Blog Posts in November 2022
… updated on Thursday, December 1, 2022 16:30 UTC
ICMP Redirects and Suboptimal Routing
A while ago, I wrote a blog post explaining why we should (mostly) disable ICMP redirects, triggering a series of comments discussing the root cause of ICMP redirects. A few of those blamed static routes, including:
Put another way, the presence or absence of ICMP Redirects is a red herring, usually pointing to architectural/design issues instead. In this example, using vPC Peer Gateway or, better yet, running a minimal IGP instead of relying on static routes eliminates ICMP Redirects from both the problem and solution spaces simultaneously.
Unfortunately, that’s not the case. You can get suboptimal routing that sometimes triggers ICMP redirects in well-designed networks running more than one routing protocol.
Azure Networking Update Is Completed
I planned to write a few interesting blog posts last week, but then got sucked into updating Azure Networking webinar. At least I got that completed 😊; the webinar materials now include these new Azure services:
I also added descriptions of numerous new features:
netlab Release 1.4.1: Cisco ASAv
The star of the netlab release 1.4.1 is Cisco ASAv support: IPv4 and IPv6 addressing, IS-IS and BGP, and libvirt box building instructions.
Other new features include:
- VRRP on VyOS
- Anycast gateway and VRRP on Dell OS10 (with a bunch of caveats)
- Unnumbered OSPF interfaces on VyOS
- Support for all EVPN bundle services
- FRR version 8.4.0
Upgrading is as easy as ever: execute pip3 install --upgrade networklab.
New to netlab? Start with the Getting Started document and the installation guide.
Congestion Control Algorithms Are Not Fair
Creating a mathematical model of queuing in a distributed system is hard (Queuing Theory was one of the most challenging ipSpace.net webinars so far), and so instead of solutions based on control theory and mathematical models we often get what seems to be promising stuff.
Things that look intuitively promising aren’t always what we expect them to be, at least according to an MIT group that analyzed delay-bounding TCP congestion control algorithms (CCA) and found that most of them result in unfair distribution of bandwidth across parallel flows in scenarios that diverge from spherical cow in vacuum. Even worse, they claim that:
[…] Our paper provides a detailed model and rigorous proof that shows how all delay-bounding, delay-convergent CCAs must suffer from such problems.
It seems QoS will remain spaghetti-throwing black magic for a bit longer…
Worth Reading: Troubleshooting EVPN Control Plane
When trying to decide whether to use EVPN for your next data center fabric, you might want to consider how easy it is to configure and troubleshoot.
You’ll find a few configuration hints in the Multivendor Data Center EVPN part of the EVPN Technical Deep Dive webinar. For the troubleshooting part, check out the phenomenal Troubleshooting EVPN with Arista EOS article by Tony Bourke.
Video: Cloud Infrastructure-as-Code
With AWS re:Invent 2022 being just a few days away, it’s time for another cloudy Friday video: using infrastructure-as-code principles to provision public cloud resources by Matthias Luft (part of Introduction to Cloud Computing webinar).
Azure Networking Update (Phase 1)
Last week I completed the first part of the annual Azure Networking update. The Azure Firewall section is already online; hope you’ll find it useful. I already have the materials for the Private Link and Gateway Load Balancer services, but haven’t decided whether to schedule another live session to cover them, or just create a short video.
Then there are a half-dozen smaller things I found while processing a year worth of Azure networking News. You’ll find them (and links to documentation) in New Azure Services and Features document.
Integrated Routing and Bridging (IRB) Design Models
Imagine you built a layer-2 fabric with tons of VLANs stretched all over the place. Now the users want to exchange traffic between those VLANs, and the obvious question is: which devices should do layer-2 forwarding (bridging) and which ones should do layer-3 forwarding (routing)?
There are four typical designs you can use to solve that challenge:
- Exchange traffic between VLANs outside of the fabric (edge routing)
- Route on core switches (centralized routing)
- Route on ingress (asymmetric IRB)
- Route on ingress and egress (symmetric IRB)
This blog post is an overview of the design models; we’ll cover each design in a separate blog post.
Network Automation: a Service Provider Perspective
Antti Ristimäki left an interesting comment on Network Automation Considered Harmful blog post detailing why it’s suboptimal to run manually-configured modern service provider network.
I really don’t see how a network any larger and more complex than a small and simple enterprise or campus network can be developed and engineered in a consistent manner without full automation. At least routing intensive networks might have very complex configurations related to e.g. routing policies and it would be next to impossible to configure them manually, at least without errors and in a consistent way.
netlab: IRB with Anycast Gateways
netlab release 1.4 added support for static anycast gateways and VRRP. Today we’ll use that functionality to add anycast gateways to the VLAN trunk lab:
Lab topology
We’ll start with the VLAN trunk lab topology and make the following changes:
Worth Reading: Resolverless DNS
Geoff Huston published a lengthy article (as always) describing talks from recent OARC meeting, including resolver-less DNS and DNSSEC deployment risks.
Definitely worth reading if you’re at least vaguely interested in the technology that supposedly causes all network-related outages (unless it’s BGP, of course)
Worth Reading: Another Hugo-Based Blog
Bruno Wollmann migrated his blog post to Hugo/GitHub/CloudFlare (the exact toolchain I’m using for one of my personal web sites) and described his choices and improved user- and author experience.
As I keep telling you, always make sure you own your content. There’s absolutely no reason to publish stuff you spent hours researching and creating on legacy platforms like WordPress, third-party walled gardens like LinkedIn, or “free services” obsessed with gathering visitors’ personal data like Medium.
Video: Exposing Kubernetes Services to External Clients
After a brief introduction of Kubernetes service and an overview of services types, Stuart Charlton added the last missing bit: how do you expose Kubernetes services to external clients.
Multihoming Cannot Be Solved within a Network
Henk made an interesting comment that finally triggered me to organize my thoughts about network-level host multihoming1:
The problems I see with routing are: [hard stuff], host multihoming, [even more hard stuff]. To solve some of those, we should have true identifier/locator separation. Not an after-thought like LISP, but something built into the layer-3 addressing architecture.
Proponents of various clean-slate (RINA) and pimp-my-Internet (LISP) approaches are quick to point out how their solution solves multihoming. I might be missing something, but it seems like that problem cannot be solved within the network.
BGP in ipSpace.net Design Clinic
The ipSpace.net Design Clinic has been running for a bit over than a year. We covered tons of interesting technologies and design challenges, resulting in over 13 hours of content (so far), including several BGP-related discussions:
- BGP route servers
- Redundant BGP-Based Internet Access
- Secure BGP Configuration on Customer Routers
- Enterprise WAN Routing Design
All the Design Clinic discussions are available with Standard or Expert ipSpace.net Subscription, and anyone can submit new design/discussion challenges.
BGP Unnumbered Duct Tape
Every time I mention unnumbered BGP sessions in a webinar, someone inevitably asks “and how exactly does that work?” I always replied “gee, that’s a blog post I should write one of these days,” and although some readers might find it long overdue, here it is ;)
We’ll work with a simple two-router lab with two parallel unnumbered links between them. Both devices will be running Cumulus VX 4.4.0 (FRR 8.4.0 container generates almost identical printouts).
netlab VXLAN Router-on-a-Stick Example
In October 2022 I described how you could build a VLAN router-on-a-stick topology with netlab. With the new features added in netlab release 1.41 we can do the same for VXLAN-enabled VLANs – we’ll build a lab where a router-on-a-stick will do VXLAN-to-VXLAN routing.
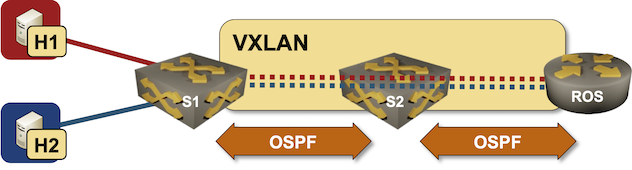
Lab topology
Worth Reading: History of Fiber Optics Cables
Geoff Huston published a fantastic history of fiber optics cables, from the first (copper) transatlantic cable to 2.2Tbps coherent optics. Have fun!
Video: Routing Protocols Overview
After discussing network addressing and switching, routing, and bridging in the How Networks Really Work webinar, it was high time for a deep dive into routing protocols, starting (as always) with an overview.
BGP Route Reflectors in the Forwarding Path
Bela Varkonyi left two intriguing comments on my Leave BGP Next Hops Unchanged on Reflected Routes blog post. Let’s start with:
The original RR design has a lot of limitations. For usual enterprise networks I always suggested to follow the topology with RRs (every interim node is an RR), since this would become the most robust configuration where a link failure would have the less impact.
He’s talking about the extreme case of hierarchical route reflectors, a concept I first encountered when designing a large service provider network. Here’s a simplified conceptual diagram (lines between boxes are physical links as well as IBGP sessions between loopback interfaces):
… updated on Thursday, November 10, 2022 07:58 UTC
Using EVPN/VXLAN with MLAG Clusters
There’s no better way to start this blog post than with a widespread myth: we don’t need MLAG now that most vendors have implemented EVPN multihoming.
TL&DR: This myth is close to the not even wrong category.
As we discussed in the MLAG System Overview blog post, every MLAG implementation needs at least three functional components:
SRv6 as a Host-to-Host Overlay
During the discussion of the On Applicability of MPLS Segment Routing (SR-MPLS) blog post on LinkedIn someone made an off-the-cuff remark that…
SRv6 as an host2host overlay - in some cases not a bad idea
It’s probably just my myopic view, but I fail to see the above idea as anything else but another tiny chapter in the “Solution in Search of a Problem” SRv6 saga1.
netlab Release 1.4.0: EVPN Asymmetric IRB, Anycast Gateways, VRRP
The big three features of the netlab release 1.4.0 are:
- EVPN asymmetric IRB on Arista EOS, Cumulus Linux, Dell OS10, Nokia SR Linux, Nokia SR OS and VyOS
- Anycast gateway on Arista EOS, Cumulus Linux, Nokia SR OS and Nokia SR Linux
- VRRP on Arista EOS, Cisco IOSv/CSR, Cisco Nexus OS, Cumulus Linux and Nokia SR OS
We also added tons of new functionality, including:
Must Read: Routing Will Never Be a Solved Problem
Mark Seery wrote a fantastic must-read article explaining why routing will never be a solved problem.
You might want to enjoy it as a relaxing antidote after a painful exposure to SD-WAN (or SD-something-else) brainwashing.
Video: EVPN Multihoming Deep Dive
After starting the EVPN multihoming versus MLAG presentation (part of EVPN Deep Dive webinar) with the taxonomy of EVPN-based multihoming, Lukas Krattiger did a deep dive into its intricacies including:
- EVPN route types needed to support multihoming
- A typical sequence of EVPN updates during multihoming setup
- MAC multipathing, MAC aliasing, split horizon and mass withdrawals
- Designated forwarder election
Rant: Cloudy Snowflakes
I could spend days writing riffs on some of the more creative (in whatever dimension) comments left on my blog post or LinkedIn1. Here’s one about uselessness of network automation in cloud infrastructure (take that, AWS!):
If the problem is well known you can apply rules to it (automation). The problem with networking is that it results in a huge number of cases that are not known in advance. And I don’t mean only the stuff you add/remove to fix operational problems. A friend in one of the biggest private clouds was saying that more than 50% of transport services are customized (a static route here, a PBR there etc) or require customization during their lifecycle (e.g. add/remove a knob). Telcos are “worse” and for good reasons.
Yeah, I’ve seen such environments. I had discussions with a wide plethora of people building private and public (telco) clouds, and summarized the few things I learned (not many of them good) in Address the Business Challenges First part of the Business Aspects of Networking Technologies webinar.
… updated on Thursday, November 3, 2022 09:35 UTC
Scalability Aspects of SR-MPLS
Henk Smit left a wonderful comment discussing various scalability aspects of SR-MPLS. Let’s go through the points he made:
When you have a thousand routers in your networks, you can put all of them in one (IS-IS) area. Maybe with 2k routers as well. But when you have several thousand routers, you want to use areas, if only to limit the blast-radius.
Absolutely agree, and as RFC 3439 explained in more eloquent terms than I ever could: