Local TCP Anycast Is Really Hard
Pete Lumbis and Network Ninja mentioned an interesting Unequal-Cost Multipathing (UCMP) data center use case in their comments to my UCMP-related blog posts: anycast servers.
Here’s a typical scenario they mentioned: a bunch of servers, randomly connected to multiple leaf switches, is offering a service on the same IP address (that’s where anycast comes from).
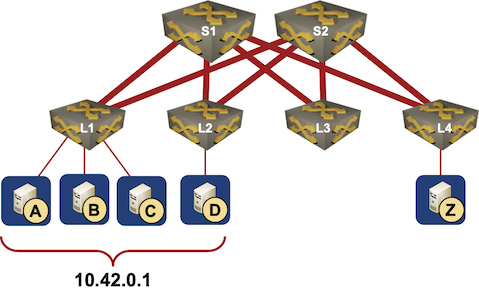
Typical Data Center Anycast Deployment
Before going into the details, let’s ask a simple question: Does that work outside of PowerPoint? Absolutely. It’s a perfect design for a scale-out UDP service like DNS, and large DNS server farms are usually built that way.
TCP Anycast Challenges
The really interesting question: Does it work for TCP services? Now we’re coming to the really hard part – as the spine and leaf switches do ECMP or UCMP toward the anycast IP address, someone must keep track of session-to-server assignments, or all hell would break loose.
It’s easy to figure out that the design works in a steady-state situation. Data center switches do 5-tuple load balancing; every session is thus consistently forwarded to one of the servers. Problem solved… until you get a link or node failure.
Dealing with Link- or Node Loss
Most production-grade hardware ECMP implementations use hash buckets (more details), and if the number of next hops changes due to a topology change, the hash buckets are reassigned, sending most of the traffic to a server that has no idea what to do with it. Modern ECMP implementations avoid that with consistent hashing. Consistent hashing tries to avoids recomputing the hash buckets after a topology change1:
- Hash buckets for valid next hops are not touched.
- Invalid hash buckets (due to invalid next hop) are reassigned to valid next hops.
Obviously we’ll get some misdirected traffic, but those sessions are hopelessly lost anyway – they were connected to a server that is no longer reachable.
Adding New Servers
The really fun part starts when you try to add a server. To do that, the last-hop switch has to take a few buckets from every valid next hop, and assign them to the new server. That’s really hard to do without disrupting something2. Even waiting for a bucket to get idle (the flowlet load balancing approach) doesn’t help – an idle bucket does not mean there’s no active TCP session using it.
Oh, and finally there’s ICMP: ICMP replies include the original TCP/UDP port numbers, but no hardware switch is able to dig that far into the packet, so the ICMP reply is usually sent to some random server that has no idea what to do with it. Welcome to PMTUD hell.
Making Local TCP Anycast Work
Does that mean that it’s impossible to do local TCP anycast load balancing? Of course not – every hyperscaler uses that trick to implement scale-out network load balancing. Microsoft engineers wrote about their solution in 2013, Fastly documented their solution in 20163, Google has Maglev, Facebook open-sourced Katran, we know AWS has Hyperplane, but all we got from re:Invent videos was it’s awesome magic. They provided a few more details during Networking @Scale 2018 conference, but it was still at Karman line level.
You could do something similar at a much smaller scale with a cluster of firewalls or load balancers (assuming your vendor manages to count beyond two active nodes), but the performance of network services clusters is usually far from linear – the more boxes you add to the cluster, the less performance you gain with each additional box – due to cluster-wide state maintenance.
There are at least some open-source software solutions out there that you can use to build large-scale anycast TCP services. If you don’t feel comfortable using the hot-off-the-press gizmos like XDP, there’s Demonware’s BalanceD using Linux IPVS.
On the more academic side, there’s Cheetah… and in a rosy future we might eventually get a pretty optimal solution resembling a session layer with Multipath TCP v1.
More to Explore
- Data Center Infrastructure for Networking Engineers webinar has a long load balancing section.
- I described Microsoft’s approach to scale-out load balancing and its implications in SDN Use Cases and in load balancing part of Microsoft Azure Networking webinar.
- The user-facing part of AWS load balancing is described in Amazon Web Services Networking webinar.
Revision History
- 2021-05-28
- Added links to Katran, Hyperplane, BalanceD, Cheetah, and Multipath TCP. Thanks a million to Hugo Slabbert, Scott O’Brien, Lincoln Dale, Minh Ha, and Olivier Bonaventure for sending me the relevant links.
-
Please note that this is a control-plane functionality where you can take all the time in the world to get it done, even more so if you’re able to precompute the backup next hops. ↩︎
-
And even harder if you want to solve it in hardware at terabit speeds ↩︎
-
Take your time and read the whole article. They went into intricate details I briefly touched upon in this blog post. ↩︎
Hi Ivan, as this is one of my fav topis, I couldn't not leave a comment. AFAIK, what networking vendors use is normally called "resilient hashing". I've no PhD in this area but it looks like consistent hashing is much more advanced and is still an active area of research (see https://medium.com/@dgryski/consistent-hashing-algorithmic-tradeoffs-ef6b8e2fcae8). My very simplified understanding is that resilient hashing is a similar idea but due to a small number of buckets and limited TCAM space cannot satisfy all of the properties of a consistent hashing algorithm.
> Is there an easy-to-deploy software solution out there that would allow you to build large-scale anycast TCP services If we assume that "large-scale" and "easy" are not mutually exclusive, I believe there is. Due to how networking is implemented inside Kubernetes, you always get two layers of load-balancers (similar to cloud-scalers) with the first layer doing some form of consistent hashing and second layer doing the standard L7 LB (ingress). One prime example is Cilium https://cilium.io/blog/2020/11/10/cilium-19#maglev and although I don't have the exact numbers, I believe they test their releases against some pretty large number of nodes.
To add to my first comment, I have once tried to implement maglev-style load-balancing on an Arista switch. I used ECMP to spread the flows over multiple buckets and openflow agent to catch the first packet and install openflow (directflow) entries with timeouts (implementing the connection tracking part of maglev). This worked perfectly fine, I was able to add and remove anycast destinations without disrupting the existing traffic flows and it even survived the leaf switch outage (the second leaf in a pair would hash the flows in the same way).
My dreams got shattered when I realised that the maximum number of directflow entries supported was limited to 1-2k and, since I was installing exact match entries, this would not usable in real life.
Similar to Michael's comment and re: the Cilium bits, we also drop an L4 IPVS layer in front of our k8s services that need access from outside a cluster. https://github.com/Demonware/balanced
A BGP speaker on the IPVS nodes anycast the VIP to the network. IPVS has a consistent hashing algo (HRW / rendezvous hash). That way you don't depend on the network fabric to do any type of resilient hashing; you have a thin L4 software LB handle you resilience. This is done without coordination between the IPVS nodes (no flow state sync).
With a consistent hash like that, you can still be susceptible to a partial rehash on backend add/drop, e.g. if you have 9 existing backends and add a tenth, then 1/10 of the connections from the existing backends will now hash to the new backend. However, IPVS does carry a tiny little bit of state in each node to also effectively implement resilient hashing to tolerate backend change. If you have a backend add/drop, if your flow is still traversing the same IPVS node then it will continue to forward your traffic to the same backend.
If you hit a backend scale up/down or failure, and you have an ECMP rehash to land on a different IPVS node, and you've maintained a long-lived TCP connection through both of those events, then you might have impact to your connection if you are one of the subset of flows that got rehashed on the backend change (e.g. that 1/10 bit noted above).
In practice, meeting all of those conditions is rare enough, and the efforts needed to mitigate for that as well (e.g. adding another indirection layer to punt to the previous host like Fastly implemented), that for our use case this type of setup is sufficient.
@Michael: The OMG, there are so few flow entries realization is why I made so much fun of solving global load balancing with OpenFlow stupidity that was propagated as the highest achievement of mankind when OpenFlow was still young.
On a more serious note, there are cases where you have few long-lived sessions, and hardware per-flow load balancing makes perfect sense. IIRC there was a startup using an Arista switch with DirectFlow to implement scale-out iSCSI cluster. Every host would connect to the same target, and the TCP session would be redirected to one of the (anycast) cluster members.
@Hugo: Thanks a million for the pointer and the background info... and I agree, the edge cases are probably not worth worrying about in the HTTP world.
Re the IPVS convo. Might also be worth checking out Katran: https://engineering.fb.com/2018/05/22/open-source/open-sourcing-katran-a-scalable-network-load-balancer/
Some time ago I came up with the idea of LS-TCP - Label-switched TCP, see https://patents.justia.com/patent/20170149935. It basically inserts the ID of the selected server into every TCP packet.
At the time I created a Linux kernel patch for the server side (3.3.8 in 2013), but nowadays one could probably use EBPF to get similar results.
See https://youtu.be/rHavko3qXHs for a video demo - at 1:57 I stop the load balancer program, and restart it - that works because it is stateless
Hi Ivan, there's also this software load balancer called Cheetah, available in both stateless and stateful forms, that guarantees per-connection resiliency without using consistent hashing:
https://www.usenix.org/system/files/nsdi20-paper-barbette.pdf
Source code is available on GitHub (ref 4) for people who want to look into the details of the implementation. The short version: it encodes a piece of info and puts it into the header of packets and use mapping tables similar to (but not the same as) those of Fastly design, to achieve consistency and speed. Cheetah can be used on both software and hardware LB implementations.
Multipath TCP version 1 includes support for this use case. All servers have two addresses : - the anycast one used to send the initial SYN - a unique unicast one
The client connects to the server using the anycast address, the server advertises its unique address and then the client can create additional subflows to the server using this additional address. Multipath TCP version 1 includes one bit in the MP_CAPABLE option to indicate that the client cannot create subflows towards the anycast address.
This idea was evaluated in https://inl.info.ucl.ac.be/publications/making-multipath-tcp-friendlier-load-balancers-and-anycast.html
Multipath TCP version 1 is defined in https://datatracker.ietf.org/doc/rfc8684/
The support for this feature in the Linux kernel is still work in progress but could appear in the coming months, check https://github.com/multipath-tcp/mptcp_net-next/wiki
The Katran, Cilium / eBPF, and MTCP options are all intriguing ones for sure. Lots more options becoming available. I need to dig into the multipath TCP options a bit more, but I'm still stuck at the moment on thinking that for public VIPs with lots of backends it's feasible for IPv6 but starts to become untenable in terms of public address requirements for IPv4. But perhaps there you'd shove a 4to6 translation or just straight TCP reverse proxy layer in there somewhere.
> It’s almost impossible to get into the situation where you’d have equal-cost paths to two different sites anywhere in the Internet.
I have to disagree with that statement. ECMP is heavily used within ISP networks. And if the ISPs network is built in a symmetric way with two peering points to another ISP having the same IGP distance (from the user location) it would do ECMP to two different sites. Any that is perfectly fine from a network design perspective.
Anycast TCP is even less controllable on the public internet than it is in a datacenter. In the end, anycast is not load balancing. ECMP can of course be used for TCP traffic. But only to get the traffic into a set of load balancers (like Maglev, Katran, etc).
@takt: I know that ISPs use ECMP internally. That was not the point.
If I'm a content provider using anycast, I'd advertise the same prefix from multiple sites (probably not close together for resiliency reasons), commonly over multiple ISPs or at multiple IXPs. Unless you're heavily tweaking BGP path selection rules, it would be hard to get ECMP under those assumptions.
In practice, anycast TCP works well in the global Internet... at least for minor players like CloudFlare, LinkedIn, or AWS ;)