MLAG Deep Dive: Dynamic MAC Learning
In the first blog post of the MLAG Technology Deep Dive series, we explored the components of an MLAG system and the fundamental control plane requirements.
This post focuses on a major building block of the layer-2 data plane functionality: MAC learning. We’ll keep using the same network topology with two switches and five hosts, and assume our system tries its best to implement hot-potato switching (sending the frames toward the destination MAC address on the shortest possible path).
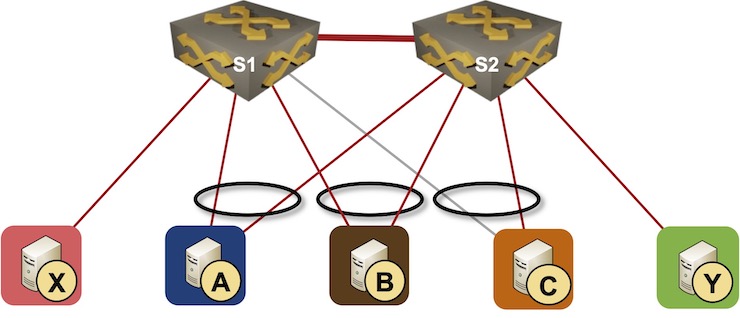
Simple MLAG topology
Imagine A sending frames to X over the A-S2 link1. S2 forwards (or floods) those frames over the S2-S1 link. Using the traditional MAC address learning, S1 would deduce that it should use the S1-S2 link for the return traffic toward A, violating the hot-potato switching expectation.
Conclusion: Switches in an MLAG cluster should not rely exclusively on dynamic MAC learning. They need a control-plane protocol to exchange MAC addresses reachable over the LAG member links. It’s worth noting that ICCP (RFC 7275) does not provide this functionality; to build a standards-based MLAG solution, you have to combine ICCP with another control-plane protocol like EVPN.
Can we combine dynamic MAC learning on the S1-S2 link with a control-plane protocol? It’s a tough challenge. Imagine A using both LAG members to send traffic to X; S1 would see source MAC address A coming from the directly-connected link and the S1-S2 link. Traditional MAC learning behavior would quickly trigger duplicate MAC address alerts; clearly not something we want to see.
You can solve this conundrum in several ways, depending on what the underlying hardware supports2:
- Implement an address source priority scheme – MAC addresses advertised by the control plane cannot be changed through dynamic MAC learning.
- MLAG implementations using a peer link usually use proprietary encapsulation on the peer link3. The switch could use the “this frame is coming from a LAG member” part of that encapsulation to influence dynamic MAC learning.
- It might be easiest to give up, disable dynamic MAC learning on the peer link, and use a control-plane MAC address advertisement protocol between MLAG cluster members.
I’m positive we can find implementations of all three ideas in the wild; if you know how a particular MLAG implementation works, please leave a comment.
Next: Layer-2 Flooding Continue
-
A considers the links to S1 and S2 members of the same link aggregation group and thus equally suited for frame forwarding. It has no idea that it’s faster to reach X over the A-S1 link. ↩︎
-
Assuming the underlying hardware is powerful enough to implement dynamic MAC learning. You can use whatever scheme you like if the hardware punts all frames with unknown source MAC addresses or MAC addresses coming from unexpected ports to the CPU… just be careful that the punted frames caused by the same MAC address coming from a LAG member and peer link won’t overload the CPU. ↩︎
-
More details when we get to layer-2 flooding. ↩︎