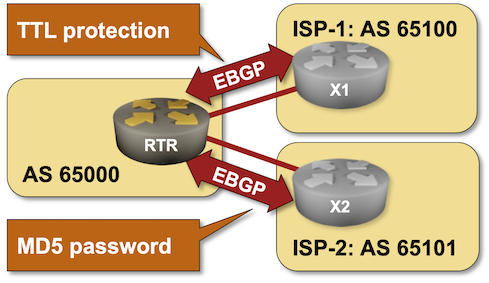
BGP Labs: Protect EBGP Sessions
I published another BGP labs exercise a few days ago. You can use it to practice EBGP session protection, including Generalized TTL Security Mechanism (GTSM) and TCP MD5 checksums1.
-
I would love to add TCP-AO to the mix, but it’s not yet supported by the Linux kernel, and so cannot be used in Cumulus Linux or FRR containers. ↩︎
Addresses in a Networking Stack
After discussing names, addresses and routes, it’s time for the next question: what kinds of addresses do we need to make things work?
End-users (clients) are usually interested in a single thing: they want to reach the service they want to use. They don’t care about nodes, links, or anything else.
End-users might want to use friendly service names, but we already know we need addresses to make things work. We need application level service identifiers – something that identifies the services that the clients want to reach.
Names, Addresses, and Routes
It always helps to figure out the challenges of a problem you’re planning to solve, and to have a well-defined terminology. This blog post will mention a few challenges we might encounter while addressing various layers of the networking stack, from data-link layer and all the way up to the application layer, and introduce the concepts of names, addresses and routes.
According to Martin Fowler, one of the best quotes I found on the topic originally came from Phil Karlton:
Dataplane MAC Learning with EVPN
Johannes Resch submitted the following comment to the Is Dynamic MAC Learning Better Than EVPN? blog post:
I’ve also recently noticed some vendors claiming that dataplane MAC learning is so much better because it reduces the number of BGP updates in large scale SP EVPN deployments. Apparently, some of them are working on IETF drafts to bring dataplane MAC learning “back” to EVPN. Not sure if this is really a relevant point - we know that BGP scales nicely, and its relatively easy to deploy virtualized RR with sufficient VPU resources.
While he’s absolutely correct that BGP scales nicely, the questions to ask is “what is the optimal way to deliver a Carrier Ethernet service?”
Worth Reading: Where Are the Self-Driving Cars?
Gary Marcus wrote an interesting essay describing the failure of self-driving cars to face the unknown unknowns. The following gem from his conclusions applies to AI in general:
In a different world, less driven by money, and more by a desire to build AI that we could trust, we might pause and ask a very specific question: have we discovered the right technology to address edge cases that pervade our messy really world? And if we haven’t, shouldn’t we stop hammering a square peg into a round hole, and shift our focus towards developing new methodologies for coping with the endless array of edge cases?
BGP Labs: Bidirectional Route Redistribution
In the next BGP labs exercise, you’ll build the customer part of an MPLS/VPN solution. You’ll use bidirectional OSPF-to-BGP route redistribution to connect two sites running OSPF over a Service Provider MPLS backbone.

DHCP Relaying Across a Firewall
Chinar Trivedi wanted to know what happens when you insert a firewall in the DHCP data path (original question.
TL&DR: Nothing much, but that does not mean you should.
Now for the details:
OSPF ECMP with Unnumbered IPv4 Interfaces
or how netlab made labbing fun again
The OSPF and ARP on Unnumbered IPv4 Interfaces triggered an interesting consideration: does ECMP work across parallel unnumbered links?
TL&DR: Yes, it works flawlessly on Arista EOS and Cisco IOS/XE. Feel free to test it out on any other device on which netlab supports unnumbered interfaces with OSPF.
Reliable ECMP with Static Routing
One of my readers wanted to use EIBGP to load balance outgoing traffic from a pair of WAN edge routers (hint: wrong tool for this particular job1). He’s using a design very similar to this one with VRRP running between WAN edge routers, and the adjacent firewall cluster using a default route to the VRRP IP address.
The problem: all output traffic goes to the VRRP IP address which is active on one of the switches, and only a single uplink is used for the outgoing traffic.
Case Study: BGP Routing Policy
Talking about BGP routing policy mechanisms is nice, but it’s even better to see how real Internet Service Providers use those tools to implement real-life BGP routing policy.
Getting that information is incredibly hard as everyone considers their setup a secret sauce. Fortunately, there are a few exceptions; Pim van Pelt described the BGP Routing Policy of IPng Networks in great details. The article is even more interesting as he’s using Bird2 configuration language that looks almost like a programming language (as compared to the ancient route-maps used by vendors focused on “industry-standard” CLI).
Layer-3 WAN Handoff (L3Out) in VXLAN/EVPN Fabrics
I got a question from a few of my students regarding the best way to implement end-to-end EVPN across multiple locations. Obviously there’s the multi-pod and multi-site architecture for people believing in the magic powers of stretching VLANs across the globe, but I was looking for something that I could recommend to people who understand that you have to have a L3 boundary if you want to have multiple independent failure domains (or availability zones).
Random Thoughts on Zero-Trust Architecture
When preparing the materials for the Design Clinic section describing Zero-Trust Network Architecture, I wondered whether I was missing something crucial. After all, I couldn’t find anything new when reading the NIST documents – we’ve seen all they’re describing 30 years ago (remember Kerberos?).
In late August I dropped by the fantastic Roundtable and Barbecue event organized by Gabi Gerber (running Security Interest Group Switzerland) and used the opportunity to join the Zero Trust Architecture roundtable. Most other participants were seasoned IT security professionals with a level of skepticism approaching mine. When I mentioned I failed to see anything new in the now-overhyped topic, they quickly expressed similar doubts.
BGP Labs: Simple Routing Policy Tools
The first set of BGP labs covered the basics; the next four will help you master simple routing policy tools (BGP weights, AS-path filters, prefix filters) using real-life examples:
- Use BGP weights to prefer one of the upstream providers
- Prevent route leaking between upstream providers with an AS-path filter
- Filter prefixes advertised by your autonomous system with a prefix list
- Minimize the size of your BGP table with inbound filters
The labs are best used with netlab (it supports BGP on almost 20 different devices), but you could use any system you like (including GNS3 and CML/VIRL). For more details, read the Installation and Setup documentation.
Lifetime ipSpace.net Subscription
More than thirteen years after I started creating vendor-neutral webinars, it’s time for another change1: the ipSpace.net subscriptions became perpetual. If you have an active ipSpace.net subscription, it will stay valid indefinitely2 (and I’ll stop nagging you with renewal notices).
Wow, Free Lunch?
Sadly, that’s not the case.