Graceful Restart (GR) 101
In the Non-Stop Forwarding (NSF) article, I mentioned that the routers adjacent to the device using NSF have to play along to make the idea work. That capability is called Graceful Restart. Today we’ll explore its intricate details, be diplomatic, and leave the shortcomings and tradeoffs for another blog post.
The Problem
Imagine an access (provider edge) router providing connectivity services to its clients and running a routing protocol with one or more upstream devices.
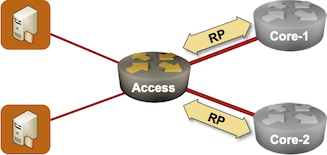
Non-redundant access network
When that router crashes, the control plane of adjacent devices discovers its failure (using BFD or routing protocol neighbor discovery mechanisms) and starts the failure recovery process. In a few moments, the adjacent devices adjust their routing and forwarding tables, wasting the non-stop forwarding capability of the crashed device.
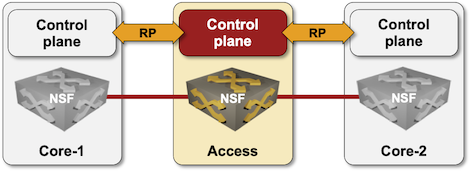
Control Plane failure in NSF-capable device
The conclusion: we need a mechanism to tell the devices adjacent to the NSF-capable devices to enhance their calm. Welcome to the Graceful Restart (GR) alternate reality.
Graceful Restart Basics
The basic ideas of graceful restart are relatively simple:
- Every Graceful Restart RFC specifies routing protocol behavior on two types of devices: the restarting device and the helper node1.
- The restarting device is an NSF-capable device undergoing a restart. The helper node does not have to support NSF; all it has to do is modify its routing protocol behavior.
- An NSF-capable device advertises that capability or its desire to undergo a Graceful Restart to its routing protocol neighbors2.
- Whenever the control plane of an NSF-capable device fails, the neighbors ignore the alerts triggered by BFD or lack of Hello messages and politely wait for the failed device to recover while pretending everything is OK3.
- After the failed device recovers, it uses modified routing protocol procedures to ensure its routing updates don’t disrupt the routing tables in the adjacent devices.
The Graceful Restart modifications made to the routing protocols differ significantly between link-state and distance-vector routing protocols – let’s look at BGP and OSPF as the typical representatives of each category.
OSPF Graceful Restart
The OSPF Graceful Restart (RFC 3623) specifies different behavior for planned and unplanned outages:
- When planning a restart, an NSF-capable device advertises Grace LSA – a link-local opaque LSA telling the neighbors to ignore its lack of responsiveness for a specific time (timeout is specified in the opaque LSA content).
- After receiving the Grace LSA, the helper nodes (adjacent OSPF routers) pretend the restarting router is still operational even though the OSPF hello protocol would have declared it dead.
- The restarting router goes through the regular OSPF adjacency establishment procedure, including OSPF database exchange.
- The Graceful Restart ends when the restarting router flushes the opaque LSA.
Following an unplanned outage, an NSF-capable device that wishes to use Graceful Restart sends the Grace LSA before it starts sending OSPF hello messages, effectively pretending that it’s undergoing a very short planned outage. Obviously, this trick works only when the device restart completes within the OSPF hello timeout window.
It’s worth noting that the authors of the OSPF Graceful Restart were relatively cautious. The moment there’s any relevant topology change in the OSPF network, all bets are off, and the helper node(s) terminate the graceful restart procedure:
- They stop pretending the restarting device is operational;
- They advertise the topology change by adjusting their Router (type-1) or Network (type-2) LSA.
BGP Graceful Restart
Compared to OSPF Graceful Restart, BGP Graceful Restart (RFC 4724) looks like it’s been designed by cowboys4:
- NSF-capable devices and GR-capable devices (potential helper nodes) advertise their capabilities in BGP OPEN messages.
- When an NSF-capable device fails (as discovered by BFD or BGP Hello timers), adjacent BGP speakers pretend it’s still there until the Graceful Restart timer expires. There is no differentiation between planned and unplanned outages and no provision for we’re leaving this charade if there’s been a topology change.
After a restarting device reestablishes its BGP adjacencies, it has to go through a slightly modified route exchange procedure:
- It’s accepting BGP updates from the helper nodes but is not sending any updates of its own until it receives the End-of-RIB marker from all helper nodes5.
- After the restarting device collects the BGP information from all adjacent devices, it selects the best BGP routes, populates routing and forwarding tables, and advertises its best routes to its neighbors. The Graceful Restart procedure is complete.
Figuring out the tiny details of what happens if there’s been a change in the network during the device restart is left as an exercise for an impatient reader; we’ll talk about it in an upcoming blog post.
-
OSPF terminology that’s commonly used in vendor documentation. BGP Graceful Restart RFC uses restarting speaker and receiving speaker terminology. ↩︎
-
BGP uses a new BGP capability to indicate the device supports Graceful Restart. OSPF uses an opaque LSA called Grace LSA. ↩︎
-
Graceful Restart implementations use a configurable timeout that stops the polite behavior and declares the disappeared device a confirmed failure. ↩︎
-
I’m positive they did their best working around BGP principles, but the end result is still less than spectacular. ↩︎
-
End-of-RIB marker is an empty BGP UPDATE message. The details are a bit more convoluted; see Section 2 of RFC 4724. ↩︎
Hmm, just recently we had a discussion about GR and BFD interoperability, and every single vendor (Cisco, Juniper, Palo Alto) document that I had found explicitly stated the same thing - those technologies did not work together and should not be enabled at the same time. Unless BFD timers are set to high values, obviously.
I agree, but do you have any reference ? this is something that's not well documented and I've been able to see it only on testing.
I have a blog post in the "to publish" queue describing the interaction between GR and BFD, and it's indeed an underdocumented confusing topic (to be diplomatic). Stay tuned...