EVPN/VXLAN or Bridged Data Center Fabric?
An attendee in the Building Next-Generation Data Center online course sent me an interesting dilemma:
Some customers don’t like EVPN because of complexity (it is required knowledge BGP, symmetric/asymmetric IRB, ARP suppression, VRF, RT/RD, etc). They agree, that EVPN gives more stability and broadcast traffic optimization, but still, it will not save DC from broadcast storms, because protections methods are the same for both solutions (minimize L2 segments, storm-control).
We’ll deal with the unnecessary EVPN-induced complexity some other time, today let’s start with a few intro-level details.
The ancient way of building data center fabrics was to deploy MLAG clusters at the leaf- and the spine layer, pretending the spine layer is a single “node”, and running STP to prevent any potential forwarding loops. Core convergence relied on LACP, UDLD, and STP.
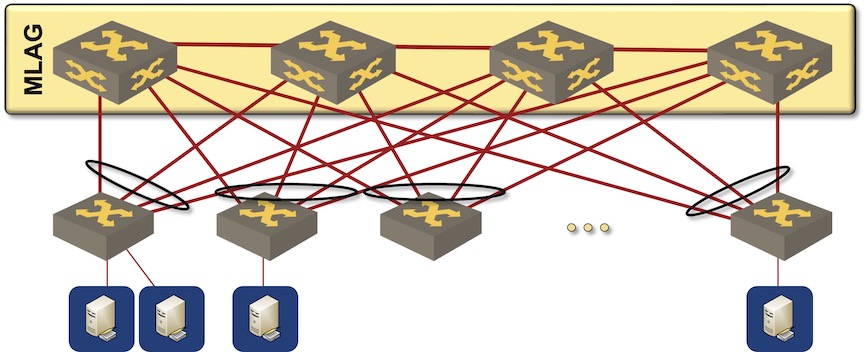
Traditional MLAG-based bridged fabric
The currently-hip data center fabric design1 starts with an IP network, adds VXLAN transport on top of that, and uses EVPN as the control plane2. Core convergence relies on BFD, IP routing protocols and Fast Reroute (if needed).
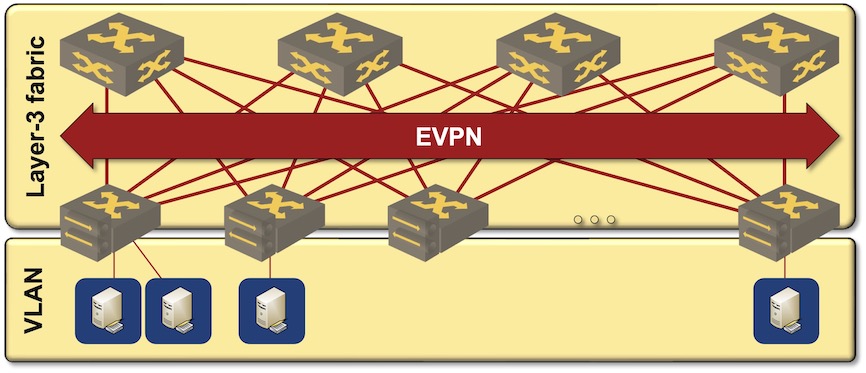
EVPN/VXLAN-based data center fabric
Before digging into the details, it’s worth noting that it’s perfectly possible to build VXLAN-based fabrics without EVPN and the associated complexity. All you have to do is to configure static ingress replication lists, trading protocol complexity for configuration complexity.
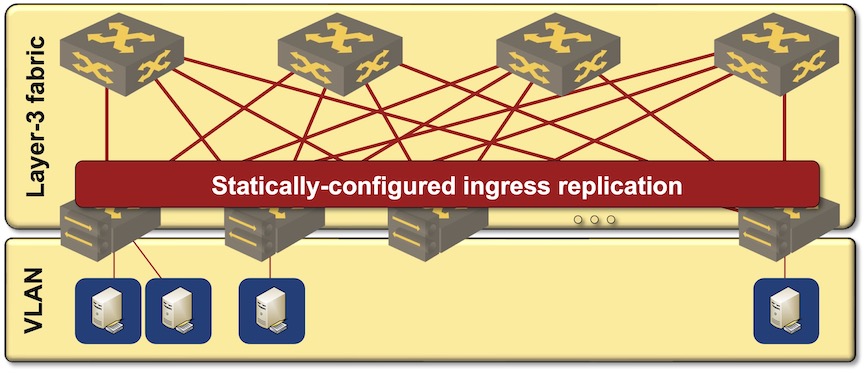
VXLAN-based data center fabric with static ingress replication
I’m not saying that’s the recommended way of doing things, but it’s a viable option usually not mentioned by the networking vendors3. Just keep in mind that EVPN and associated complexity is not a mandatory bit of VXLAN-based fabrics.
Which Design Should I Use?
I wouldn’t think about building bridged fabric in 2022. MLAG remains a kludge4 and I’ve seen too many data center meltdowns caused by MLAG bugs.
Furthermore, building a bridged fabric forces you to use MLAG on the spine layer (where bugs matter most), even if the end-hosts don’t need link aggregation – a highly debatable topic we covered in the December 2021 session of the Design Clinic.
Without going into the details: you MIGHT need link aggregation on storage nodes and you PROBABLY SHOULD NOT use link aggregation on hypervisor hosts like VMware ESXi. Should you agree with this best practice5 you could build a VXLAN-based fabric without ever opening the Pandora box of MLAG complexity.
For more details, watch the Leaf-and-Spine Fabric Architectures and EVPN Technical Deep Dive webinars.
Want to kick the tires of the EVPN/VXLAN “beauty”? netlab release 1.3 added VXLAN and EVPN support for a half-dozen platforms.
-
Now that all vendors apart from a few SPBM stalwarts abandoned routed layer-2 fabrics. ↩︎
-
For extra-hipness, replace OSPF with EBGP and run IBGP EVPN sessions on top of EBGP-only underlay because you REALLY SHOULD design your 4-node network in the same way hyperscalers build their data centers. ↩︎
-
Vendors can’t resist the urge to brag about the most-complex-possible design after investing so much into implementing a complex control plane protocol. Nobody wants you to use a simple setup that could be easily replicated on more affordable gear the next time you’re upgrading your hardware. ↩︎
-
So does bridging, but let’s not go there ↩︎
-
Best practice: a procedure that will cause the least harm (as compared to random ramblings and cut-and-paste of Google-delivered configuration snippets) when executed by people who don’t know what they’re doing. ↩︎
The tradeoff is that bridging is simple and low cost. You can build access sites (smallish metro or RAN rings) with low cost and minimal integration efforts. It may be "ancient" and spanning tree may be an anathema but not everything is servers connected single hop to a L3 domain with the luxury of direct multi-homing links. And from what i hear we are still discussing spanning tree on EVPN/VXLAN access, there must be a good reason :)
...you can ignore just realized the context was DC :)
Interesting article Ivan. Another major problem I see for EPVN, is the incompatibility between vendors, even though it is an open standard. With today’s crazy switch delivery times, we want a multi-vendor solution like BGP or LACP, but EVPN (due to vendors) isn’t ready for a multi-vendor production network fabric.
Another issue with EVPN is cost in terms of price and project (delivery times). To have a robust & stable solution you should start with Trident III as if you go with Tomahawk I you will need re-circulation… (I would suggest avoiding that…) and with Trident II+ you lack 100Gbps and 25Gbps… which it is the standard today. There are not many Trident III switches today in the secondhand market and a new one would take 1 year to be delivered. Without EVPN, you could obtain a Tomahawk switch for half the price and even lower latency if that nanosec difference really matters to you.
Another problem, that vendors have been solving lately with ranges, was the kilometer long configuration in EVPN and uniqueness with the rd for each vni per switch, making the list of config even longer than in HER.
And all these without mentioning the bugs that each vendor has when using EVPN on their switches…. Making it an unstable feature to turn on today. In the other hand, EVPN Multi-homing, on paper, solve lots of issues
But! How would you manage to build a vendor-agnostic data-center fabric using MLAG?
The same way you'd build a vendor-agnostic data-center fabric using EVPN: you wouldn't. There are enough tiny discrepancies to make you go crazy (or buy Apstra's software) in particular if you have to support hosts LAG-attached to multiple switches (which is MLAG regardless of how it's implemented).
[disclaimer, some vendor bias may apply]
Interesting article, but one of the things I'd like to point out is that your MLAG domain stretches across 4 nodes. All implementations of MLAG or comparable technologies that I am aware of scale up to two nodes. This means that your spine will have at most 2* the amount of ports available on the devices that get chosen to act as spine. In addition to that, most MLAG implementations don't allow (or at least support, as in tested) mixing and matching different types of hardware, so migration will be a major pain.
This means that for DC designs that require a bigger physical footprint than 2 devices, to have all-links active, you pretty much end up in a L3 design. We then tend to slap VXLAN (with or without EVPN) on top because a lot of applications still require that dreaded L2 connectivity, or we want EVPN goodies like multi-tenancy in the DC.
PS - even then, MLAG is still being used in a lot of these designs because while EVPN multi-homing is great on paper, it also comes with some drawbacks, especially when looking at the amount of control-plane overhead it generates.
> ... one of the things I'd like to point out is that your MLAG domain stretches across 4 nodes. All implementations of MLAG or comparable technologies that I am aware of scale up to two nodes.
That's on purpose -- it triggers critical thinking ;)
The only exceptions to "2 node MLAG" rule that I'm aware of were HP IRF, Juniper Virtual Chassis (Fabric), and Brocade VCS Fabric. Most of them are probably obsolete by now, and all of them could not run four chassis switches in a cluster.
I think in an MLAG setup Arista is limited to two nodes, too. The only way to circumvent this limitation is to use BGP EVPN multihoming, which again is not MLAG...
Ah... didn't read well. Sorry.