Blog Posts in February 2023
Alternatives to IBGP within Multihomed Sites
Two weeks ago I explained why you might want to run IBGP between CE-routers on a multihomed site. One of the blog readers didn’t like my ideas:
In such a small deployment I assume that both ISPs offer transit, so that both CEs would get a default route from their upstream.
In this case I would not iBGP the CEs together but have HSRP running on the two CEs and track the uplink (interface and/of BGP session) to determine the active gateway.
Let’s see what could possibly go wrong with that design.
Suspending Devices in netlab Labs
A networking engineer tired of waiting for network devices to start sent me this question:
Can you suspend VMs in netlab? I use this trick in vSphere with CSR1Kv.
TL&DR: Maybe. Probably not.
Video: Packet Buffers in Data Center ASICs
A few years ago, we were fortunate enough to have Pete Lumbis talking about ASICs for Networking Engineers as part of the Data Center Fabric Architectures webinar.
One of the topics he couldn’t possibly skip was the question of how many packet buffers one needs in a data center switch.
How Many Spines Should a Leaf-and-Spine Fabric Have?
One of my readers sent me a question along these lines:
How do we determine the number of spines needed in a leaf-and-spine fabric? It’s easy to calculate the number of leaf nodes from the required number of server ports, and two spines give you the redundancy. Does it make sense to have more spines if two are good enough from the capacity perspective?
There are at least two factors to consider:
… updated on Thursday, March 2, 2023 15:13 UTC
Measuring Virtual Network Device Boot Times
A senior engineer at Juniper Networks wasn’t happy with me mentioning resource hogs and Junos platforms in the same statement. Instead of engaging in never-ending angels dancing on pins deliberations comparing the virtues of Junos with other network operating systems, I decided to throw a bit of real-life data into the mix – I created a simple script that measures:
- The time it takes to execute vagrant up to start a single network device.
- The time it takes to deploy simple initial configuration on that device.
Some Operations Are Not Worth Automating
Ish wrote an interesting comment on my Network Automation Expert Beginners blog post. He started with:
[Our network has] about 40 sites, but we don’t do total refresh cycles in bulk, just as needed. Everything we do is sporadic, and I’m trying to see the ROI on learning automation for things that are done once in a while that don’t take much time to do manually anyway.
There are two aspects to this part of his comment:
Start Multiple netlab Labs on the Same Server
A heavy netlab user sent me an email along these lines:
We’re running multiple labs in parallel on the same server, and we’re experiencing all sorts of clashes like overlapping management IP addresses. We “solved” that by using static device identifiers in our labs, but I’m wondering if there’s a better way of doing it?
That’s exactly the sort of real-life challenges I love working on, so it wasn’t hard to get me excited, and the results are bundled in netlab release 1.5.
Worth Reading: On ChatGPT
One of the best descriptions of what ChatGPT does and what it cannot do I found so far comes from an ancient and military historian. The what is ChatGPT and what is an essay parts are a must-read, the preparing to be disrupted conclusion is pure gold:
I do think there are classrooms that will be disrupted by ChatGPT, but those are classrooms where something is already broken.
I can’t help but think of the never-ending brouhaha about exam brain dumps.
Video: Link State Routing Protocol Basics
The Routing Protocols Overview part of How Networks Really Work webinar introduced the concepts of distance-vector and link-state routing protocols. Next step: the basics of link-state routing protocols.
Feedback: Designing Active/Active and Disaster Recovery Data Centers
In the Designing Active-Active and Disaster Recovery Data Centers I tried to give networking engineers a high-level overview of challenges one might face when designing a highly-available application stack, and used that information to show why the common “solutions” like stretched VLANs make little sense if one cares about application availability (as opposed to auditor report). Some (customer) engineers like that approach; here’s the feedback I received not long ago:
As ever, Ivan cuts to the quick and provides not just the logical basis for a given design, but a wealth of advice, pointers, gotchas stemming from his extensive real-world experience. What is most valuable to me are those “gotchas” and what NOT to do, again, logically explained. You won’t find better material IMHO.
Please note that I’m talking about generic multi-site scenarios. From the high-level connectivity and application architecture perspective there’s not much difference between a multi-site on-premises (or collocation) deployment, a hybrid cloud, or a multicloud deployment.
CE-to-CE IBGP Session in a Multihomed Site
One of my readers sent me a question along these lines:
Do I have to have an IBGP session between Customer Edge (CE) routers in a multihomed site if they run EBGP with the upstream provider(s)?
Let’s start with a simple diagram and a refactoring of the question:
MUST READ: Machine Learning for Network and Cloud Engineers
Javier Antich, the author of the fantastic AI/ML in Networking webinar, spent years writing the Machine Learning for Network and Cloud Engineers book that is now available in paperback and Kindle format.
I’ve seen a final draft of the book and it’s definitely worth reading. You should also invest some time into testing the scenarios Javier created. Here’s what I wrote in the foreword:
Artificial Intelligence (AI) has been around for decades. It was one of the exciting emerging (and overhyped) topics when I attended university in the late 1980s. Like today, the hype failed to deliver, resulting in long, long AI winter.
Start Large netlab Topologies in Smaller Batches
It’s incredible how little CPU resources some network devices consume in a steady state – a netlab user managed to run almost 100 Mikrotik routers on a 24-core server. Starting them simultaneously (like vagrant up tries to do when used with the vagrant-libvirt plugin) is a different story. The router virtual machines are configured with two CPU cores for a good reason, and if they don’t get enough CPU cycles during the boot time, they get sluggish, Vagrant gives up, and the lab start procedure fails.
One could use a nasty workaround:
Video: Kubernetes SDN Architecture
Stuart Charlton started the Kubernetes Networking Deep Dive webinar with an overview of basic concepts including the networking model and services. After covering the fundamentals, it was time for The Real Stuff: Container Networking Interface, starting with an overview of Kubernetes SDN architecture.
Real-Life Not-Exactly-Networking AI Use Case
I get several emails every week1 from people I never heard of telling me what a wonderful job they could do writing guest blog posts on a range of topics of interest to my audience.
I’m positive you must be pretty intelligent to be a successful scammer, so I’m sure the good ones are using ChatGPT to generate the “unique” content they’re promising. I felt it was high time to return the favor.
Response: Nothing Works (in Enterprise IT)
Dmitry Perets left a thoughtful comment on my Nothing Works blog post describing why enterprise IT might be even worse than consumer world.
I think another reason for the “Nothing Works” world is that the only true Management Plane separation that exists in our industry is that of the real “human” management. In the medium/large enterprises they (and their interests, KPIs and so on) are very much separated from the technical workforce. And increasingly so, because today the technical workforce might not even be the employees of the same enterprise. They are likely to come from some IT consultancy outsource – degree of separation which makes a true SDN evangelist envious.
Improve BGP Startup Time on Cisco IOS
I like using Cisco IOS for my routing protocol virtual labs1. It uses a trivial amount of memory2 and boots relatively fast. There was just one thing that kept annoying me: Cisco IOS release 15.x takes forever to install local routes in the BGP table and even longer to select the best routes and propagate them3.
I finally found the culprit: bgp update-delay nerd knob. Here’s what the documentation has to say about it:
Mix Containers and VMs with netlab Release 1.5.0
Maybe it’s just me, but I always need a few extra devices in my virtual labs to have endpoints I could ping to/from or to have external routing information sources. We used VRF- and VLAN tricks in the days when we had to use physical devices to carve out a dozen hosts out of a single Cisco 2501, and life became much easier when you could spin up a few additional virtual machines in a virtual lab instead.
Unfortunately, those virtual machines eat precious resources. For example, netlab allocates 1GB to every Linux virtual machine when you only need bash and ping. Wouldn’t it be great if you could start that ping in a busybox container instead?
Worth Reading: 2 Mpps on a Pentium CPU
Robert Graham published a blog post describing how his IDS/IPS system handled 2 Mpps on a Pentium III CPU 20 years ago… and yet some people keep claiming that “Driving a 100 Gbps network at 80% utilization in both directions consumes 10–20 cores just in the networking stack” (in 2023). I guess a suboptimal-enough implementation can still consume all the CPU cycles it can get and then some.
Video: Migrating into a Cloud
Matthias Luft concluded his part of Introduction to Cloud Computing webinar with a case study: how can you migrate an existing workload into a cloud environment?
IRB Models: Edge Routing
The simplest way to implement layer-3 forwarding in a network fabric is to offload it to an external device1, be it a WAN edge router, a firewall, a load balancer, or any other network appliance.
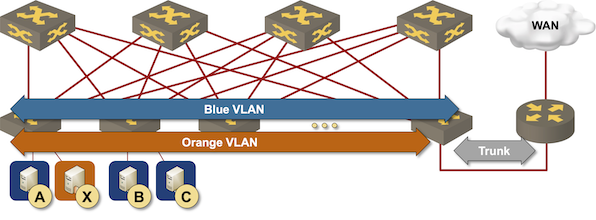
Routing at the (outer) edge of the fabric
Response: Complexities of Network Automation
David Gee couldn’t resist making a few choice comments after I asked for his opinion of an early draft of the Network Automation Expert Beginners blog post, and allowed me to share them with you. Enjoy 😉
Network automation offers promises of reliability and efficiency, but it came without a warning label and health warnings. We seem to be perpetually stuck in a window display with sexily dressed mannequins.