Mixed Feelings about BGP Route Reflector Cluster ID
Here’s another BGP Route Reflector myth:
In a redundant design, you should use Route Reflector Cluster ID to avoid loops.
TL&DR: No.
While BGP route reflectors can cause permanent forwarding loops in sufficiently broken topologies, the Cluster ID was never needed to stop a routing update propagation loop:
- The only way to generate an update propagation loop is a cycle of route reflectors with every route reflector being a client of other route reflectors1
- Even in that case, every RR adds its cluster ID (router ID is used as the default value) to the cluster list attribute on every reflected BGP prefix, and checks the cluster list on incoming updates.
Long story short: cluster list serves the same role within an autonomous system as AS path does across autonomous systems (without the plethora of nerd knobs that would allow you to turn off sanity checks).
OK, so it looks like we don’t need to set cluster id on route reflectors – the update loops are detected in any case and life is good. As always things aren’t as simple as they look; it’s time for an analogy: if you squint just right, an autonomous system with a set of route reflectors and clients looks an awful lot like a leaf-and-spine fabric (route reflectors are spines, RR clients are leafs).
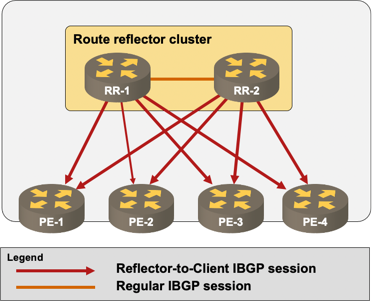
A network with a single layer of BGP route reflectors
In an EBGP leaf-and-spine fabric we commonly use the same AS number on all spines to prevent path hunting. Using the analogy, it seems that we should use the same cluster ID on all route reflectors. Fortunately, route reflector path hunting isn’t nearly as bad as EBGP path hunting.
Never heard of path hunting? Let’s see what’s going on behind the scenes, using the simplest possible lab topology:
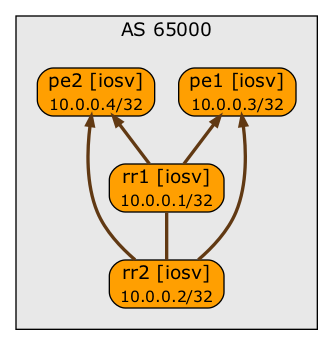
BGP sessions in our sample lab (Graphviz hates drawing a leaf-and-spine fabric)
Without Route Reflector Cluster ID
Without BGP Route Reflector Cluster ID configured on RR1 and RR2, the following updates are sent when PE1 advertises its loopback:
- PE1 sends an update to RR1 and RR2
- RR1 and RR2 reflect the updates to each other, PE2, and PE12
- PE1 ignores the received update because it’s router ID matches the originator attribute.
- PE2 installs both updates in BGP RIB and selects one of them as the best route.
- RR1 and RR2 install the reflected update from the other route reflector in BGP RIB and ignore it because it’s not the best route (due to cluster list length).
rr1#sh ip bgp 10.0.0.3
BGP routing table entry for 10.0.0.3/32, version 9
Paths: (2 available, best #2, table default, RIB-failure(17))
Advertised to update-groups:
1 2
Refresh Epoch 1
Local
10.0.0.3 (metric 20) from 10.0.0.2 (10.0.0.2)
Origin IGP, metric 0, localpref 100, valid, internal
Originator: 10.0.0.3, Cluster list: 10.0.0.2
rx pathid: 0, tx pathid: 0
Refresh Epoch 2
Local, (Received from a RR-client)
10.0.0.3 (metric 20) from 10.0.0.3 (10.0.0.3)
Origin IGP, metric 0, localpref 100, valid, internal, best
rx pathid: 0, tx pathid: 0x0
When PE1 shuts down (simulated with no router bgp 65000 configuration command) it closes the BGP session with RR1 and RR2 (debugging printouts were collected on RR1):
%BGP-5-NBR_RESET: Neighbor 10.0.0.3 reset (Peer closed the session)
%BGP-5-ADJCHANGE: neighbor 10.0.0.3 Down Peer closed the session
%BGP_SESSION-5-ADJCHANGE: neighbor 10.0.0.3 IPv4 Unicast topology base removed from session
RR1 removes the original route from PE1 and finds an alternate route in BGP RIB – the reflected update received from RR2:
Revise route installing 1 of 1 routes for 10.0.0.3/32 -> 10.0.0.3(global) to main IP table
As RR1 is now using a route from RR2, it sends an unreachable update3 to RR2:
BGP(0): (base) 10.0.0.2 send unreachable (format) 10.0.0.3/32
It also sends a modified version of the 10.0.0.3/32 prefix (that we know is bogus, but RR1 doesn’t) to PE2:
BGP(0): (base) 10.0.0.4 send UPDATE (format) 10.0.0.3/32, next 10.0.0.3, metric 0, path Local
RR2 goes though the same steps and arrives at the same conclusions (including sending an unreachable update to RR1). Immediately after sending an update to PE2, RR1 receives an update from RR2 saying hey, I have no idea where 10.0.0.3 is:
BGP(0): 10.0.0.2 rcv UPDATE about 10.0.0.3/32 -- withdrawn
BGP(0): no valid path for 10.0.0.3/32
BGP: topo global:IPv4 Unicast:base Remove_fwdroute for 10.0.0.3/32
As the final step, RR1 has to send yet another update to PE2 saying gee, I was wrong – I have no idea where 10.0.0.3/32 is:
BGP(0): (base) 10.0.0.4 send unreachable (format) 10.0.0.3/32
The Impact of BGP Route Reflector Cluster ID
With the same RR Cluster ID configured on RR1 and RR2, RR1 rejects a reflected update coming from RR2:
BGP: 10.0.0.2 RR in same cluster. Reflected update dropped
BGP(0): 10.0.0.2 rcv UPDATE w/ attr: nexthop 10.0.0.3, origin i, localpref 100,
metric 0, originator 10.0.0.3, clusterlist 10.0.0.1...
BGP(0): 10.0.0.2 rcv UPDATE about 10.0.0.3/32 -- DENIED due to: reflected from the same cluster;
There’s also no path hunting after the session with PE1 fails. RR1 has no alternate path in its BGP RIB and immediately sends an unreachable update to PE2:
%BGP-5-NBR_RESET: Neighbor 10.0.0.3 reset (Peer closed the session)
BGP(0): no valid path for 10.0.0.3/32
BGP(0): (base) 10.0.0.2 send unreachable (format) 10.0.0.3/32
BGP(0): (base) 10.0.0.4 send unreachable (format) 10.0.0.3/32
To Cluster or Not To Cluster?
Based on the above, it seems like we should be using cluster ID on route reflectors to reduce the amount of BGP updates. On the other hand, similar to removing IBGP session between route reflectors, setting the cluster ID on route reflectors reduces the resilience of the design – a misbehaving BGP session combined with a route reflector crash (or two lost BGP sessions) could result in connectivity loss similar to the impact of valley-free routing.
The decision becomes simpler if you use more than two route reflectors4:
- The probability of connectivity loss is significantly lower – you’d need more than two strategically placed failures to get there;
- The BGP update traffic goes through the roof, particularly if you set IBGP update timers to zero to speed up the convergence5.
As always, you have to identify the tradeoffs (BGP update traffic versus resiliency) and choose the design that fits your requirements – the state that’s best summarized with It Depends™
-
The proof is left as an exercise for the reader. ↩︎
-
PE1 and PE2 are in the same BGP update group. PE1 thus receives a reflected update of its own announcement. ↩︎
-
Technically, a WITHDRAW BGP message ↩︎
-
There’s usually no need to do that, but bear with me ↩︎
-
Another exercise for an interested reader ↩︎
What is your feeling about using multiple cluster IDs per route reflector?
This can be used to assign unique cluster-ID is per RR client (neighbor a.b.c.d cluster-id w.x.y.z ) or set of clients which have iBGP mesh between each other. For example two co-located PE routers have iBGP with each other and the RRs. The RR is then also configured not to reflect to clients with the same cluster ID. (no bgp client-to-client reflection intra-cluster cluster-id any). Reflection can also be disabled for a list of specific cluster-IDs.
I'm positive there's a use case for that and it's been around for a very long time -- no-client-to-client reflection nerd knob has been available on Cisco IOS for decades.
Not sure I want to know what it is though ;)
One concern is scale when using unique cluster-id per RR. Reflected routes from non-client east-west interRR sessions can quickly add to the rib scale on RRs. Scale can be tricky to handle as it directly affects route propagation delay in a hierarchical RR topology.